Python微信公众号开发平台
上大学的时候,对微信公众号开发浅尝辄止的玩了一下,感觉还是挺有意思的。
http://www.jb51.net/article/133677.htm后来服务器到期了,也就搁置了。由于发布web程序,使用PHP很顺手,就使用了PHP作为开发语言。但是其实微信公众号的开发和语言关联并不大,流程,原理上都是一致的。
快要做毕设了,想着到时候应该会部署一些代码到服务器上,进行长期的系统构建。所以趁着还是学生,就买了阿里云的学生机。买了之后,就想着玩点什么,于是微信公众号的开发,就又提上了日程。但是这次,我不打算使用PHP了,感觉局限性相对于Python而言,稍微有点大。
使用Python的话,可以灵活的部署一些爬虫类程序,和用户交互起来也会比较方便。可拓展性感觉也比较的高,于是就选它了。
服务器配置这部分属于是比较基础的,不太明白的可以看看我之前的那个博客,还算是比较的详细。今天就只是对核心代码做下介绍好了。
项目目录
root@aliyun:/var/www/html/wx/py# ls *.py api.py dispatcher.py robot.py root@aliyun:/var/www/html/wx/py#
api.py
这个文件相当于是一个关卡,涉及token的验证,和服务的支持。
# -*- coding:utf-8 -*- #中文编码
import sys
reload(sys) # 不加这部分处理中文还是会出问题
sys.setdefaultencoding('utf-8')
import time
from flask import Flask, request, make_response
import hashlib
import json
import xml.etree.ElementTree as ET
from dispatcher import *
app = Flask(__name__)
app.debug = True
@app.route('/') # 默认网址
def index():
return 'Index Page'
@app.route('/wx', methods=['GET', 'POST'])
def wechat_auth(): # 处理微信请求的处理函数,get方法用于认证,post方法取得微信转发的数据
if request.method == 'GET':
token = '你自己设置好的token'
data = request.args
signature = data.get('signature', '')
timestamp = data.get('timestamp', '')
nonce = data.get('nonce', '')
echostr = data.get('echostr', '')
s = [timestamp, nonce, token]
s.sort()
s = ''.join(s)
if (hashlib.sha1(s).hexdigest() == signature):
return make_response(echostr)
else:
rec = request.stream.read() # 接收消息
dispatcher = MsgDispatcher(rec)
data = dispatcher.dispatch()
with open("./debug.log", "a") as file:
file.write(data)
file.close()
response = make_response(data)
response.content_type = 'application/xml'
return response
if __name__ == '__main__':
app.run(host="0.0.0.0", port=80)
dispatcher.py
这个文件是整个服务的核心,用于识别用户发来的消息类型,然后交给不同的handler来处理,并将运行的结果反馈给前台,发送给用户。消息类型这块,在微信的开发文档上有详细的介绍,因此这里就不再过多的赘述了。
#! /usr/bin python
# coding: utf8
import sys
reload(sys)
sys.setdefaultencoding("utf8")
import time
import json
import xml.etree.ElementTree as ET
from robot import *
class MsgParser(object):
"""
用于解析从微信公众平台传递过来的参数,并进行解析
"""
def __init__(self, data):
self.data = data
def parse(self):
self.et = ET.fromstring(self.data)
self.user = self.et.find("FromUserName").text
self.master = self.et.find("ToUserName").text
self.msgtype = self.et.find("MsgType").text
# 纯文字信息字段
self.content = self.et.find("Content").text if self.et.find("Content") is not None else ""
# 语音信息字段
self.recognition = self.et.find("Recognition").text if self.et.find("Recognition") is not None else ""
