基于HashMap遍历和使用方法(详解)
map的几种遍历方式:
Map< String, String> map = new HashMap<>();
map.put("aa", "@sohu.com");
map.put("bb","@163.com");
map.put("cc", "@sina.com");
System.out.println("普通的遍历方法,通过Map.keySet遍历key和value");//普通使用,二次取值
for (String key : map.keySet()) {
System.out.println("key= "+key+" and value= "+map.get(key));
}
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String, String> entry = it.next();
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
System.out.println("通过Map.entrySet遍历key和value"); //推荐这种,特别是容量大的时候
for(Map.Entry<String, String> entry : map.entrySet()){
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
System.out.println(“通过Map.values()遍历所有的value,但不能遍历key”);
for(String v : map.values()){
System.out.println("value = "+v);
}
HashMap和Hashtable的联系和区别
实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用,早期的版本一般都是安全的。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
hashmap的特点
HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,不是线程安全的
hashMap用hash表来存储map的键
key是无序唯一,可以有一个为null
value无序不唯一,可以有对个null
linkedHashMap使用hash表存储map中的键,并且使用linked双向链表管理顺序
我们用的最多的是HashMap,在Map 中插入、删除和定位元素,HashMap 是最好的选择。如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列.
HashMap是一个最常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为NULL,允许多条记录的值为NULL。 HashMap不支持线程同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致性。
如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
几大常用集合的效率对比
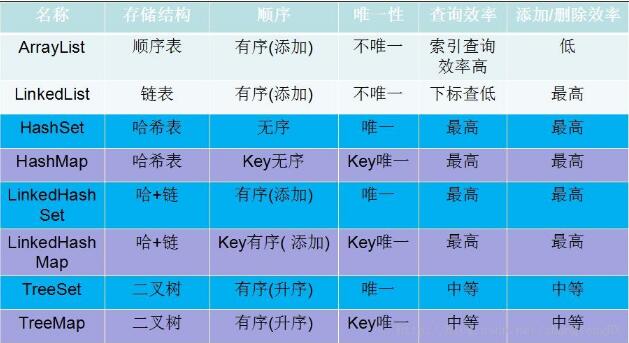
以上这篇基于HashMap遍历和使用方法(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java中Map的遍历方法及性能测试
1. 阐述 对于Java中Map的遍历方式,很多文章都推荐使用entrySet,认为其比keySet的效率高很多.理由是:entrySet方法一次拿到所有key和value的集合:而keySet拿到的只是key的集合,针对每个key,都要去Map中额外查找一次value,从而降低了总体效率.那么实际情况如何呢? 为了解遍历性能的真实差距,包括在遍历key+value.遍历key.遍历value等不同场景下的差异,我试着进行了一些对比测试. 2. 对比测试 一开始只进行了简单的测试,但结果却表明k
-
java遍历HashMap简单的方法
本文实例讲述了java遍历HashMap简单的方法.分享给大家供大家参考.具体实现方法如下: import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { HashMap map = new HashMap(); map.put("a", "aa"
-
使用多种方式实现遍历HashMap的方法
今天讲解的主要是使用多种方式来实现遍历HashMap取出Key和value,首先在java中如果想让一个集合能够用for增强来实现迭代,那么此接口或类必须实现Iterable接口,那么Iterable究竟是如何来实现迭代的,在这里将不做讲解,下面主要讲解一下遍历过程. //定义一个泛型集合 Map<String, String> map = new HashMap<String, String>(); //通过Map的put方法向集合中添加数据 map.put("001&
-

Java集合之HashMap用法详解
本文实例讲述了Java集合之HashMap用法.分享给大家供大家参考,具体如下: HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里. HashMap 中作为键的对象必须重写Object的hashCode()方法和equals()方法 import java.util.Map; import java.util.HashMap; public class lzwCode { public static void main(String [] args) { M
-
Java 中的HashMap详解和使用示例_动力节点Java学院整理
