Python中loguru日志库的使用
目录
- 1.概述
- 2.常见用法
- 2.1.显示格式
- 2.2.写入文件
- 2.3.json日志
- 2.4.日志绕接
- 2.5.并发安全
- 3.高级用法
- 3.1.接管标准日志logging
- 3.2.输出日志到网络服务器
- 3.3.与pytest结合
- 附录
1.概述
python中的日志库logging使用起来有点像log4j,但配置通常比较复杂,构建日志服务器时也不是方便。标准库logging的替代品是loguru,loguru使用起来就简单的多。
loguru默认的输出格式是:时间、级别、模块、行号以及日志内容。loguru不需要手动创建 logger,开箱即用,比logging使用方便得多;另外,日志输出内置了彩色功能,颜色和非颜色控制很方便,更加友好。
loguru是非标准库,需要事先安装,命令是:**pip3 install loguru****。**安装后,最简单的使用样例如下:
from loguru import logger
logger.debug('hello, this debug loguru')
logger.info('hello, this is info loguru')
logger.warning('hello, this is warning loguru')
logger.error('hello, this is error loguru')
logger.critical('hello, this is critical loguru')
上述代码输出:
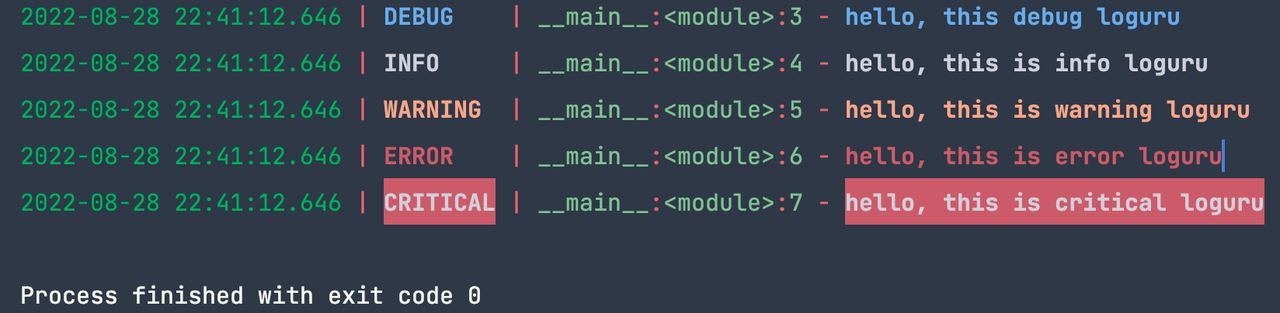
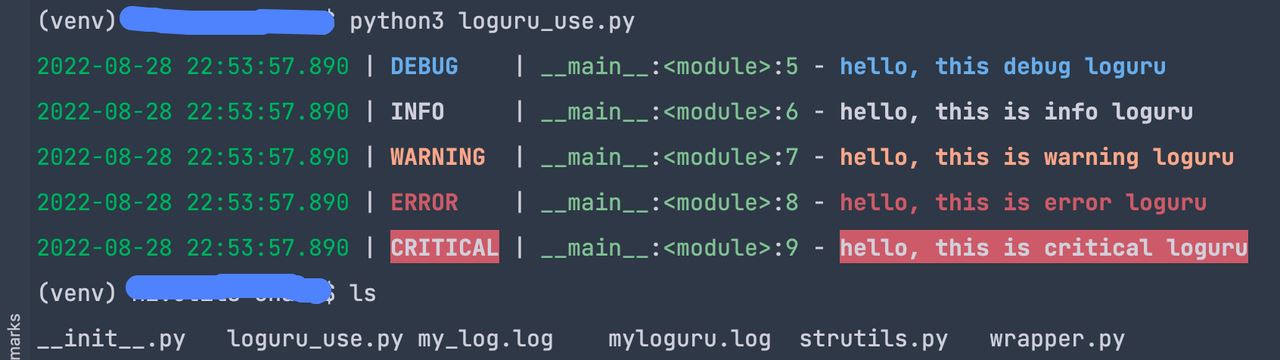
日志打印到文件的用法也很简单,代码如下:
from loguru import logger
logger.add('myloguru.log')
logger.debug('hello, this debug loguru')
logger.info('hello, this is info loguru')
logger.warning('hello, this is warning loguru')
logger.error('hello, this is error loguru')
logger.critical('hello, this is critical loguru')
上述代码运行时,可以打印到console,也可以打印到文件中去。
2.常见用法
2.1.显示格式
loguru默认格式是时间、级别、名称+模块和日志内容,其中名称+模块是写死的,是当前文件的__name__变量,此变量最好不要修改。
工程比较复杂的情况下,自定义模块名称,是非常有用的,容易定界定位,避免陷入细节中。我们可以通过logger.configure手工指定模块名称。如下如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
handlers:表示日志输出句柄或者目的地,sys.stderr表示输出到命令行终端。
"sink": sys.stderr,表示输出到终端
"format":表示日志格式化。<lvl>{level:8}</>表示按照日志级别显示颜色。8表示输出宽度为8个字符。
"colorize":True**:表示显示颜色。
上述代码的输出为:

这里写死了模块名称,每个日志都这样设置也是比较繁琐。下面会介绍指定不同模块名称的方法。
2.2.写入文件
日志一般需要持久化,除了输出到命令行终端外,还需要写入文件。标准日志库可以通过配置文件配置logger,在代码中也可以实现,但过程比较繁琐。loguru相对而已就显得稍微简单一些,我们看下在代码中如何实现此功能。日志代码如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
与2.1.唯一不同的地方,
logger.configure新增了一个handler,写入到日志文件中去。用法很简单。
上述只是通过logger.configure设置日志格式,但是模块名不是可变的,实际项目开发中,不同模块写日志,需要指定不同的模块名称。因此,模块名称需要参数化,这样实用性更强。样例代码如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>{extra[module_name]}</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | {extra[module_name]} | - {message}",
