如何用分表存储来提高性能 推荐
首先,童家旺介绍了他认为的什么是优化:第一、做任何事情最快的方法就是什么也不做。

▲支付宝资深数据库架构师童家旺
第二、不访问不必要的数据:使用B*Tree/hash等方法定位必要的数据。使用column Store或分表的方式将数据分开存储。使用Bloom filter算法排除空值查询。
第三、合理的利用硬件来提升访问效率:使用缓存消除对数据的重复访问。使用批量处理来减少磁盘的Seek操作。使用批量处理来减少网络的Round Trip。使用SSD来提升磁盘访问效率。
响应时间和吞吐量之间的关系
1、性能。衡量完成特定任务的速度或效率。
2、响应时间。衡量系统与用户交互式多久能够发出响应。
3、吞吐量。衡量系统在单位时间里可以完成的任务量。
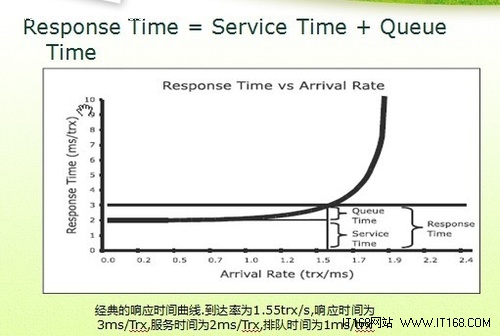
▲反应时间
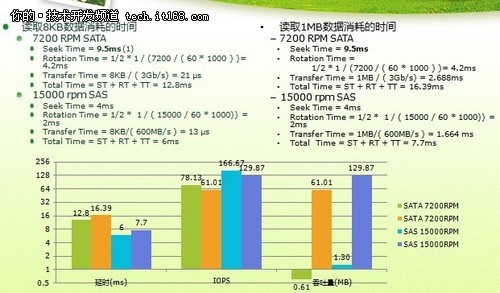
▲传统磁盘的访问特性
B*Tree优化数据访问介绍
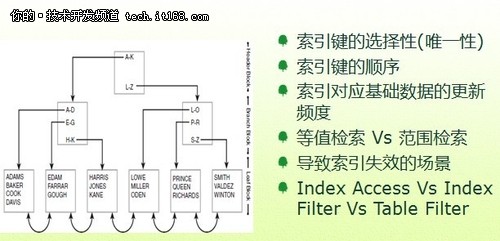
▲B*Tree优化数据访问
B*Tree优化数据访问模拟场景

▲B*Tree优化数据访问模拟场景
童家旺通过阿里巴巴的真实应用场景介绍了如何用分表存储来提高性能。
一、场景介绍:
1、表VeryBigTable含有30个列
2、表的记录数为50,000,000条
3、平均每个用户为300条左右
4、其中有2个列属于详细描述字段,平均长度为2k
5、其它的列的总长度平均为250个字节
6、此表上的查询有两种模式
7、列出表中的主要信息(每次20条,不包含详细信息,90%的查询)
8、查看记录的详细信息(10%的查询)
9、保存与Oracle数据库,默认block_size(8k)
二、要求:
1、对此业务进行优化
2、分析数据,说服开发部门实施此优化
三、性能分析
1、每块记录数
8192 * 0.80(1) / 250 = 25.5 (主表)
8192 * 0.80 / 2000 = 3.27(详情表)
8192 * 0.80 / ( 2000 + 250 ) = 2.91
2、访问的逻辑IO(内存块访问)
List的查询代价
改进后=( 300/25.5 ) * y + 4 + x = 4 + x + 11.8y = 4(2) + 7(3) + 11.8 * 1.5(4) = 28.7
改进前=( 300/2.91 ) * y + 4 + x = 4 + x + 103.y = 4 + 7 + 103 * 1.5 = 165.5
3、访问涉及到的物理读(磁盘块访问)
List的查询代价(逻辑IO * ( 1 – 命中率 ))
改进后=28.7 * ( 1 – 0.85(5)) = 4.305
改进前=165.5 * ( 1 – 0.85 ) = 24.825
4、访问时间(ms)
改进前=逻辑IO时间+物理IO时间= 28.7 * 0.01(6) + 4.305 * 7(7) = 30.422ms
改进后=逻辑IO时间+物理IO时间= 165.5 * 0.01 + 24.825 * 7 = 175.43ms
相关推荐
-
php实现mysql数据库分表分段备份
分卷导出思路:统计sql语句变量的长度,按1个字符当成1 字节比较,如果大于设定分卷大小,则写入一个sql文件(我也不知道这样统计是否稳当,这也是借鉴其他的人的). 分卷导入思路:按行读取sql文件,将每一行当作完整的sql语句存到数组再循环执行插入数据库就可以了,但是在创建表语句分了多行,这个需要单独处理(就这个花了我好长时间的): <?php //宋正河 转载请注明出处 set_time_limit(0); header('content-type:text/html;charset=utf
-
MySQL 分表优化试验代码
这里的分表逻辑是根据t_group表的user_name组的个数来分的.因为这种情况单独user_name字段上的索引就属于烂索引.起不了啥名明显的效果. 1.试验PROCEDURE.DELIMITER $$DROP PROCEDURE `t_girl`.`sp_split_table`$$CREATE PROCEDURE `t_girl`.`sp_split_table`()BEGIN declare done int default 0; declare v_user_name var
-
使用MySQL的LAST_INSERT_ID来确定各分表的唯一ID值
分表除了表名的索引不同之外,表结构都是一样的,如果各表的'ID'字段仍采用'AUTO_INCREMENT'的方式的话,ID就不能唯确定一条记录了. 这时就需要一种处于各个分表之外的机制来生成ID,我们一般采用一张单独的数据表(不妨假设表名为'ticket_mutex')来保存这个ID,无论哪个分表有数据增加时,都是先到ticket_mutex表把ID值加1,然后取得ID值. 这个取ID的操作看似很复杂,所幸的是,MySQL提供了LAST_INSERT_ID机制,让我们能一步完成. 1.新建数据表
-
php 分库分表hash算法
复制代码 代码如下: //分库分表算法 function calc_hash_db($u, $s = 4) { $h = sprintf("%u", crc32($u)); $h1 = intval(fmod($h, $s)); return $h1; } for($i=1;$i<100;$i++) { echo calc_hash_db($i); echo "<br>"; } function calc_hash_tbl($u, $n = 256
-
MySQL动态创建表,数据分表的存储过程
复制代码 代码如下: BEGIN DECLARE `@i` int(11); DECLARE `@siteCount` int(11); DECLARE `@sqlstr` VARCHAR(2560); DECLARE `@sqlinsert` VARCHAR(2560); //以上声明变量 SELECT COUNT(0) into `@siteCount` FROM tbl_base_site; //计算表tbl_base_site的记录总条数 set `@i`=1; WHILE (`@i`-
-
mysql的3种分表方案
一.先说一下为什么要分表:当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. 根据个人经验,mysql执行一个sql的过程如下:1.接收到sql; 2.把sql放到排队队列中;3.执行sql; 4.返回执行结果.在这个执行过程中最花时间在什么地方呢?第一,是排队等待的时间,第二,sql的执行时间.其实这二个是一回事,等待的同时,肯定有sql在执行.所以我们要缩短sql的执行时间. mysql中有一种机
-
1亿条数据如何分表100张到Mysql数据库中(PHP)
下面通过创建100张表来演示下1亿条数据的分表过程,具体请看下文代码. 当数据量猛增的时候,大家都会选择库表散列等等方式去优化数据读写速度.笔者做了一个简单的尝试,1亿条数据,分100张表.具体实现过程如下: 首先创建100张表: $i=0; while($i<=99){ echo "$newNumber \r\n"; $sql="CREATE TABLE `code_".$i."` ( `full_code` char(10) NOT NULL,
-