self.format = self.et.find("Format").text if self.et.find("Format") is not None else ""
self.msgid = self.et.find("MsgId").text if self.et.find("MsgId") is not None else ""
# 图片
self.picurl = self.et.find("PicUrl").text if self.et.find("PicUrl") is not None else ""
self.mediaid = self.et.find("MediaId").text if self.et.find("MediaId") is not None else ""
# 事件
self.event = self.et.find("Event").text if self.et.find("Event") is not None else ""
return self
class MsgDispatcher(object):
"""
根据消息的类型,获取不同的处理返回值
"""
def __init__(self, data):
parser = MsgParser(data).parse()
self.msg = parser
self.handler = MsgHandler(parser)
def dispatch(self):
self.result = "" # 统一的公众号出口数据
if self.msg.msgtype == "text":
self.result = self.handler.textHandle()
elif self.msg.msgtype == "voice":
self.result = self.handler.voiceHandle()
elif self.msg.msgtype == 'image':
self.result = self.handler.imageHandle()
elif self.msg.msgtype == 'video':
self.result = self.handler.videoHandle()
elif self.msg.msgtype == 'shortvideo':
self.result = self.handler.shortVideoHandle()
elif self.msg.msgtype == 'location':
self.result = self.handler.locationHandle()
elif self.msg.msgtype == 'link':
self.result = self.handler.linkHandle()
elif self.msg.msgtype == 'event':
self.result = self.handler.eventHandle()
return self.result
class MsgHandler(object):
"""
针对type不同,转交给不同的处理函数。直接处理即可
"""
def __init__(self, msg):
self.msg = msg
self.time = int(time.time())
def textHandle(self, user='', master='', time='', content=''):
template = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[{}]]></Content>
</xml>
"""
# 对用户发过来的数据进行解析,并执行不同的路径
try:
response = get_response_by_keyword(self.msg.content)
if response['type'] == "image":
result = self.imageHandle(self.msg.user, self.msg.master, self.time, response['content'])
elif response['type'] == "music":
data = response['content']
result = self.musicHandle(data['title'], data['description'], data['url'], data['hqurl'])
elif response['type'] == "news":
items = response['content']
result = self.newsHandle(items)
# 这里还可以添加更多的拓展内容
else:
response = get_turing_response(self.msg.content)
result = template.format(self.msg.user, self.msg.master, self.time, response)
#with open("./debug.log", 'a') as f:
# f.write(response['content'] + '~~' + result)
# f.close()
except Exception as e:
with open("./debug.log", 'a') as f:
f.write("text handler:"+str(e.message))
