简单谈谈python中的Queue与多进程
最近接触一个项目,要在多个虚拟机中运行任务,参考别人之前项目的代码,采用了多进程来处理,于是上网查了查python中的多进程
一、先说说Queue(队列对象)
Queue是python中的标准库,可以直接import 引用,之前学习的时候有听过著名的“先吃先拉”与“后吃先吐”,其实就是这里说的队列,队列的构造的时候可以定义它的容量,别吃撑了,吃多了,就会报错,构造的时候不写或者写个小于1的数则表示无限多
import Queue
q = Queue.Queue(10)
向队列中放值(put)
q.put(‘yang')
q.put(4)
q.put([‘yan','xing'])
在队列中取值get()
默认的队列是先进先出的
>>> q.get()
‘yang'
>>> q.get()
4
>>> q.get()
[‘yan', ‘xing']
当一个队列为空的时候如果再用get取则会堵塞,所以取队列的时候一般是用到
get_nowait()方法,这种方法在向一个空队列取值的时候会抛一个Empty异常
所以更常用的方法是先判断一个队列是否为空,如果不为空则取值
队列中常用的方法
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
非阻塞 Queue.put(item) 写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
二、multiprocessing中使用子进程概念
from multiprocessing import Process
可以通过Process来构造一个子进程
p = Process(target=fun,args=(args))
再通过p.start()来启动子进程
再通过p.join()方法来使得子进程运行结束后再执行父进程
from multiprocessing import Process
import os
# 子进程要执行的代码
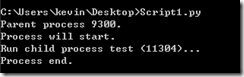
def run_proc(name):
print 'Run child process %s (%s)...' % (name, os.getpid())
if __name__=='__main__':
print 'Parent process %s.' % os.getpid()
p = Process(target=run_proc, args=('test',))
print 'Process will start.'
p.start()
p.join()
print 'Process end.'
三、在multiprocessing中使用pool
如果需要多个子进程时可以考虑使用进程池(pool)来管理
from multiprocessing import Pool
from multiprocessing import Pool import os, time def long_time_task(name): print 'Run task %s (%s)...' % (name, os.getpid()) start = time.time() time.sleep(3) end = time.time() print 'Task %s runs %0.2f seconds.' % (name, (end - start)) if __name__=='__main__': print 'Parent process %s.' % os.getpid() p = Pool() for i in range(5): p.apply_async(long_time_task, args=(i,)) print 'Waiting for all subprocesses done...' p.close() p.join() print 'All subprocesses done.'
pool创建子进程的方法与Process不同,是通过
p.apply_async(func,args=(args))实现,一个池子里能同时运行的任务是取决你电脑的cpu数量,如我的电脑现在是有4个cpu,那会子进程task0,task1,task2,task3可以同时启动,task4则在之前的一个某个进程结束后才开始
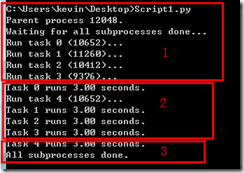
上面的程序运行后的结果其实是按照上图中1,2,3分开进行的,先打印1,3秒后打印2,再3秒后打印3
代码中的p.close()是关掉进程池子,是不再向里面添加进程了,对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
当时也可以是实例pool的时候给它定义一个进程的多少
如果上面的代码中p=Pool(5)那么所有的子进程就可以同时进行
三、多个子进程间的通信
多个子进程间的通信就要采用第一步中说到的Queue,比如有以下的需求,一个子进程向队列中写数据,另外一个进程从队列中取数据,
#coding:gbk from multiprocessing import Process, Queue import os, time, random # 写数据进程执行的代码: def write(q): for value in ['A', 'B', 'C']: print 'Put %s to queue...' % value q.put(value) time.sleep(random.random()) # 读数据进程执行的代码: def read(q): while True: if not q.empty(): value = q.get(True) print 'Get %s from queue.' % value time.sleep(random.random()) else: break if __name__=='__main__': # 父进程创建Queue,并传给各个子进程: q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) # 启动子进程pw,写入: pw.start() # 等待pw结束: pw.join() # 启动子进程pr,读取: pr.start() pr.join() # pr进程里是死循环,无法等待其结束,只能强行终止: print print '所有数据都写入并且读完'
四、关于上面代码的几个有趣的问题
if __name__=='__main__': # 父进程创建Queue,并传给各个子进程: q = Queue() p = Pool() pw = p.apply_async(write,args=(q,)) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'
如果main函数写成上面的样本,本来我想要的是将会得到一个队列,将其作为参数传入进程池子里的每个子进程,但是却得到
RuntimeError: Queue objects should only be shared between processes through inheritance
的错误,查了下,大意是队列对象不能在父进程与子进程间通信,这个如果想要使用进程池中使用队列则要使用multiprocess的Manager类
