TrieTree服务-组件构成及其作用介绍
上一篇中我们对TrieTree服务有了一个整体的了解,不知道大家下载完之后有没有真正玩过这个TrieTree服务,如果你还没有玩过,没关系,本文将一步步教你配置和使用TrieTree服务。
TrieTree服务由几大组件组成,如下图

Dictionary组件是核心库,主要提供基本数据定义、配置信息定义,数据结构表示,同时也提供了POSType(参考Pangu的Part of Speech定义)。由于TrieTree是利用内存来加载数据的,所以这个组件的设计直接决定了内存的占用大小和数据查询性能。Dictionary.Providers组件主要负责提供各种自定义数据提供者(DataProvider),你可以把它理解为字典数据的加载器,例如自带的PanguDictProviders就是负责加载盘古自己的dict格式的字典。TrieTree服务的加载器是高度可配置的,你可以通过配置文件来选择你需要使用的加载器,如下所示:
代码如下:
<dictionaryService>
<provider name="pangu_dict" uri="F:\Dropbox\research\NLP\TrieTreeService\DictionaryService.UnitTest\Data\panguDict.dct" type="BluePrint.Dictionary.Providers.PanguDictProvider, BluePrint.Dictionary.Providers" />
<provider name="IKdict" uri="F:\Dropbox\research\NLP\TrieTreeService\DictionaryService.UnitTest\Data\IKdict.dic" type="BluePrint.Dictionary.Providers.TxtFileProvider, BluePrint.Dictionary.Providers"/>
</dictionaryService>
上面这个配置选择了2个加载器,分别是PanguDictProvider、TxtFileProvider(纯文本格式加载器,你可以理解为.csv字典加载器),这里的TxtFileProvider是用来加载IKAnalyzer中的IKdict.dic文件的。在服务启动后(调试模式)你会看到类似的提示:

TrieTree中由于使用了log4net的ColoredConsoleAppender,所以能够显示不同颜色的提示信息。你会看到日志中有pangu_dict和IKdict的加载时间,这里的名字是由app.config中的provider的name属性设置的。其实TrieTree也是支持加载基于MongoDB的字典的,只是由于牵扯到相对复杂的MongoDB的配置和一些概念,就不在本文中讲解了,我会考虑在之后的教程中提供。
DictionaryService组件是TrieTree服务的容器组件,主要包含了Windows服务的实现,还有Windows服务的安装器。这个组件是一个控制台程序,它为用户提供了两种运行模式——调试模式和Service模式。调试模式就是直接运行控制台,提供基于log4net的日志信息,方便调试和断点;而Service模式是直接运行为一个Windows服务,主要用于测试与生产环境。由于是控制台程序,切换模式是通过参数完成的,例如-i 表示安装windows服务,-u表示卸载windows服务, -c表示启动控制台模式。
以上便是TrieTree服务的三大核心组件,但我还打算介绍一个非常实用的附加组件DictionaryQuery。
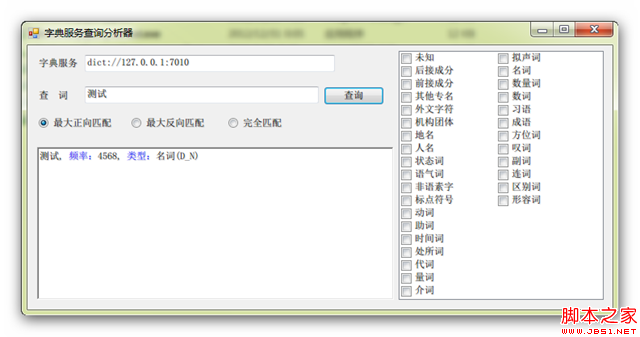
虽然名字也叫查询分析器,但其实和SQL的查询分析器不是一个级别的,你不用去比较,没啥意思。这东西主要是两个作用,第一,测试TrieTree服务的运行情况;第二,检查加载字典后字典中的词的状态。你也可以用右侧的POS过滤器进行筛选,多选表示或的关系,比如你选择了地名和人名,你搜索“上海”,结果是“上海, 频率:251, 类型:地名(A_NS)”,如果找不到的话会显示红色的“未找到合适词”,如下所示。
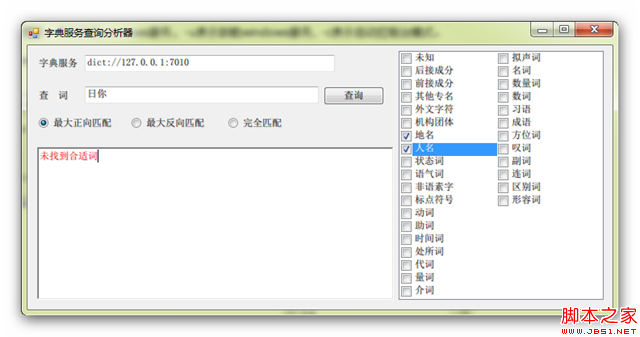
你还可以选择匹配的方式,即最大正向匹配、最大反向匹配和完全匹配,这个就不用我多解释了吧。对了,运行这玩意之前字典服务必须打开,且你要指向你配置的TrieTree服务的端口,默认是7010,图中配置的是dict://127.0.0.1:7010,注意字典服务的URI是以dict://开头的。