f.close()
return result
def musicHandle(self, title='', description='', url='', hqurl=''):
template = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[music]]></MsgType>
<Music>
<Title><![CDATA[{}]]></Title>
<Description><![CDATA[{}]]></Description>
<MusicUrl><![CDATA[{}]]></MusicUrl>
<HQMusicUrl><![CDATA[{}]]></HQMusicUrl>
</Music>
<FuncFlag>0</FuncFlag>
</xml>
"""
response = template.format(self.msg.user, self.msg.master, self.time, title, description, url, hqurl)
return response
def voiceHandle(self):
response = get_turing_response(self.msg.recognition)
result = self.textHandle(self.msg.user, self.msg.master, self.time, response)
return result
def imageHandle(self, user='', master='', time='', mediaid=''):
template = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[{}]]></MediaId>
</Image>
</xml>
"""
if mediaid == '':
response = self.msg.mediaid
else:
response = mediaid
result = template.format(self.msg.user, self.msg.master, self.time, response)
return result
def videoHandle(self):
return 'video'
def shortVideoHandle(self):
return 'shortvideo'
def locationHandle(self):
return 'location'
def linkHandle(self):
return 'link'
def eventHandle(self):
return 'event'
def newsHandle(self, items):
# 图文消息这块真的好多坑,尤其是<![CDATA[]]>中间不可以有空格,可怕极了
articlestr = """
<item>
<Title><![CDATA[{}]]></Title>
<Description><![CDATA[{}]]></Description>
<PicUrl><![CDATA[{}]]></PicUrl>
<Url><![CDATA[{}]]></Url>
</item>
"""
itemstr = ""
for item in items:
itemstr += str(articlestr.format(item['title'], item['description'], item['picurl'], item['url']))
template = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>{}</ArticleCount>
<Articles>{}</Articles>
</xml>
"""
result = template.format(self.msg.user, self.msg.master, self.time, len(items), itemstr)
return result
robot.py
这个文件属于那种画龙点睛性质的。
#!/usr/bin python
#coding: utf8
import requests
import json
def get_turing_response(req=""):
url = "http://www.tuling123.com/openapi/api"
secretcode = "嘿嘿,这个就不说啦"
response = requests.post(url=url, json={"key": secretcode, "info": req, "userid": 12345678})
return json.loads(response.text)['text'] if response.status_code == 200 else ""
def get_qingyunke_response(req=""):
url = "http://api.qingyunke.com/api.php?key=free&appid=0&msg={}".format(req)
response = requests.get(url=url)
return json.loads(response.text)['content'] if response.status_code == 200 else ""
# 简单做下。后面慢慢来
def get_response_by_keyword(keyword):
