使用php方法curl抓取AJAX异步内容思路分析及代码分享
其实抓ajax异步内容的页面和抓普通的页面区别不大。ajax只不过是做了一次异步的http请求,只要使用firebug类似的工具,找到请求的后端服务url和传值的参数,然后对该url传递参数进行抓取即可。
利用Firebug的网络工具
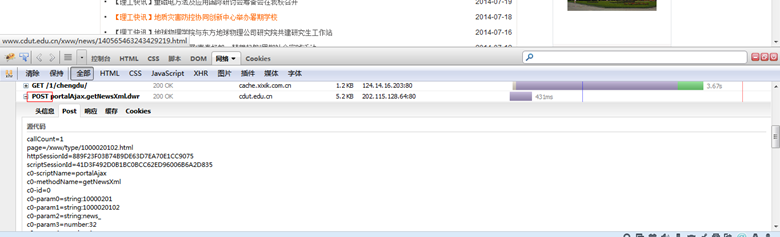
如果抓去的是页面,则内容中没有显示的数据,是一堆JS代码。
Code
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr/call/plaincall/portalAjax.getNewsXml.dwr";
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
相关推荐
-
php使用curl和正则表达式抓取网页数据示例
利用curl和正则表达式做的一个针对磨铁中文网非vip章节的小说抓取器,支持输入小说ID下载小说. 依赖项:curl 可以简单的看下,里面用到了curl ,正则表达式,ajax等技术,适合新手看看.在本地测试,必须保证联网并且确保php开启curl的mode SpiderTools.class.php 复制代码 代码如下: <?php session_start(); //封装成类 开启这些自动抓取文章 #header("Refresh:30;http://www.test.co
-
php curl抓取网页的介绍和推广及使用CURL抓取淘宝页面集成方法
php的curl可以用来实现抓取网页,分析网页数据用, 简洁易用, 这里介绍其函数等就不详细描述, 放上代码看看: 只保留了其中几个主要的函数. 实现模拟登陆, 其中可能涉及到session捕获, 然后前后页面涉及参数提供形式. libcurl主要功能就是用不同的协议连接和沟通不同的服务器~也就是相当封装了的sock PHP 支持libcurl(允许你用不同的协议连接和沟通不同的服务器)., libcurl当前支持http, https, ftp, gopher, telnet, dict, f
-
php使用curl代理实现抓取数据的方法
本文实例讲述了php使用curl代理实现抓取数据的方法.分享给大家供大家参考,具体如下: <?php define ( 'IS_PROXY', true ); //是否启用代理 function async_get_url($url_array, $wait_usec = 0) { if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array()
-

php通过curl添加cookie伪造登陆抓取数据的方法
本文实例讲述了php通过curl添加cookie伪造登陆抓取数据的方法.分享给大家供大家参考,具体如下: 有的网页必须登陆才能看到,这个时候想要抓取信息必须在header里面传递cookie值才能获取 1.首先登陆网站,打开firebug就能看到对应的cookie把这些cookie拷贝出来就能使用了 2. <?php header("Content-type:text/html;Charset=utf8"); $ch =curl_init(); curl_setopt($ch,C
-
PHP curl 抓取AJAX异步内容示例
其实抓ajax异步内容的页面和抓普通的页面区别不大.ajax只不过是做了一次异步的http请求,只要使用firebug类似的工具,找到请求的后端服务url和传值的参数,然后对该url传递参数进行抓取即可. 利用Firebug的网络工具 如果抓去的是页面,则内容中没有显示的数据,是一堆JS代码. Code $cookie_file=tempnam('./temp','cookie'); $ch = curl_init(); $url1 = "http://www.cdut.edu.cn/defau
-
PHP curl实现抓取302跳转后页面的示例
PHP的CURL正常抓取页面程序如下: $url = 'http://www.baidu.com'; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_VERBOSE, true); curl_setopt($ch, CURLOPT_HEADER, true); curl_setopt($ch, CURLOPT_NOBODY, true); curl_setopt($ch, CURLO
-
php下通过curl抓取yahoo boss 搜索结果的实现代码
1.编写curl类,进行网页内容抓取 复制代码 代码如下: class CurlUtil { private $curl; private $timeout = 10; /** * 初始化curl对象 */ public function __construct() { $this->curl = curl_init(); curl_setopt($this->curl, CURLOPT_RETURNTRANSFER, 1); curl_setopt($this->curl, CURLO
-
php使用curl抓取qq空间的访客信息示例
config.php 复制代码 代码如下: <?phpdefine('APP_DIR', dirname(__FILE__));define('COOKIE_FILE', APP_DIR . '/app.cookie.txt'); //会话记录文件define('VISITOR_CAPTURE_INTERVAL', 3); //QQ采集间隔define('VISITOR_DATA_UPLOAD_INTERVAL', '');define('THIS_TIME', time()); define(
-
PHP中使用CURL伪造来路抓取页面或文件
复制代码 代码如下: // 初始化 $curl = curl_init(); // 要访问的网址 curl_setopt($curl, CURLOPT_URL, 'http://asen.me/'); // 设置来路 curl_setopt($curl, CURLOPT_REFERER, 'http://google.com/'); // 不直接输入内容 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 降结果保存在$result中 $resul
-
使用PHP curl模拟浏览器抓取网站信息
官方解释curl是一个利用URL语法在命令行方式下工作的文件传输工具.curl是一个利用URL语法在命令行方式下工作的文件传输工具.它支持很多协议:FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 以及 LDAP.curl同样支持HTTPS认证,HTTP POST方法, HTTP PUT方法, FTP上传, kerberos认证, HTTP上传, 代理服务器, cookies, 用户名/密码认证, 下载文件断点续传,上载文件断点续传, http
-
php利用curl抓取新浪微博内容示例
很多人都喜欢在网站上DIY自己的微博,所以我也写了一个.这里直接抓取了新浪微博工具中的微博秀地址. 复制代码 代码如下: <?php set_time_limit(0); $url="http://widget.weibo.com/weiboshow/index.php?language=&width=0&height=550&fansRow=2&ptype=1&speed=0&skin=1&isTitle=1&nobor
-
PHP使用CURL实现多线程抓取网页
PHP 利用 Curl Functions 可以完成各种传送文件操作,比如模拟浏览器发送GET,POST请求等等,受限于php语言本身不支持多线程,所以开发爬虫程序效率并不高,这时候往往需 要借助Curl Multi Functions 它可以实现并发多线程的访问多个url地址.既然 Curl Multi Function如此强大,能否用 Curl Multi Functions 来写并发多线程下载文件呢,当然可以,下面给出我的代码: 代码1:将获得的代码直接写入某个文件 <?php $urls
-
PHP CURL模拟登录新浪微博抓取页面内容 基于EaglePHP框架开发
复制代码 代码如下: /** * CURL请求 * @param String $url 请求地址 * @param Array $data 请求数据 */ function curlRequest($url,$data='',$cookieFile=''){ $ch = curl_init(); $option = array( CURLOPT_URL => $url, CURLOPT_HEADER =>0, CURLOPT_RETURNTRANSFER => 1, ); if($co