相关推荐
-

C# TrieTree介绍及实现方法
在自然语言处理(NLP)研究中,NGram是最基本但也是最有用的一种比对方式,这里的N是需要比对的字符串的长度,而今天我介绍的TrieTree,正是和NGram密切相关的一种数据结构,有人称之为字典树.TrieTree简单的说是一种多叉树,每个节点保存一个字符,这么做的好处是当我们要做NGram比对时,只需要直接从树的根节点开始沿着某个树叉遍历下去,就能完成比对:如果没找到,停止本次遍历.这话讲得有些抽象,我们来看一个实际的例子. 假设我们现在词库里面有以下一些词: 上海市 上海滩 上海人 上海
-
Trie树_字典树(字符串排序)简介及实现
1.综述 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计.它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高. Trie树结构的优点在于:1) 不限制子节点的数量: 2) 自定义的输入序列化,突破了具体语言.应用的限制,成为一个通用的框架: 3) 可以进行最大Tokens序列长度的限制:4) 根据已定阈值输出重复的字符串:5) 提
-
Python Trie树实现字典排序
一般语言都提供了按字典排序的API,比如跟微信公众平台对接时就需要用到字典排序.按字典排序有很多种算法,最容易想到的就是字符串搜索的方式,但这种方式实现起来很麻烦,性能也不太好.Trie树是一种很常用的树结构,它被广泛用于各个方面,比如字符串检索.中文分词.求字符串最长公共前缀和字典排序等等,而且在输入法中也能看到Trie树的身影. 什么是Trie树 Trie树通常又称为字典树.单词查找树或前缀树,是一种用于快速检索的多叉树结构.如图数字的字典是一个10叉树: 同理小写英文字母或大写英文字母的字
-
Trie树(字典树)的介绍及Java实现
简介 Trie树,又称为前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串.与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定.一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串. 它的主要特点如下: 根节点不包含字符,除根节点外的每一个节点都只包含一个字符. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串. 每个节点的所有子节点包含的字符都不相同. 如下是一棵典型的Trie树: Trie的来源是Retrie
-
详解字典树Trie结构及其Python代码实现
字典树(Trie)可以保存一些字符串->值的对应关系.基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串. Trie 的强大之处就在于它的时间复杂度.它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关.Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题:Trie 的缺点是空间消耗很高. 至于Trie树的实现
-
Java中实现双数组Trie树实例
传统的Trie实现简单,但是占用的空间实在是难以接受,特别是当字符集不仅限于英文26个字符的时候,爆炸起来的空间根本无法接受. 双数组Trie就是优化了空间的Trie树,原理本文就不讲了,请参考An Efficient Implementation of Trie Structures,本程序的编写也是参考这篇论文的. 关于几点论文没有提及的细节和与论文不一一致的实现: 1.对于插入字符串,如果有一个字符串是另一个字符串的子串的话,我是将结束符也作为一条边,产生一个新的结点,这个结点新节点的Ba
-
TrieTree服务-组件构成及其作用介绍
上一篇中我们对TrieTree服务有了一个整体的了解,不知道大家下载完之后有没有真正玩过这个TrieTree服务,如果你还没有玩过,没关系,本文将一步步教你配置和使用TrieTree服务. TrieTree服务由几大组件组成,如下图 Dictionary组件是核心库,主要提供基本数据定义.配置信息定义,数据结构表示,同时也提供了POSType(参考Pangu的Part of Speech定义).由于TrieTree是利用内存来加载数据的,所以这个组件的设计直接决定了内存的占用大小和数据查询性能.