if '团建' in keyword:
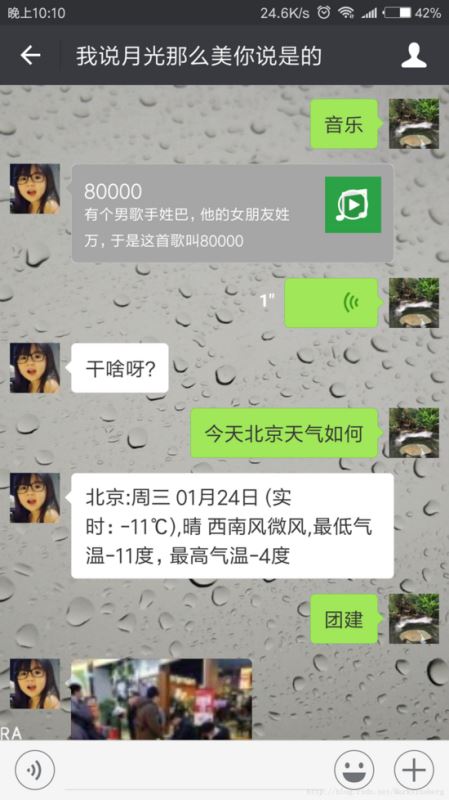
result = {"type": "image", "content": "3s9Dh5rYdP9QruoJ_M6tIYDnxLLdsQNCMxkY0L2FMi6HhMlNPlkA1-50xaE_imL7"}
elif 'music' in keyword or '音乐' in keyword:
musicurl='http://204.11.1.34:9999/dl.stream.qqmusic.qq.com/C400001oO7TM2DE1OE.m4a?vkey=3DFC73D67AF14C36FD1128A7ABB7247D421A482EBEDA17DE43FF0F68420032B5A2D6818E364CB0BD4EAAD44E3E6DA00F5632859BEB687344&guid=5024663952&uin=1064319632&fromtag=66'
result = {"type": "music", "content": {"title": "80000", "description":"有个男歌手姓巴,他的女朋友姓万,于是这首歌叫80000", "url": musicurl, "hqurl": musicurl}}
elif '关于' in keyword:
items = [{"title": "关于我", "description":"喜欢瞎搞一些脚本", "picurl":"https://avatars1.githubusercontent.com/u/12973402?s=460&v=4", "url":"https://github.com/guoruibiao"},
{"title": "我的博客", "description":"收集到的,瞎写的一些博客", "picurl":"http://avatar.csdn.net/0/8/F/1_marksinoberg.jpg", "url":"http://blog.csdn.net/marksinoberg"},
{"title": "薛定谔的:dog:", "description": "副标题有点奇怪,不知道要怎么设置比较好","picurl": "https://www.baidu.com/img/bd_logo1.png","url": "http://www.baidu.com"}
]
result = {"type": "news", "content": items}
else:
result = {"type": "text", "content": "可以自由进行拓展"}
return result
其实这看起来是一个文件,其实可以拓展为很多的方面。
如果想通过公众号来监控服务器的运行情况,就可以添加一个对服务器负载的监控的脚本;
如果想做一些爬虫,每天抓取一些高质量的文章,然后通过公众号进行展示。
不方便使用电脑的情况下,让公众号调用一些命令也可以算是曲线救国的一种方式。
等等吧,其实有多少想法,就可以用Python进行事先。然后通过公众号这个平台进行展示。
易错点
在从PHP重构为Python的过程中,我其实也是遇到了一些坑的。下面总结下,如果恰好能帮助到遇到同样问题的你,那我这篇文章也算是没有白写了。
微信公众号的开发,其实关键就在于理解这个工作的模式。大致有这么两条路。
用户把消息发送到微信公众平台上,平台把信息拼接组装成XML发到我们自己的服务器。(通过一系列的认证,校验,让平台知道,我们的服务是合法的),然后服务器将XML进行解析,处理。
我们的服务器解析处理完成后,将数据再次拼接组装成XML,发给微信公众平台,平台帮我们把数据反馈给对应的用户。
这样,一个交互就算是完成了。在这个过程中,有下面几个容易出错的地方。
token校验: token的校验是一个get方式的请求。通过代码我们也可以看到,就是对singature的校验,具体看代码就明白了。
XML数据的解析,对于不同的消息,记得使用不同的格式。其中很容易出错的就是格式不规范。 <!CDATA[[]]> 中括号之间最好不要有空格,不然定位起错误还是很麻烦的。
服务的稳定性。这里用的web框架是flask,小巧精良。但是对并发的支持性不是很好,对此可以使用uwsgi和Nginx来实现一个更稳定的服务。如果就是打算自己玩一玩,通过命令行启用(如python api.py)就不是很保险了,因为很有可能会因为用户的一个奇怪的输入导致整个服务垮掉,建议使用nohup的方式,来在一定程度上保证服务的质量。
结果演示
目前这个公众号支持文字,语音,图片,图文等消息类型。示例如下。

总结
在将公众号从PHP重构为Python的过程中,遇到了一些问题,然后通过不断的摸索,慢慢的也把问题解决了。其实有时候就是这样,只有不断的发现问题,才能不断的提升自己。
这里其实并没有深入的去完善,重构后的微信公众号其实能做的还有很多,毕竟就看敢不敢想嘛。好了,就先扯这么多了,后面如果有好的思路和实现,再回来更新好了。
以上所述是小编给大家介绍的Python微信公众号开发平台,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- 使用 Python 实现微信公众号粉丝迁移流程
- python爬虫_微信公众号推送信息爬取的实例
- Python实现的微信公众号群发图片与文本消息功能实例详解
- python实现给微信公众号发送消息的方法
- Python开发之快速搭建自动回复微信公众号功能
