浅谈SQL Server中统计对于查询的影响分析
而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息。
如何查看统计信息
查看SQL Server的统计信息非常简单,使用如下指令:
DBCC SHOW_STATISTICS('表名','索引名')
所得到的结果如图1所示。

图1.统计信息
统计信息如何影响查询
下面我们通过一个简单的例子来看统计信息是如何影响查询分析器。我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引,插入100条数据,从1到100,再插入9900条等于100的数据。图1中的统计信息就是示例数据的统计信息。
此时,我where后使用ref值作为查询条件,但是给定不同的值,我们可以看出根据统计信息,查询分析器做出了不同的选择,如图2所示。

图2.根据不同的谓词,查询优化器做了不同的选择
其实,对于查询分析器来说,柱状图对于直接可以确定的谓词非常管用,这些谓词比如:
where date = getdate()
where id= 12345
where monthly_sales < 10000 / 12
where name like “Careyson” + “%”
但是对于比如
where price = @vari
where total_sales > (select sum(qty) from sales)
where a.id =b.ref_id
where col1 =1 and col2=2
这类在运行时才能知道值的查询,采样步长就明显不是那么好用了。另外,上面第四行如果谓词是两个查询条件,使用采样步长也并不好用。因为无论索引有多少列,采样步长仅仅存储索引的第一列。当柱状图不再好用时,SQL Server使用密度来确定最佳的查询路线。
密度的公式是:1/表中唯一值的 个数。当密度越小时,索引越容易被选中。比如图1中的第二个表,我们可以通过如下公式来计算一下密度:

图3.某一列的密度
根据公式可以推断,当表中的数据量逐渐增大时,密度会越来越小。
对于那些不能根据采样步长做出选择的查询,查询分析器使用密度来估计行数,这个公式为:估计的行数=表中的行数*密度
那么,根据这个公式,如果我做查询时,估计的行数就会为如图4所示的数字。
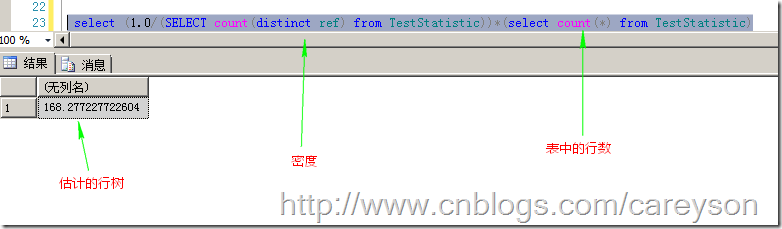
图4.估计的行数
我们来验证一下这个结论,如图5所示。

图5.估计的行数
因此,可以看出,估计的行数是和实际的行数有出入的,当数据分布均匀时,或者数据量大时,这个误差将会变的非常小。
统计信息的更新
由上面的例子可以看到,查询分析器由于依赖于统计信息进行查询,那么过时的统计信息则可能导致低效率的查询。统计信息既可以由SQL Server来进行管理,也可以手动进行更新,也可以由SQL Server管理更新时手动更新。
当开启了自动更新后,SQL Server监控表中的数据更改,当达到临界值时则会自动更新数据。这个标准是:
向空表插入数据时 少于500行的表增加500行或者更多 当表中行多于500行时,数据的变化量大于20%时
上述条件的满足均会导致统计被更新。
当然,我们也可以使用如下语句手动更新统计信息。
UPDATE STATISTICS 表名[索引名]
列级统计信息
SQL Server还可以针对不属于任何索引的列创建统计信息来帮助查询分析器获取”估计的行数“.当我们开启数据库级别的选项“自动创建统计信息”如图6所示。

图6.自动创建统计信息
当这个选项设置为True时,当我们where谓词指定了不在任何索引上的列时,列的统计信息会被创建,但是会有以下两种情况例外:
创建统计信息的成本超过生成查询计划的成本 当SQL Server忙时不会自动生成统计信息
我们可以通过系统视图sys.stats来查看这些统计信息,如图7所示。

图7.通过系统视图查看统计信息
当然,也可以通过如下语句手动创建统计信息:
CREATE STATISTICS 统计名称 ON 表名 (列名 [,...n])
总结
本文简单谈了统计信息对于查询路径选择的影响。过时的统计信息很容易造成查询性能的降低。因此,定期更新统计信息是DBA重要的工作之一。
相关推荐
-

