图解二叉树的三种遍历方式及java实现代码
二叉树(binary tree)是一颗树,其中每个节点都不能有多于两个的儿子。
1.二叉树节点
作为图的特殊形式,二叉树的基本组成单元是节点与边;作为数据结构,其基本的组成实体是二叉树节点(binary tree node),而边则对应于节点之间的相互引用。
如下,给出了二叉树节点的数据结构图示和相关代码:
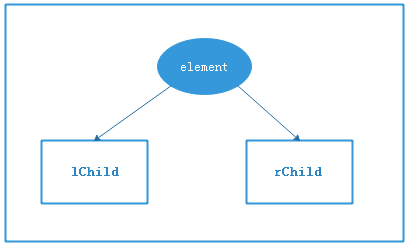
// 定义节点类:
private static class BinNode {
private Object element;
private BinNode lChild;// 定义指向左子树的指针
private BinNode rChild;// 定义指向右子树的指针
public BinNode(Object element, BinNode lChild, BinNode rChild) {
this.element = element;
this.lChild = lChild;
this.rChild = rChild;
}
}
2.递归遍历
二叉树本身并不具有天然的全局次序,故为实现遍历,需通过在各节点与其孩子之间约定某种局部次序,间接地定义某种全局次序。
按惯例左兄弟优先于右兄弟,故若将节点及其孩子分别记作V、L和R,则下图所示,局部访问的次序可有VLR、LVR和LRV三种选择。根据节点V在其中的访问次序,三种策略也相应地分别称作先序遍历、中序遍历和后序遍历,下面将分别介绍。
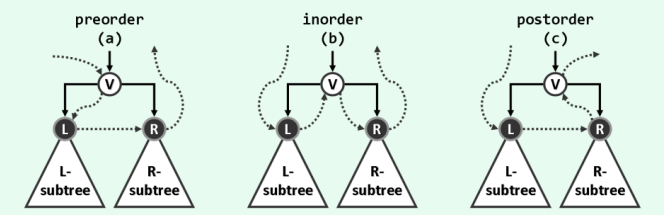
2.1 先序遍历
图示:

代码实现:
/**
* 对该二叉树进行前序遍历 结果存储到list中 前序遍历
*/
public static void preOrder(BinNode node) {
list.add(node); // 先将根节点存入list
// 如果左子树不为空继续往左找,在递归调用方法的时候一直会将子树的根存入list,这就做到了先遍历根节点
if (node.lChild != null) {
preOrder(node.lChild);
}
// 无论走到哪一层,只要当前节点左子树为空,那么就可以在右子树上遍历,保证了根左右的遍历顺序
if (node.rChild != null) {
preOrder(node.rChild);
}
}
2.2 中序遍历
图示:

代码实现:
/**
* 对该二叉树进行中序遍历 结果存储到list中
*/
public static void inOrder(BinNode node) {
if (node.lChild != null) {
inOrder(node.lChild);
}
list.add(node);
if (node.rChild != null) {
inOrder(node.rChild);
}
}
2.3 后序遍历
实例图示:

代码实现:
/**
* 对该二叉树进行后序遍历 结果存储到list中
*/
public static void postOrder(BinNode node) {
if (node.lChild != null) {
postOrder(node.lChild);
}
if (node.rChild != null) {
postOrder(node.rChild);
}
list.add(node);
}
附:测试相关代码
private static BinNode root;
private static List<BinNode> list = new ArrayList<BinNode>();
public static void main(String[] args) {
init();
// TODO Auto-generated method stub
//preOrder(root);
//inOrder(root);
postOrder(root);
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i).element + " ");
}
}
// 树的初始化:先从叶节点开始,由叶到根
public static void init() {
BinNode b = new BinNode("b", null, null);
BinNode a = new BinNode("a", null, b);
BinNode c = new BinNode("c", a, null);
BinNode e = new BinNode("e", null, null);
BinNode g = new BinNode("g", null, null);
BinNode f = new BinNode("f", e, g);
BinNode h = new BinNode("h", f, null);
BinNode d = new BinNode("d", c, h);
BinNode j = new BinNode("j", null, null);
BinNode k = new BinNode("k", j, null);
BinNode m = new BinNode("m", null, null);
BinNode o = new BinNode("o", null, null);
BinNode p = new BinNode("p", o, null);
BinNode n = new BinNode("n", m, p);
BinNode l = new BinNode("l", k, n);
root = new BinNode("i", d, l);
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Java中map遍历方式的选择问题详解
