通过5个例子让你学会Pandas中的字符串过滤
要处理文本数据,需要比数字类型的数据更多的清理步骤。为了从文本数据中提取有用和信息,通常需要执行几个预处理和过滤步骤。
Pandas 库有许多可以轻松简单地处理文本数据函数和方法。在本文中,我介绍将学习 5 种可用于过滤文本数据(即字符串)的不同方法:
- 是否包含一系列字符
- 求字符串的长度
- 判断以特定的字符序列开始或结束
- 判断字符为数字或字母数字
- 查找特定字符序列的出现次数
首先我们导入库和数据
import pandas as pd
df = pd.read_csv("example.csv")
df
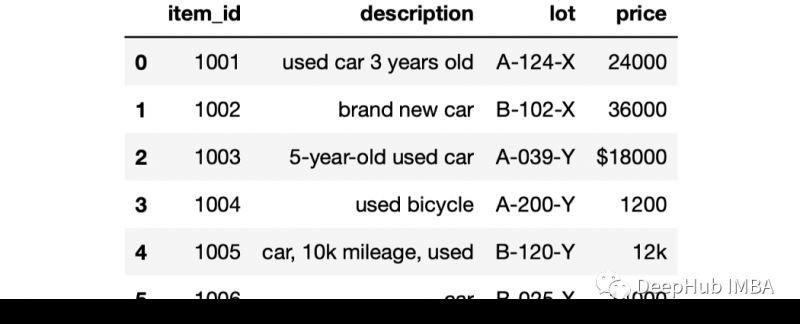
我们这个样例的DataFrame 包含 6 行和 4 列。我们将使用不同的方法来处理 DataFrame 中的行。第一个过滤操作是检查字符串是否包含特定的单词或字符序列,使用 contains 方法查找描述字段包含“used car”的行。但是要获得pandas中的字符串需要通过 Pandas 的 str 访问器,代码如下:
df[df["description"].str.contains("used car")]

但是为了在这个DataFrame中找到所有的二手车,我们需要分别查找“used”和“car”这两个词,因为这两个词可能同时出现,但是并不是连接在一起的:
df[df["description"].str.contains("used") &
df["description"].str.contains("car")]
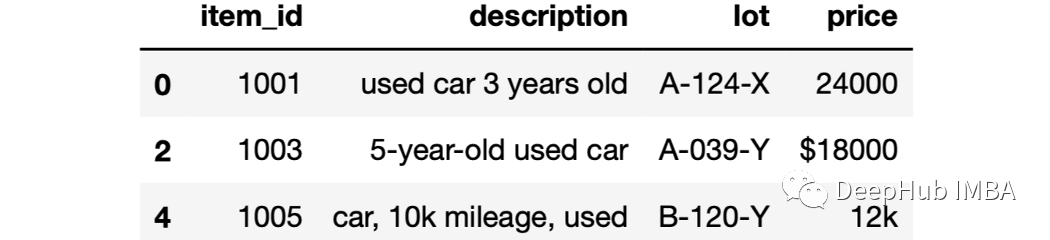
可以看到最后一行包含“car”和“used”,但不是一起。
下一个方法是根据字符串的长度进行过滤。假设我们只对超过 15 个字符的描述感兴趣。可以使用内置的 len 函数来执行此操作,如下所示:
df[df["description"].apply(lambda x: len(x) > 15)]
这里就需要编写了一个 lambda 表达式,通过在表达式中使用 len 函数获取长度并使用apply函数将其应用到每一行。执行此操作的更常用和有效的方法是通过 str 访问器来进行:
df[df["description"].str.len() > 15]

我们可以分别使用startswith和endswith基于字符串的第一个或最后一个字母进行过滤。
df[df["lot"].str.startswith("A")]

这个方法也能够检查前 n 个字符。例如,我们可以选择以“A-0”开头的行:
df[df["lot"].str.startswith("A-0")]

Python 的内置的字符串函数都可以应用到Pandas DataFrames 中。例如,在价格列中,有一些非数字字符,如 $ 和 k。我们可以使用 isnumeric 函数过滤掉。
df[df["price"].apply(lambda x: x.isnumeric()==True)]