浅谈SQL Server中统计对于查询的影响分析
而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息. 如何查看统计信息 查看SQL Server的统计信息非常简单,使用如下指令: DBCC SHOW_STATISTICS('表名','索引名') 所得到的结果如图1所示. 图1.统计信息 统计信息如何影响查询 下面我们通过一个简单的例子来看统计信息是如何影响查询分析器.我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引
-
浅谈SQL Server中的三种物理连接操作(性能比较)
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种.理解这三种物理连接是理解在表连接时解决性能问题的基础,下面我来对这三种连接的原理,适用场景进行描述. 嵌套循环连接(Nested Loop Join) 循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,嵌套循环是三种方式中唯一支持不等式连接的
-
在SQL Server中使用子查询更新语句
测试环境准备 create table #table1 ( id int , name varchar(20) ); go create table #table2 ( id int , name varchar(20) ); go insert into #table1 ( id, name ) values ( 1, 'a' ), ( 2, null ), ( 3, 'c' ), ( 4, 'd' ), ( 5, 'e' ); insert into #table2 ( id, name )
-
SQL Server中row_number分页查询的用法详解
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号.在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号. ROW_NUMBER() 说明:返回结果集分区内行的序列号,每个分区的第一行从1开始. 语法:ROW_NUMBER () OVER ([ <partition_by_clause> ] <order_by_clause>) . 备注:ORDER
-
SQL Server中的Forwarded Record计数器影响IO性能的解决方法
一.简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一谈为什么Forwarded record会造成额外的IO. 二.存放原理 在SQL Server中,当数据是以堆的形式存放时,数据是无序的,所有非聚集索引的指针存放指向物理地址的RID.当数据行中的变长列增长使得原有页无法容纳下数据行时,数据将会移动到新的页中,并在原位置留下一个指向新页的指针,这么做的
-
浅谈SQL Server 对于内存的管理[图文]
理解SQL Server对于内存的管理是对于SQL Server问题处理和性能调优的基本,本篇文章讲述SQL Server对于内存管理的内存原理. 二级存储(secondary storage) 对于计算机来说,存储体系是分层级的.离CPU越近的地方速度愉快,但容量越小(如图1所示).比如:传统的计算机存储体系结构离CPU由近到远依次是:CPU内的寄存器,一级缓存,二级缓存,内存,硬盘.但同时离CPU越远的存储系统都会比之前的存储系统大一个数量级.比如硬盘通常要比同时代的内存大一个数量级. 图1
-
浅谈SQL Server交叉联接 内部联接
前言 本节开始我们进入联接学习,关于连接这一块涉及的内容比较多,我们一步一步循序渐进学习,简短内容,深入的理解. 交叉联接(CROSS JOIN) 交叉连接是最简单的联接类型.交叉联接仅执行一个逻辑查询处理阶段-笛卡尔乘积.例如对两个输入表进行操作,联接并生成两个表的笛卡尔乘积,也就是说,将一个表的每一行与另一个表的所有行进行匹配.所以,如果一个表有m行,另一个表有n行,得到的结果中则会有m*n行.我们就拿SQL Server 2012教程中的例子说下 SELECT C.custid, E.em
-
SQL Server中统计每个表行数的快速方法
我们都知道用聚合函数count()可以统计表的行数.如果需要统计数据库每个表各自的行数(DBA可能有这种需求),用count()函数就必须为每个表生成一个动态SQL语句并执行,才能得到结果.以前在互联网上看到有一种很好的解决方法,忘记出处了,写下来分享一下. 该方法利用了sysindexes 系统表提供的rows字段.rows字段记录了索引的数据级的行数.解决方法的代码如下: 复制代码 代码如下: select schema_name(t.schema_id) as [Schema], t.na
-
浅谈SQL Server 2016里TempDb的进步
几个星期前,SQL Server 2016的最新CTP版本已经发布了:CTP 2.4(目前已经是CTP 3.0).这个预览版相比以前的CTP包含了很多不同的提升.在这篇文章里我会谈下对于SQL Server 2016,TempDb里的显著提升. TempDb定制 在SQL Server 2016安装期间,第一个你会碰到的改变是在安装过程中,现在你能配置TempDb的物理配置.我们可以详细看下面的截屏. 微软现在检测几个可用的CPU内核,基于这个数字安装程序自动配置TempDb文件个数.这个对克服
-
浅谈SQL SERVER数据库口令的脆弱性
跟踪了一下SQL SERVER数据库服务器的登录过程,发现口令计算是非常脆弱的,SQL SERVER数据库的口令脆弱体现两方面: 1.网络登陆时候的口令加密算法 2.数据库存储的口令加密算法. 下面就分别讲述: 1.网络登陆时候的口令加密算法 SQL SERVER网络加密的口令一直都非常脆弱,网上有很多写出来的对照表,但是都没有具体的算法处理,实际上跟踪一下SQL SERVER的登陆过程,就很容易获取其解密的算法:好吧,我们还是演示一下汇编流程: 登录类型的TDS包跳转到4126a4处执行 00