第1部分 HashMap介绍 HashMap简介 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.Serializable接口. HashMap 的实现不是同步的,这意味着它不是线程安全的.它的key.value都可以为null.此外,HashMap中的映射不是有序的. HashMap 的实例有两个参数影响其性能:"初始容量" 和 "加载因子&quo
-
基于HashMap遍历和使用方法(详解)
map的几种遍历方式: Map< String, String> map = new HashMap<>(); map.put("aa", "@sohu.com"); map.put("bb","@163.com"); map.put("cc", "@sina.com"); System.out.println("普通的遍历方法,通过Map.keySet
-
基于ScheduledExecutorService的两种方法(详解)
开发中,往往遇到另起线程执行其他代码的情况,用java定时任务接口ScheduledExecutorService来实现. ScheduledExecutorService是基于线程池设计的定时任务类,每个调度任务都会分配到线程池中的一个线程去执行,也就是说,任务是并发执行,互不影响. 注意,只有当调度任务来的时候,ScheduledExecutorService才会真正启动一个线程,其余时间ScheduledExecutorService都是处于轮询任务的状态. 1.scheduleAtFix
-
jquery 遍历数组 each 方法详解
JQuery拿取对象的方式 $('#id') :通过元素的id $('tagName') : 通过元素的标签名 $('tagName tagName') : 通过元素的标签名,eg: $('ul li') $('tagName#id): 通过元素的id和标签名 $(':checkbox'):拿取input的 type为checkbox'的所有元素: Eg: <input type="checkbox" name="appetizers" value="
-
基于Vue的ajax公共方法(详解)
为了减少代码的冗余,决定抽离出请求ajax的公共方法,供同事们使用. 我使用了ES6语法,编写了这个方法. /** * @param type 请求类型,分为POST/GET * @param url 请求url * @param contentType * @param headers * @param data * @returns {Promise<any>} */ ajaxData: function (type, url, contentType, headers, data) {
-
基于laravel Request的所有方法详解
获取请求的实例 通过 Facade Request 这个 facade 可以让我们得到绑定在容器里的当前这个请求.比如: $name = Request::input('name'); 注意,如果你在一个命名空间里,你需要在类文件的顶部使用 use Request; 这条声明来导入 Request 这个 facade . 通过依赖注入 要通过依赖注入得到当前 HTTP 请求的实例,需要在你的控制器构造函数或者方法里 type-hint 类.当前请求的这个实例会被 Service Containe
-
.NET 6实现基于JWT的Identity功能方法详解
目录 需求 目标 原理与思路 实现 引入Identity组件 添加认证服务 使用JWT认证和定义授权方式 引入认证授权中间件 添加JWT配置 增加认证用户Model 实现认证服务CreateToken方法 添加认证接口 保护API资源 验证 验证1: 验证直接访问创建TodoList接口 验证2: 获取Token 验证3: 携带Token访问创建TodoList接口 验证4: 更换Policy 一点扩展 总结 参考资料 需求 在.NET Web API开发中还有一个很重要的需求是关于身份认证和授
-
Django基于ORM操作数据库的方法详解
本文实例讲述了Django基于ORM操作数据库的方法.分享给大家供大家参考,具体如下: 1.配置数据库 vim settings #HelloWorld/HelloWorld目录下 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', #mysql数据库中第一个库test 'NAME': 'test', 'USER': 'root', 'PASSWORD': '123456', 'HOST':'127.0.0.1', '
-
jQuery实现form表单基于ajax无刷新提交方法详解
本文实例讲述了jQuery实现form表单基于ajax无刷新提交方法.分享给大家供大家参考,具体如下: 首先,新建Login.html页面: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.o
-
Java基于链表实现栈的方法详解
本文实例讲述了Java基于链表实现栈的方法.分享给大家供大家参考,具体如下: 在上几小节中我们实现了基本的链表结构,并在上一节的底部给出了有关链表的源码,此处在贴一次吧,猛戳 在开始栈的实现之前,我们再来看看关于链表的只在头部进行的增加.删除.查找操作,时间复杂度均为O(1),基于链表的这几个优势,我们在此基础上实现栈. 前言,在写本小节之前,我们已经实现了一个基于静态数组的栈,转到查看.此处我们实现基于链表的栈. 1.链表类拷贝到Stack 包下: 在实现基于静态数组的栈的时候,我们已经新建了
-
python字典的遍历3种方法详解
遍历字典: keys() .values() .items() 1. xxx.keys() : 返回字典的所有的key 返回一个序列,序列中保存有字典的所有的键 效果图: 代码: # keys() 该方法会返回字典的所有的key # 该方法会返回一个序列,序列中保存有字典的所有的键 d = {'name':'孙悟空','age':18,'gender':'男'} print(d.keys()) print() # 通过遍历keys()来获取所有的键 for k in d.keys() : pri