if __name__=='__main__': manager = multiprocessing.Manager() # 父进程创建Queue,并传给各个子进程: q = manager.Queue() p = Pool() pw = p.apply_async(write,args=(q,)) time.sleep(0.5) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'
这样这个队列对象就可以在父进程与子进程间通信,不用池则不需要Manager,以后再扩展multiprocess中的Manager类吧
关于锁的应用,在不同程序间如果有同时对同一个队列操作的时候,为了避免错误,可以在某个函数操作队列的时候给它加把锁,这样在同一个时间内则只能有一个子进程对队列进行操作,锁也要在manager对象中的锁
#coding:gbk from multiprocessing import Process,Queue,Pool import multiprocessing import os, time, random # 写数据进程执行的代码: def write(q,lock): lock.acquire() #加上锁 for value in ['A', 'B', 'C']: print 'Put %s to queue...' % value q.put(value) lock.release() #释放锁 # 读数据进程执行的代码: def read(q): while True: if not q.empty(): value = q.get(False) print 'Get %s from queue.' % value time.sleep(random.random()) else: break if __name__=='__main__': manager = multiprocessing.Manager() # 父进程创建Queue,并传给各个子进程: q = manager.Queue() lock = manager.Lock() #初始化一把锁 p = Pool() pw = p.apply_async(write,args=(q,lock)) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'
相关推荐
-
python基于queue和threading实现多线程下载实例
本文实例讲述了python基于queue和threading实现多线程下载的方法,分享给大家供大家参考.具体方法如下: 主代码如下: #download worker queue_download = Queue.Queue(0) DOWNLOAD_WORKERS = 20 for i in range(DOWNLOAD_WORKERS): DownloadWorker(queue_download).start() #start a download worker for md5 in MD5
-
Python中使用Queue和Condition进行线程同步的方法
Queue模块保持线程同步 利用Queue对象先进先出的特性,将每个生产者的数据一次存入队列,而每个消费者将依次从队列中取出数据 import threading # 导入threading模块 import Queue # 导入Queue模块 class Producer(threading.Thread):# 定义生产者类 def __init__(self,threadname): threading.Thread.__init__(self,name = threadname) def
-
python使用Queue在多个子进程间交换数据的方法
本文实例讲述了python使用Queue在多个子进程间交换数据的方法.分享给大家供大家参考.具体如下: 这里将Queue作为中间通道进行数据传递,Queue是线程和进程安全的 from multiprocessing import Process, Queue def f(q): q.put([42, None, 'hello']) if __name__ == '__main__': q = Queue() p = Process(target=f, args=(q,)) p.start()
-

Python多进程通信Queue、Pipe、Value、Array实例
queue和pipe的区别: pipe用来在两个进程间通信.queue用来在多个进程间实现通信. 此两种方法为所有系统多进程通信的基本方法,几乎所有的语言都支持此两种方法. 1)Queue & JoinableQueue queue用来在进程间传递消息,任何可以pickle-able的对象都可以在加入到queue. multiprocessing.JoinableQueue 是 Queue的子类,增加了task_done()和join()方法. task_done()用来告诉queue一个tas
-
Python Queue模块详解
Python中,队列是线程间最常用的交换数据的形式.Queue模块是提供队列操作的模块,虽然简单易用,但是不小心的话,还是会出现一些意外. 创建一个"队列"对象 import Queue q = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现.队列长度可为无限或者有限.可通过Queue的构造函数的可选参数maxsize来设定队列长度.如果maxsize小于1就表示队列长度无限. 将一个值放入队列中 q.put(10) 调用队列对象的p
-
Python Queue模块详细介绍及实例
Python Queue模块 Python中,队列是线程间最常用的交换数据的形式.Queue模块是提供队列操作的模块,虽然简单易用,但是不小心的话,还是会出现一些意外. 创建一个"队列"对象 import Queue q = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现.队列长度可为无限或者有限.可通过Queue的构造函数的可选参数maxsize来设定队列长度.如果maxsize小于1就表示队列长度无限. 将一个值放入队列中 q.p
-
简单谈谈python中的Queue与多进程
最近接触一个项目,要在多个虚拟机中运行任务,参考别人之前项目的代码,采用了多进程来处理,于是上网查了查python中的多进程 一.先说说Queue(队列对象) Queue是python中的标准库,可以直接import 引用,之前学习的时候有听过著名的"先吃先拉"与"后吃先吐",其实就是这里说的队列,队列的构造的时候可以定义它的容量,别吃撑了,吃多了,就会报错,构造的时候不写或者写个小于1的数则表示无限多 import Queue q = Queue.Queue(10
-
简单谈谈Python中的json与pickle
这是用于序列化的两个模块: • json: 用于字符串和python数据类型间进行转换 • pickle: 用于python特有的类型和python的数据类型间进行转换 Json 模块提供了四个功能:dumps.dump.loads.load pickle 模块提供了四个功能:dumps.dump.loads.load import pickle data = {'k1':123, 'k2':888} #dumps可以将数据类型转换成只有python才认识的字符串 p_str = pickle.