"colorize": False
},
])
log = logger.bind(module_name='my-loguru')
log.debug("this is hello, module is my-loguru")
log2 = logger.bind(module_name='my-loguru2')
log2.info("this is hello, module is my-loguru2")
logger.bind(module_name='my-loguru')通过bind方法,实现module_name的参数化。bind返回一个日志对象,可以通过此对象进行日志输出,这样就可以实现不同模块的日志格式。loguru中自定义模块名称的功能比标准日志库有点不同。通过bind方法,可以轻松实现标准日志
logging的功能。而且,可以通过bind和logger.configure,轻松实现结构化日志。
上述代码的输出如下:

2.3.json日志
loguru保存成结构化json格式非常简单,只需要设置serialize=True参数即可。代码如下:
from loguru import logger
logger.add('json.log', serialize=True, encoding='utf-8')
logger.debug('this is debug message')
logger.info('this is info message')
logger.error('this is error message')
输出内容如下:

2.4.日志绕接
loguru日志文件支持三种设置:循环、保留、压缩。设置也比较简单。尤其是压缩格式,支持非常丰富,常见的压缩格式都支持,比如:"gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2", "tar.xz", "zip"。样例代码如下:
from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间
2.5.并发安全
loguru默认是线程安全的,但不是多进程安全的,如果使用了多进程安全,需要添加参数enqueue=True,样例代码如下:
logger.add("somefile.log", enqueue=True)
loguru另外还支持协程,有兴趣可以自行研究。
3.高级用法
3.1.接管标准日志logging
更换日志系统或者设计一套日志系统,比较难的是兼容现有的代码,尤其是第三方库,因为不能因为日志系统的切换,而要去修改这些库的代码,也没有必要。好在loguru可以方便的接管标准的日志系统。
样例代码如下:
import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')
输出为:

3.2.输出日志到网络服务器
如果有需要,不同进程的日志,可以输出到同一个日志服务器上,便于日志的统一管理。我们可以利用自定义或者第三方库进行日志服务器和客户端的设置。下面介绍两种日志服务器的用法。
3.2.1.自定义日志服务器
日志客户端段代码如下:
# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
logger.error("Sending error message from the client")
日志服务器代码如下:
# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()
运行结果如下:
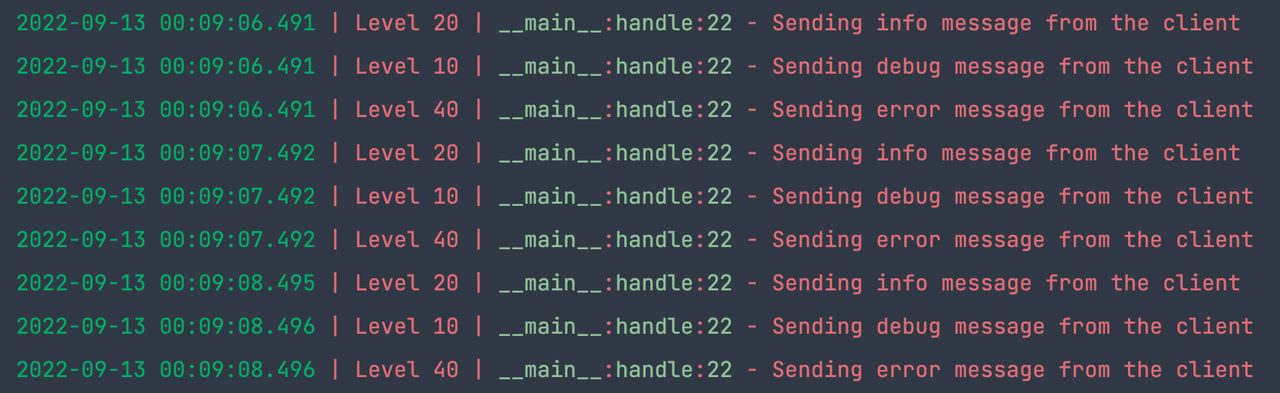
3.2.2.第三方库日志服务器
日志客户端代码如下:
# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")
日志服务器代码如下:
# server.py
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())
3.3.与pytest结合
官方帮助中有一个讲解loguru与pytest结合的例子,讲得有点含糊不是很清楚。简单的来说,pytest有个fixture,可以捕捉被测方法中的logging日志打印,从而验证打印是否触发。
下面就详细讲述如何使用loguru与pytest结合的代码,如下:
import pytest
from _pytest.logging import LogCaptureFixture
from loguru import logger
def some_func(i, j):
logger.info('Oh no!')