-
Android Jetpack组件中LifeCycle作用详细介绍
目录 Jetpack 1.那么Jetpack是什么呢 2.为何使用Jetpack 3.Jetpack与AndroidX LifeCycle 1.LifeCycle的作用 2.LifeCycle应用 1.设计组件 2.使用组件 3.总结LifeCycle的使用 Jetpack Jetpack,我觉得翻译为“飞行器”更好听,因为Google针对编程历史乱象,整理出一套组件库,帮助开发者创造更完美的应用作品.现在市面上,很多公司招聘面试要求渐渐把Jetpack看作必会技能,Google也在疯狂的安利J
-
VueJs组件prop验证简单介绍
组件 Vue.js引入的组件,让分解单一HTML到独立组件成为可能.组件可以自定义元素形式使用,或者使用原生元素但是以is特性做扩展. 今天看了vuejs的组件,看到了prop组件,主要作用是在传入数据的时候对传入的值做判断,写了个小例子. <div id="app"> <my-child :num="100" :msg="'sdf'" :object="{a:'a'}" :cust="100&qu
-
vue组件name的作用小结
我们在写vue项目的时候会遇到给组件命名 这里的name非必选项,看起来好像没啥用处,但是实际上这里用处还挺多的 export default { name:'xxx' } 1.当项目使用keep-alive时,可搭配组件name进行缓存过滤 举个例子: 我们有个组件命名为detail,其中dom加载完毕后我们在钩子函数mounted中进行数据加载 export default { name:'Detail' }, mounted(){ this.getInfo(); }, methods:{
-
Spring Cloud Alibaba微服务组件Sentinel实现熔断限流
目录 Sentinel简介 Sentinel具有如下特性: 安装Sentinel控制台 创建sentinel-service模块 限流功能 创建RateLimitController类 根据URL限流 自定义限流处理逻辑 熔断功能 与Feign结合使用 使用Nacos存储规则 原理示意图 功能演示 Sentinel简介 Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案,Sentinel 作为其核心组件之一,具有熔断与限流等一系列服务保护功能,本文将对其用法进行详细介
-
Kotlin Service服务组件开发详解
目录 服务简介 服务的创建 服务的启动方式 Service的生命周期 Activity和Service进行通信 实现前台Service 服务简介 服务是Android中的四大组件之一,它能够长期在后台运行且不提供用户界面.即使用户切到另一应用程序,服务仍可以在后台运行. 服务的创建 (1)创建Service子类 class MyService : Service() { override fun onBind(intent: Intent): IBinder { TODO("Return the
-
vue.js实例对象+组件树的详细介绍
vue的实例对象 首先用js的new关键字实例化一个vue el: vue组件或对象装载在页面的位置,可通过id或class或标签名 template: 装载的内容.HTML代码/包含指令或者其他组件的HTML片段,template将是我们使用的模板 **data:** 数据通过data引入到组件中 在组件中的data要以函数的形式返回数据,当不同的界面用了同一个组件时,才不会以为一个组件的值发生改变而改变其他页面的内容. {{ }} 双括号语法里面放入数据的变量 组件注册语法糖 全局组件 A方
-
vue 自定义全局方法,在组件里面的使用介绍
在main.js里进行全局注册 Vue.prototype.funcName = function (){} 在所有组件里可调用 this. funcName(); 以上这篇vue 自定义全局方法,在组件里面的使用介绍就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Spring Boot 2.0快速构建服务组件全步骤
前言 所谓的服务组件(Service Component)- 就是用于处理系统业务逻辑的类,如果按照系统分层设计理论来划分,服务组件是位于业务层当中的类.在Spring Boot中,服务组件是一个被**@Service**注解进行注释的类,这些类用于编写系统的业务代码.在本章节中,将讲解如何创建并使用服务组件. 在开始正文之前,先来看两段示例代码.使用服务组件之前,我们需要定义服务组件接口类,用于索引服务组件提供的服务,代码如下所示: public interface UserService{
-
对pytorch的函数中的group参数的作用介绍
1.当设置group=1时: conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=1) conv.weight.data.size() 返回: torch.Size([6, 6, 1, 1]) 另一个例子: conv = nn.Conv2d(in_channels=6, out_channels=3, kernel_size=1, groups=1) conv.weight.data.size() 返回: t