-
简单谈谈python中的语句和语法
python程序结构 python"一切皆对象",这是接触python听到最多的总结了.在python中最基层的单位应该就是对象了,对象需要靠表达式建立处理,而表达式往往存在于语句中,多条语句组成代码块,多个代码块再组成一整个程序.python的核心其实是由语句和表达式组成.所以在这里简单探讨一下python中的语句和表达式. 因为以后可能会接触到两个版本的python,所以这里讲一讲python2与python3的语句差异: 1.python2中没有nolocal语句. 2.prin
-
简单谈谈python中的lambda表达式
最近在coding时发现使用lambda还是有诸多优点的,很多时候代码更整洁,更pythonic,所以在此简单总结一下 1.lambda是什么 举个简单的例子: func = lambda x: x*x def func(x): return x*x 两个func的定义是完全相同的,那两种函数定义方法配合map使用,将list中所有元素求平方,代码会是什么样的, def func(x): return x*x map(func, [i for i in range(10)]) map(lambd
-
简单谈谈python中的多进程
进程是由系统自己管理的. 1:最基本的写法 from multiprocessing import Pool def f(x): return x*x if __name__ == '__main__': p = Pool(5) print(p.map(f, [1, 2, 3])) [1, 4, 9] 2.实际上是通过os.fork的方法产生进程的 unix中,所有进程都是通过fork的方法产生的. multiprocessing Process os info(title): title ,
-
简单谈谈Python中的反转字符串问题
按单词反转字符串是一道很常见的面试题.在Python中实现起来非常简单. def reverse_string_by_word(s): lst = s.split() # split by blank space by default return ' '.join(lst[::-1]) s = 'Power of Love' print reverse_string_by_word(s) # Love of Power s = 'Hello World!' print reverse_stri
-
简单谈谈Python中的闭包
Python中的闭包 前几天又有人留言,关于其中一个闭包和re.sub的使用不太清楚.我在我们搜索了下,发现没有写过闭包相关的东西,所以决定总结一下,完善Python的内容. 1. 闭包的概念 首先还得从基本概念说起,什么是闭包呢?来看下维基上的解释: 复制代码 代码如下: 在计算机科学中,闭包(Closure)是词法闭包(Lexical Closure)的简称,是引用了自由变量的函数.这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外.所以,有另一种说法认为闭包是由函
-
简单谈谈Python中的模块导入
目录 模块与包 __import__ 模块缓存 imp 与 importlib 模块 惰性导入 总结 参考资料 本文不讨论 Python 的导入机制(底层实现细节),仅讨论模块与包,以及导入语句相关的概念.通常,导入模块都是使用如下语句: import ... import ... as ... from ... import ... from ... import ... as ... 一般情况下,使用以上语句导入模块已经够用的.但是在一些特殊场景中,可能还需要其他的导入方式.例如 Pytho
-
简单谈谈Python中函数的可变参数
前言 在Python中定义函数,可以用必选参数.默认参数.可变参数和关键字参数,这4种参数都可以一起使用,或者只用其中某些,但是请注意,参数定义的顺序必须是:必选参数.默认参数.可变参数和关键字参数. 可变参数( * ) 可变参数,顾名思义,它的参数是可变的,比如列表.字典等.如果我们需要函数处理可变数量参数的时候,就可以使用可变参数. 我们在查看很多Python源码时,经常会看到 某函数(*参数1, **参数2)这样的函数定义,这个*参数和**参数就是可变参数,一时会让人有点费解.其实只要把函
-
简单谈谈Python中的几种常见的数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值.但是,计算机能处理的远不止数值,还可以处理文本.图形.音频.视频.网页等各种各样的数据,不同的数据,需要定义不同的数据类型.在Python中,能够直接处理的数据类型有以下几种: 一.整数 Python可以处理任意大小的整数,当然包括负整数,在Python程序中,整数的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等. 计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0