1. 阐述 对于Java中Map的遍历方式,很多文章都推荐使用entrySet,认为其比keySet的效率高很多.理由是:entrySet方法一次拿到所有key和value的集合:而keySet拿到的只是key的集合,针对每个key,都要去Map中额外查找一次value,从而降低了总体效率.那么实际情况如何呢? 为了解遍历性能的真实差距,包括在遍历key+value.遍历key.遍历value等不同场景下的差异,我试着进行了一些对比测试. 2. 对比测试 一开始只进行了简单的测试,但结果却表明k
-
Java Set集合的遍历及实现类的比较
Java Set集合的遍历及实现类的比较 Java中Set集合是一个不包含重复元素的Collection,首先我们先看看遍历方法 package com.sort; import java.util.HashSet; import java.util.Iterator; import java.util.Set; /** * 一个不包含重复元素的 collection.更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2, * @author Owner * */
-
java反射遍历实体类属性和类型,并赋值和获取值的简单方法
实例如下: import java.lang.reflect.Field; import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; import java.util.Date; /** * 获取实体类型的属性名和类型 * @param model 为实体类 * @author kou 为传入参数 */ public class GetModelNameAndType { public
-
java 使用foreach遍历集合元素的实例
java 使用foreach遍历集合元素的实例 1 代码示例 import java.util.*; public class ForeachTest { public static void main(String[] args) { // 创建集合.添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add(new String("book1")); books.add(new String("book2&quo
-
java 对文件夹目录进行深度遍历实例代码
java 对文件夹目录进行深度遍历实例代码 1.题目 对指定目录进行所有内容的列出(包含子目录中的内容),也可以理解为对目录进行深度遍历. 2.解题思想 从电脑中获取文件目录,建立函数对其遍历,在这个函数中需要对该目录中的每个文件进行判断,如果文件还是目录,则调用函数本身继续对其进行遍历,如果文件不是目录,则直接输出文件名.为了加强显示的效果,我们还可以建立一个getSpace函数,对其进行缩进. 需要注意的是,不要直接遍历C盘的内容,其目录层次太深,含有太多的系统级文件,容易返回为空,导致空指
-
java实现遍历树形菜单两种实现代码分享
文本主要向大家分享了java实现遍历树形菜单的实例代码,具体如下. OpenSessionView实现: package org.web; import java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.se
-

图解二叉树的三种遍历方式及java实现代码
二叉树(binary tree)是一颗树,其中每个节点都不能有多于两个的儿子. 1.二叉树节点 作为图的特殊形式,二叉树的基本组成单元是节点与边:作为数据结构,其基本的组成实体是二叉树节点(binary tree node),而边则对应于节点之间的相互引用. 如下,给出了二叉树节点的数据结构图示和相关代码: // 定义节点类: private static class BinNode { private Object element; private BinNode lChild;// 定义指向
-
C语言二叉树的三种遍历方式的实现及原理
二叉树遍历分为三种:前序.中序.后序,其中序遍历最为重要.为啥叫这个名字?是根据根节点的顺序命名的. 比如上图正常的一个满节点,A:根节点.B:左节点.C:右节点,前序顺序是ABC(根节点排最先,然后同级先左后右):中序顺序是BAC(先左后根最后右):后序顺序是BCA(先左后右最后根). 比如上图二叉树遍历结果 前序遍历:ABCDEFGHK 中序遍历:BDCAEHGKF 后序遍历:DCBHKGFEA 分析中序遍历如下图,中序比较重要(java很多树排序是基于中序,后面讲解分析) 下面介绍一下,二
-
Java二叉树的四种遍历方式详解
二叉树的四种遍历方式: 二叉树的遍历(traversing binary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有的结点,使得每个结点被访问依次且仅被访问一次. 四种遍历方式分别为:先序遍历.中序遍历.后序遍历.层序遍历. 遍历之前,我们首先介绍一下,如何创建一个二叉树,在这里用的是先建左树在建右树的方法, 首先要声明结点TreeNode类,代码如下: public class TreeNode { public int data; public TreeNode leftC
-
对python For 循环的三种遍历方式解析
实例如下所示: array = ["a","b","c"] for item in array: print(item) for index in range(len(array)): print(str(index)+".."+array[index]) for index,val in enumerate(array): print(str(index)+"--"+val); 打印结果 a b c 0.