logger.info('haha')
return i + j
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(caplog.handler, format="{message}")
yield caplog
logger.remove(handler_id)
def test_some_func_logs_warning(caplog):
assert some_func(-1, 3) == 2
assert "Oh no!" in caplog.text
测试输出如下:
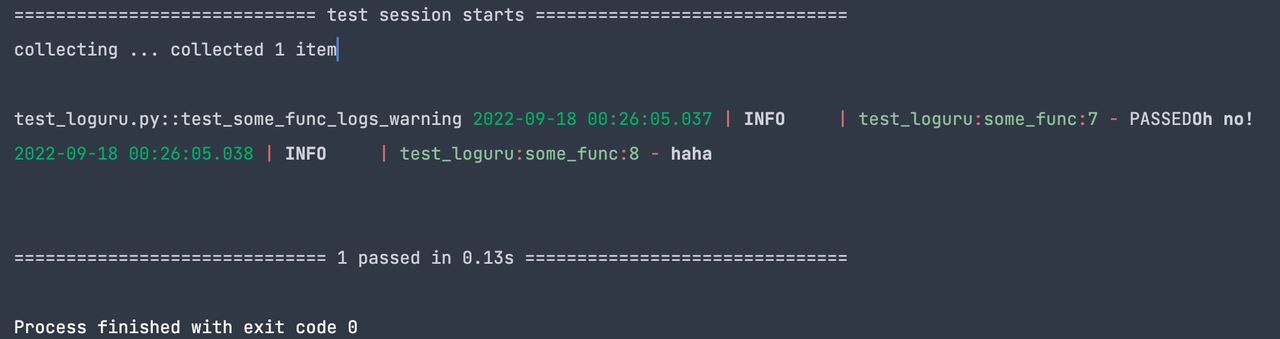
附录
1.官方帮助文档:https://loguru.readthedocs.io/en/stable/index.html
到此这篇关于Python中loguru日志库的使用的文章就介绍到这了,更多相关Python loguru日志库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python解析库Beautiful Soup安装的详细步骤
目录 一.Beautiful Soup的安装 1.1 安装lxml库 1.2 安装beautifulsoup4 1.3 验证beautifulsoup4能否运行 补充:Python 安装beautifulsoup4库失败或引用错误的解决办法 总结 一.Beautiful Soup的安装 Beautiful Soup是Python的一个HTML或XML的解析库,使用它可以很方便地从网页中提取数据.它的解析器是依赖于lxml库的,所以在此之前,请确保已经成功安装好了lxml库. 本文环境是windo
-
关于Python网络爬虫requests库的介绍
1. 什么是网络爬虫 简单来说,就是构建一个程序,以自动化的方式从网络上下载.解析和组织数据. 就像我们浏览网页的时候,对于我们感兴趣的内容我们会复制粘贴到自己的笔记本中,方便下次阅读浏览——网络爬虫帮我们自动完成这些内容 当然如果遇到一些无法复制粘贴的网站——网络爬虫就更能显示它的力量了 为什么需要网络爬虫 当我们需要做一些数据分析的时候——而很多时候这些数据存储在网页中,手动下载需要花费的时间太长,这时候我们就需要网络爬虫帮助我们自动爬取这些数据来(当然我们会过滤掉网页上那些没用的东西) 网
-
关于如何使用python的gradio库
Gradio是一个功能丰富的Python库,可以让您轻松创建和共享自己的交互式机器学习和深度学习模型. 以下是Gradio库的一些主要功能: 创建交互式接口 Gradio库使得创建交互式接口变得非常简单.您只需要定义一个函数来表示您的模型或应用程序,Gradio库将使用这个函数来创建一个用户友好的交互式界面,让用户输入参数并查看输出结果. 支持多种输入和输出类型 Gradio库支持多种输入和输出类型,包括文本.图像.音频和视频.您可以轻松地定义自己的输入和输出类型,并将其与您的模型或应用程序相关
-
Python中logging日志库实例详解
logging的简单使用 用作记录日志,默认分为六种日志级别(括号为级别对应的数值) NOTSET(0) DEBUG(10) INFO(20) WARNING(30) ERROR(40) CRITICAL(50) special 在自定义日志级别时注意不要和默认的日志级别数值相同 logging 执行时输出大于等于设置的日志级别的日志信息,如设置日志级别是 INFO,则 INFO.WARNING.ERROR.CRITICAL 级别的日志都会输出. |2logging常见对象 Logger:日志,
-
Python loguru日志库之高效输出控制台日志和日志记录
1安装loguru loguru的PyPI地址为:https://pypi.org/project/loguru/ GitHub仓库地址为:https://github.com/Delgan/loguru 我们可以直接使用pip命令对其进行安装 pip install loguru 或者下载其源码,使用Python命令进行安装. |2loguru简单使用 from loguru import logger logger.info("中文loguru") logger.debug(&qu