同样如果需要保留字母数字(即只有字母和数字),可以使用 isalphanum 函数,用法与上面相同。
count 方法可以计算单个字符或字符序列的出现次数。例如,查找一个单词或字符出现的次数。
我们这里统计描述栏中的“used”的出现次数:
df["description"].str.count("used")
# 结果
0 1
1 0
2 1
3 1
4 1
5 0
Name: description, dtype: int64
如果想使用它进行条件过滤,只需将其与一个值进行比较,如下所示:
df[df["description"].str.count("used") < 1]
非常简单吧
本文介绍了基于字符串值的 5 种不同的 Pandas DataFrames 方式。虽然一般情况下我们更关注数值类型的数据,但文本数据同样重要,并且包含许多有价值的信息。能够对文本数据进行清理和预处理对于数据分析和建模至关重要。
附:pandas 中 按条件过滤字符串类型的值
一、使用~对字符串值取反:
1、测试数据
test_df
total_bill tip smoker day time size tip_pct
57 26.41 1.50 No Sat Dinner 2 0.056797
0 16.99 1.01 No Sun Dinner 2 0.059447
48 28.55 2.05 No Sun Dinner 3 0.071804
146 18.64 1.36 No Thur Lunch 3 0.072961
130 19.08 1.50 No Thur Lunch 2 0.078616
237 32.83 1.17 Yes Sat Dinner 2 0.035638
102 44.30 2.50 Yes Sat Dinner 3 0.056433
187 30.46 2.00 Yes Sun Dinner 5 0.065660
210 30.06 2.00 Yes Sat Dinner 3 0.066534
240 27.18 2.00 Yes Sat Dinner 2 0.073584
2、需求:取出 day 字段中值不为 ‘Sta’,‘Sun’ 的记录
test_df[~test_df['day'].str.contains('|'.join(['Sat', 'Sun']))]
total_bill tip smoker day time size tip_pct
146 18.64 1.36 No Thur Lunch 3 0.072961
130 19.08 1.50 No Thur Lunch 2 0.078616
总结
到此这篇关于通过5个例子让你学会Pandas中字符串过滤的文章就介绍到这了,更多相关Pandas字符串过滤内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-

通过5个例子让你学会Pandas中的字符串过滤
要处理文本数据,需要比数字类型的数据更多的清理步骤.为了从文本数据中提取有用和信息,通常需要执行几个预处理和过滤步骤. Pandas 库有许多可以轻松简单地处理文本数据函数和方法.在本文中,我介绍将学习 5 种可用于过滤文本数据(即字符串)的不同方法: 是否包含一系列字符 求字符串的长度 判断以特定的字符序列开始或结束 判断字符为数字或字母数字 查找特定字符序列的出现次数 首先我们导入库和数据 import pandas as pd df = pd.read_csv("example.csv&q
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
详解pandas如何去掉、过滤数据集中的某些值或者某些行?
摘要在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值.具体来说,看看下面的例子. 0.导入我们需要使用的包 import pandas as pd pandas是很常用的数据分析,数据处理的包.anaconda已经有这个包了,纯净版python的可以自行pip安装. 1.去掉某些具体值 数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本.如何做?非常简单. import pandas as pd df[(True-df['appPlatfor
-
详解pandas中MultiIndex和对象实际索引不一致问题
在最新版的pandas中(不知道之前的版本有没有这个问题),当我们对具有多层次索引的对象做切片或者通过df[bool_list]的方式索引的时候,得到的新的对象尽管实际索引已经发生了改变,但是当直接使用df_new.index调取新对象的MultiIndex对象的时候,这个MultiIndex对象还是和原对象的索引保持一致的,而不是和新对象的实际索引保持一致.这点需要特别注意,因为正常情况下,我们自然会认为df.index的MultiIndex对象和df的实际索引是一致的,基于此,我们可能会写出
-
用pandas中的DataFrame时选取行或列的方法
如下所示: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型 data.w #选择表格
-
对pandas中两种数据类型Series和DataFrame的区别详解
1. Series相当于数组numpy.array类似 s1=pd.Series([1,2,4,6,7,2]) s2=pd.Series([4,3,1,57,8],index=['a','b','c','d','e']) print s2 obj1=s2.values # print obj1 obj2=s2.index # print obj2 # print s2[s2>4] # print s2['b'] 1.Series 它是有索引,如果我们未指定索引,则是以数字自动生成. 下面是一些例
-
pandas 中对特征进行硬编码和onehot编码的实现
首先介绍两种编码方式硬编码和onehot编码,在模型训练所需要数据中,特征要么为连续,要么为离散特征,对于那些值为非数字的离散特征,我们要么对他们进行硬编码,要么进行onehot编码,转化为模型可以用于训练的特征 初始化一个DataFrame import pandas as pd df = pd.DataFrame([ ['green', 'M', 20, 'class1'], ['red', 'L', 21, 'class2'], ['blue', 'XL',30, 'class3']])
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
pandas中ix的使用详细讲解
在上一篇博客中,我们已经仔细讲解了iloc和loc,只是简单了提到了ix.这是因为相比于前2者,ix更复杂,也更让人迷惑. 因此,本篇博客通过例子的解释试图来描述清楚ix,尤其是与iloc和loc的联系. 首先,再次介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列). iloc gets rows (or columns) at particular
-
python3中datetime库,time库以及pandas中的时间函数区别与详解
1介绍datetime库之前 我们先比较下time库和datetime库的区别 先说下time 在 Python 文档里,time是归类在Generic Operating System Services中,换句话说, 它提供的功能是更加接近于操作系统层面的.通读文档可知,time 模块是围绕着 Unix Timestamp 进行的. 该模块主要包括一个类 struct_time,另外其他几个函数及相关常量. 需要注意的是在该模块中的大多数函数是调用了所在平台C library的同名函数, 所以