-
Python三种遍历文件目录的方法实例代码
本文实例代码主要实现的是python遍历文件目录的操作,有三种方法,具体代码如下. #coding:utf-8 # 方法1:递归遍历目录 import os def visitDir(path): li = os.listdir(path) for p in li: pathname = os.path.join(path,p) if not os.path.isfile(pathname): #判断路径是否为文件,如果不是继续遍历 visitDir(pathname) else: print
-
SpringMVC上传文件的三种实现方式
SpringMVC上传文件的三种实现方式,直接上代码吧,大伙一看便知 前台: <%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.
-
浅谈HashMap中7种遍历方式的性能分析
目录 一.前言 二.HashMap遍历 2.1.迭代器EntrySet 2.2.迭代器 KeySet 2.3.ForEachEntrySet 2.4.ForEach KeySet 2.5.Lambda 2.6.Streams API 单线程 2.7.Streams API 多线程 三.性能分析 四.字节码分析 五.EntrySet性能分析 六.安全性测试 6.1.迭代器方式 6.2.For 循环方式 6.3.Lambda 方式 6.4.Stream 方式 6.5.小结 七.总结 一.前言 随着
-
教你如何使用Python实现二叉树结构及三种遍历
一:代码实现 class TreeNode: """节点类""" def __init__(self, mid, left=None, right=None): self.mid = mid self.left = left self.right = right # 树类 class Tree: """树类""" def __init__(self, root=None): self.r
-
Python 二叉树的层序建立与三种遍历实现详解
前言 二叉树(Binary Tree)时数据结构中一个非常重要的结构,其具有....(此处省略好多字)....等的优良特点. 之前在刷LeetCode的时候把有关树的题目全部跳过了,(ORZ:我这种连数据结构都不会的人刷j8Leetcode啊!!!) 所以 !!!敲黑板了!!!今天我就在B站看了数据结构中关于树的内容后,又用我浅薄的Python大法来实现一些树的建立和遍历. 关于树的建立我觉得层序建立对于使用者来说最为直观,输入很好写.(好吧,我是看LeetCode中的树输入都是采用层序输入觉得
-
Python实现重建二叉树的三种方法详解
本文实例讲述了Python实现重建二叉树的三种方法.分享给大家供大家参考,具体如下: 学习算法中,探寻重建二叉树的方法: 用input 前序遍历顺序输入字符重建 前序遍历顺序字符串递归解析重建 前序遍历顺序字符串堆栈解析重建 如果懒得去看后面的内容,可以直接点击此处本站下载完整实例代码. 思路 学习算法中,python 算法方面的资料相对较少,二叉树解析重建更少,只能摸着石头过河. 通过不同方式遍历二叉树,可以得出不同节点的排序.那么,在已知节点排序的前提下,通过某种遍历方式,可以将排序进行解析