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
使用Filter过滤python中的日志输出的实现方法
事情是这样的,我写了一个tornado的服务,过程当中我用logging记录一些内容,由于一开始并没有仔细观察tornado自已的日志管理,所以我就一般用debug来记录普通日志,error记录有问题的日志,但是当服务跑起来以后才发现,tornado的访问日志的级别是info,也就是20,debug是10的,所以如果我定义了日志的级别是debug,那么默认情况下肯定也会输出到日志文件中的. 但是我现在并不关心访问日志,而且由于我这个服务可能每时每刻都会有访问,这样在我对日志信息进行搜索的时候就会
-
对python中的xlsxwriter库简单分析
一.xlsxwriter 基本用法,创建 xlsx 文件并添加数据 官方文档:http://xlsxwriter.readthedocs.org/ xlsxwriter 可以操作 xls 格式文件 注意:xlsxwriter 只能创建新文件,不可以修改原有文件.如果创建新文件时与原有文件同名,则会覆盖原有文件 Linux 下安装: sudo pip install XlsxWriter Windows 下安装: pip install XlsxWriter # coding=utf-8 from
-
Python中的wordcloud库安装问题及解决方法
今天下载wordcloud的时候出现了很多问题,在此总结总结 1.问题一:You are using pip version 19.0.3, however version 20.0.2 is available-问题 解决方法: 打开cmd输入如下命令 python -m pip install -U pip 2.问题二:error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual 解决方法: 方法1(不
-
Python中logger日志模块详解
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
-
Python中logging日志记录到文件及自动分割的操作代码
日志作为项目开发和运行中必备组件,python提供了内置的logging模块来完成这个工作:借助 TimedRotatingFileHandler 可以按日期自动分割日志,自动保留日志文件数量等,下面是对日志的一个简单封装和测试. import logging import os from logging import handlers class Logger(object): # 日志级别关系映射 level_relations = { 'debug': logging.DEBUG, 'in
-
Python中logging日志的四个等级和使用
1. logging日志的介绍 在现实生活中,记录日志非常重要,比如:银行转账时会有转账记录:飞机飞行过程中,会有个黑盒子(飞行数据记录器)记录着飞机的飞行过程,那在咱们python程序中想要记录程序在运行时所产生的日志信息,怎么做呢? 可以使用 logging 这个包来完成 记录程序日志信息的目的是: 1. 可以很方便的了解程序的运行情况 2. 可以分析用户的操作行为.喜好等信息 3. 方便开发人员检查bug 2. logging日志级别介绍 日志等级可以分为5个,从低到高分别是: 1. DE
-

使用豆瓣源来安装python中的第三方库方法
这里以安装简单的nonebot库为例子 欧克,简明扼要,拿走点赞哟: 大家想要的豆瓣源如下: 因为有几个,但在这里还是建议使用国内的豆瓣源,本人感觉好用. pip3 install nonebot -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com 解释一下啊:nonebot 这个是你自己要安装的第三方库的名字,自己想要装的第三方库就这改就行了. 下面这些是对于不会安装第三方库的同学们而写,如果会的话可以忽略下面,那就