- python定时利用QQ邮件发送天气预报的实例
- 使用Python发送邮件附件以定时备份MySQL的教程
- python3实现公众号每日定时发送日报和图片
相关推荐
-

python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
Python开发之快速搭建自动回复微信公众号功能
在之前的一篇文章 Python利用 AIML 和 Tornado 搭建聊天机器人微信订阅号 中用 aiml 实现了一个简单的英文聊天机器人订阅号.但是只能处理英文消息,现在用 图灵机器人 来实现一个中文的聊天机器人订阅号. 这里主要介绍如何利用 Python 的 Tornado Web框架以及wechat-python-sdk微信公众平台 Python 开发包来快速搭建微信公众号. 完整的公众号代码 GitHub 地址:green ,由于目前此公众号有一些功能正在开发中,此完整代码会与下文所描述
-
使用 Python 实现微信公众号粉丝迁移流程
近日,因公司业务需要,需将原两个公众号合并为一个,即要将其中一个公众号(主要是粉丝)迁移到另一个公众号.按微信规范,同一用户在不同公众号内的 openid 是不同的,我们的业务系统不例外地记录了用户的 openid,因此,涉及到两个公众号的 openid 的转换.幸好,微信公众号平台在账号迁移描述提供了方法和API供调用,详见: http://kf.qq.com/faq/170221aUnmmU170221eUZJNf.html 这里使用 Python 写个程序来完成,简单快捷,主要知识点有:
-
使用Python发送邮件附件以定时备份MySQL的教程
最近迁移了wordpress,系统升级为CentOS 6,很奇怪的一个问题,在原来CentOS 5.8下用的很正常的定时备份数据库并通过邮件发送的脚本不能发送附件,其他都正常,邮件内容也是uuencode生成的文件编码,但是就是不产生附件.而且找不出原因,望有知道的不吝赐教. 为了解决这一问题,我用Python写了一个mail客户端,可以发送附件,是一个命令行程序.废话不多说.贴代码: #!/usr/bin/env python #-*- coding: utf8 -*- ''' #======
-
python3实现公众号每日定时发送日报和图片
本文实例为大家分享了python3实现公众号每日定时发送的具体代码,供大家参考,具体内容如下 步骤是这样:先申请公众号,找到接口文件.看了之后发现主要是通过corpid(企业秘钥)和corpsecret(应用秘钥)获得登录token,通过这个token进入各个url操作. 我这个用的是企业微信,所以有部门.其他公众号也类似.结果如下: # -*- coding:utf-8 -*- import requests import json import time url0 = 'https://qy
-
Python实现的微信公众号群发图片与文本消息功能实例详解
本文实例讲述了Python实现的微信公众号群发图片与文本消息功能.分享给大家供大家参考,具体如下: 在微信公众号开发中,使用api都要附加access_token内容.因此,首先需要获取access_token.如下: #获取微信access_token def get_token(): payload_access_token={ 'grant_type':'client_credential', 'appid':'xxxxxxxxxxxxx', 'secret':'xxxxxxxxxxxxx
-
python定时利用QQ邮件发送天气预报的实例
大致介绍 好久没有写博客了,正好今天有时间把前几天写的利用python定时发送QQ邮件记录一下 1.首先利用request库去请求数据,天气预报使用的是和风天气的API(www.heweather.com/douments/api/s6/weather-forecast) 2.利用python的jinja2模块写一个html模板,用于展示数据 3.python的email构建邮件,smtplib发送邮件 4.最后使用crontab定时执行python脚本 涉及的具体知识可以去看文档,本文主要就是
-
python实现给微信公众号发送消息的方法
本文实例讲述了python实现给微信公众号发送消息的方法.分享给大家供大家参考,具体如下: 现在通过发微信公众号信息来做消息通知和告警已经很普遍了.最常见的就是运维通过zabbix调用shell脚本给微信发消息,起到告警的作用.当要发送的信息较多,而且希望按照指定格式显示的好看一点的时候,shell处理起来,个人感觉不太方便.于是我用Python重写了发微信的功能. #coding:utf-8 import urllib2 import json import sys def getMsg():
-
Python微信公众号开发平台
上大学的时候,对微信公众号开发浅尝辄止的玩了一下,感觉还是挺有意思的. http://www.jb51.net/article/133677.htm后来服务器到期了,也就搁置了.由于发布web程序,使用PHP很顺手,就使用了PHP作为开发语言.但是其实微信公众号的开发和语言关联并不大,流程,原理上都是一致的. 快要做毕设了,想着到时候应该会部署一些代码到服务器上,进行长期的系统构建.所以趁着还是学生,就买了阿里云的学生机.买了之后,就想着玩点什么,于是微信公众号的开发,就又提上了日程.但是这次,
-
python微信公众号开发简单流程