如何用分表存储来提高性能 推荐
首先,童家旺介绍了他认为的什么是优化:第一.做任何事情最快的方法就是什么也不做. ▲支付宝资深数据库架构师童家旺 第二.不访问不必要的数据:使用B*Tree/hash等方法定位必要的数据.使用column Store或分表的方式将数据分开存储.使用Bloom filter算法排除空值查询. 第三.合理的利用硬件来提升访问效率:使用缓存消除对数据的重复访问.使用批量处理来减少磁盘的Seek操作.使用批量处理来减少网络的Round Trip.使用SSD来提升磁盘访问效率. 响应时间和吞吐量之间的关系
-
MyBatis实现Mysql数据库分库分表操作和总结(推荐)
前言 作为一个数据库,作为数据库中的一张表,随着用户的增多随着时间的推移,总有一天,数据量会大到一个难以处理的地步.这时仅仅一张表的数据就已经超过了千万,无论是查询还是修改,对于它的操作都会很耗时,这时就需要进行数据库切分的操作了. MyBatis实现分表最简单步骤 既然文章的标题都这么写了,不如直接上干货来的比较实际,我们就先来看看如何实现最简单的分表. 1.我们模拟用户表数据量超过千万(虽然实际不太可能) 2.用户表原来的名字叫做user_tab,我们切分为user_tab_0和user_t
-
mysql数据库分表分库的策略
一.先说一下为什么要分表: 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕.分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率.数据库中的数据量不一定是可控的,在未进行分
-
Spring Boot 集成 Sharding-JDBC + Mybatis-Plus 实现分库分表功能
一. Sharding-jdbc简介 " Sharding-jdbc是开源的数据库操作中间件:定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架. 官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/ 本文demo实现了分库分表功能.如有错误,欢迎各位在评论中指出.不
-
Mysql数据库性能优化三(分表、增量备份、还原)
接上篇Mysql数据库性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻辑上可以划分.一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势.比如系统界面上只提供按月查询的功能,那么把表按月拆分成12个,每个查询只查询一个表就够了.如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了.所以一个好的拆分依据是 最重要的
-
超大数据量存储常用数据库分表分库算法总结
当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而且数据量太大的话,如果用单表存储,就会使得系统相当的不稳定,mysql服务很容易挂掉.所以当数据量超过200w的时候,建议系统工程师还是考虑分表. 以下是几种常见的分表算法. 1.按自然时间来分表/分库; 如一个应用的数据在一年后数据量会达到2
-
MYSQL性能优化分享(分库分表)
1.分库分表 很明显,一个主表(也就是很重要的表,例如用户表)无限制的增长势必严重影响性能,分库与分表是一个很不错的解决途径,也就是性能优化途径,现在的案例是我们有一个1000多万条记录的用户表members,查询起来非常之慢,同事的做法是将其散列到100个表中,分别从members0到members99,然后根据mid分发记录到这些表中,牛逼的代码大概是这样子: 复制代码 代码如下: <?php for($i=0;$i< 100; $i++ ){ //echo "CREATE TA
-
MYSQL数据库数据拆分之分库分表总结
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能.如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待. 可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的
-
mysql分表和分区的区别浅析
一.什么是mysql分表和分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表 什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上 二.mysql分表和分区有什么区别呢 1.实现方式上 a)mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构文件. 复制代码 代码如下: [root@BlackGhost test]# ls |grep use
-
什么是分表和分区 MySql数据库分区和分表方法
1.为什么要分表和分区 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕.分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率. 2.什么是分表和分区 2.1 分表 分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构