本文为大家分享了python微信公众号开发的简单过程,供大家参考,具体内容如下 网上有很多微信公众号的开发教程,但是都是好几年前的了,而且很多都是抄袭其他人的,内容几乎一模一样.真的无语了.只好自己总结一下开发的一些简单流程. 一.注册个微信公众号,这个就不详细说了. 二.登录后台,进入开发中的基本配置,配置下服务器 填写url和token,url是服务器的地址,token是自己定义的 三.登录服务器开发 网上很多教程用的什么新浪sae啊,webpy都是很久之前的.现在很多东西都变了,所以我没有
-
python微信公众号开发简单流程实现
本文为大家分享了python微信公众号开发的简单过程,供大家参考,具体内容如下 网上有很多微信公众号的开发教程,但是都是好几年前的了,而且很多都是抄袭其他人的,内容几乎一模一样.真的无语了.只好自己总结一下开发的一些简单流程. 一.注册个微信公众号,这个就不详细说了. 二.登录后台,进入开发中的基本配置,配置下服务器 填写url和token,url是服务器的地址,token是自己定义的 三.登录服务器开发 网上很多教程用的什么新浪sae啊,webpy都是很久之前的.现在很多东西都变了,所以我没有
-
微信公众号开发之微信公共平台消息回复类实例
本文实例讲述了微信公众号开发之微信公共平台消息回复类.分享给大家供大家参考.具体如下: 微信公众号开发代码我在网上看到了有不少,其实都是大同小义了都是参考官方给出的demo文件进行修改的,这里就给各位分享一个. 复制代码 代码如下: <?php /** * 微信公共平台消息回复类 * * */ class BBCweixin{ private $APPID="******"; private $APPSECRET="******"; /*
-
java微信公众号开发(搭建本地测试环境)
俗话说,工欲善其事,必先利其器.要做微信公众号开发,两样东西不可少,那就是要有一个用来测试的公众号,还有一个用来调式代码的开发环境. 测试公众号 微信公众号有订阅号.服务号.企业号,在注册的时候看到这样的信息,只有订阅号可以个人申请,服务号和企业号要有企业资质才可以.这里所说的微信公众号开发指的是订阅号和服务号. 另外,未认证的个人订阅号有一些接口是没有权限的,并且目前个人订阅号已不支持微信认证,也就是说个人订阅号无法调用一些高级的权限接口,下图就是一个未认证的个人订阅号所具备权限列表,像生成二
-
C#微信公众号开发之接收事件推送与消息排重的方法
本文实例讲述了C#微信公众号开发之接收事件推送与消息排重的方法.分享给大家供大家参考.具体分析如下: 微信服务器在5秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次.这样的话,问题就来了.有这样一个场景:当用户关注微信账号时,获取当前用户信息,然后将信息写到数据库中.类似于pc端网站的注册.可能由于这个关注事件中,我们需要处理的业务逻辑比较复杂.如送积分啊,写用户日志啊,分配用户组啊.等等--一系列的逻辑需要执行,或者网络环境比较复杂,无法保证5秒内响应当前用户的操作,那如果当操作尚未完
-
php微信公众号开发模式详解
学习步骤:分四章来讲述这部分内容,下面是每章的大致内容. 1.了解开发模式与编辑模式,开发前的一些准备. 2.开发模式用户.微信服务器.个人服务器是如何交互的.什么是接口. 3.各种接口功能的调用与实现. 4.js-SDK的调用 微信公众号开发两种模式:编辑模式和开发模式.编辑模式比较简单,你不需要操作任何的代码,只需要借助微信提供的功能来管理自己的微信公众号.这种方式开发的页面比较简单,主要用来实现文章的推送等功能.开发者模式则能通过自己的后台服务器与微信关注用户实现更多的交互作用,调用微信的
-
PHP微信公众号开发之微信红包实现方法分析
本文实例讲述了PHP微信公众号开发之微信红包实现方法.分享给大家供大家参考,具体如下: 这几天遇到了一个客户 要给他们的微信公众平台上添加微信现金红包功能,是个二次开发的功能,顺手百度一下,原来不复杂.就着手开发功能了.现将开发的过程和需求贴出来分享一下: 一.需求: 粉丝通过在客户的公众平台点击他们公司的订单,然后给这个订单返现五元,发到订单的这个微信号上. 二.开发想法: 1:先拿到关注这个粉丝的openid,openid是关注某个公众号的微信标识,这样就可以定位到这个人是订单的操作者了.
-
详解nodejs微信公众号开发——2.自动回复
上一篇文章:nodejs微信公众号开发(1)接入微信公众号,本篇文章将在此基础上实现简单的回复功能. 1. 接入代码的优化 之前我们简单粗暴的实现了微信公众号的接入,接入的代码直接写在了app.js文件里面,从项目开发的角度而言,不便于日后代码的维护,所以将这部分代码独立出来,按照koa的风格,写成一个中间件. 在根目录下新建wechat文件夹,新建generator.js文件, var sha1 = require('sha1'); module.exports = function(opts
-
详解nodejs微信公众号开发——3.封装消息响应模块
上一篇文章:nodejs微信公众号开发(2)自动回复,实现了简单的关注回复.采用拼接字符串的形式,并不是很方便,这里我们将其封装承接口. 1. ejs模板引擎 不使用拼接字符串的方式,那么模板引擎就是较好的选择.Nodejs开源模板的选择很多,程序中使用 EJS,有Classic ASP/PHP/JSP的经验用起EJS来的确可以很自然,也就是说,你能够在 <%...%> 块中安排 JavaScript 代码,利用最传统的方式 <%=输出变量%>(另外 <%-输出变量是不会对