scikit-learn线性回归,多元回归,多项式回归的实现
匹萨的直径与价格的数据
%matplotlib inline import matplotlib.pyplot as plt def runplt(): plt.figure() plt.title(u'diameter-cost curver') plt.xlabel(u'diameter') plt.ylabel(u'cost') plt.axis([0, 25, 0, 25]) plt.grid(True) return plt plt = runplt() X = [[6], [8], [10], [14], [18]] y = [[7], [9], [13], [17.5], [18]] plt.plot(X, y, 'k.') plt.show()
训练模型
from sklearn.linear_model import LinearRegression
import numpy as np
# 创建并拟合模型
model = LinearRegression()
model.fit(X, y)
print('预测一张12英寸匹萨价格:$%.2f' % model.predict(np.array([12]).reshape(-1, 1))[0])
预测一张12英寸匹萨价格:$13.68
一元线性回归假设解释变量和响应变量之间存在线性关系;这个线性模型所构成的空间是一个超平面(hyperplane)。
超平面是n维欧氏空间中余维度等于一的线性子空间,如平面中的直线、空间中的平面等,总比包含它的空间少一维。
在一元线性回归中,一个维度是响应变量,另一个维度是解释变量,总共两维。因此,其超平面只有一维,就是一条线。
上述代码中sklearn.linear_model.LinearRegression类是一个估计器(estimator)。估计器依据观测值来预测结果。在scikit-learn里面,所有的估计器都带有:
- fit()
- predict()
fit()用来分析模型参数,predict()是通过fit()算出的模型参数构成的模型,对解释变量进行预测获得的值。
因为所有的估计器都有这两种方法,所有scikit-learn很容易实验不同的模型。
一元线性回归模型:
y=α+βx
一元线性回归拟合模型的参数估计常用方法是:
- 普通最小二乘法(ordinary least squares )
- 线性最小二乘法(linear least squares)
首先,我们定义出拟合成本函数,然后对参数进行数理统计。
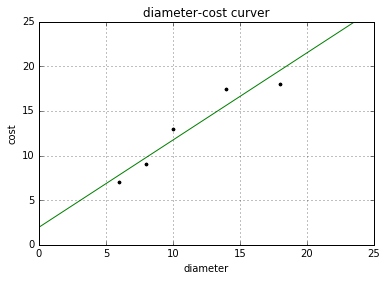
plt = runplt() plt.plot(X, y, 'k.') X2 = [[0], [10], [14], [25]] model = LinearRegression() model.fit(X, y) y2 = model.predict(X2) plt.plot(X, y, 'k.') plt.plot(X2, y2, 'g-') plt.show()
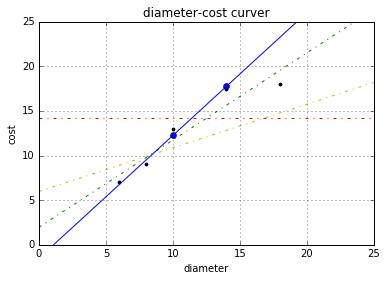
plt = runplt() plt.plot(X, y, 'k.') y3 = [14.25, 14.25, 14.25, 14.25] y4 = y2 * 0.5 + 5 model.fit(X[1:-1], y[1:-1]) y5 = model.predict(X2) plt.plot(X, y, 'k.') plt.plot(X2, y2, 'g-.') plt.plot(X2, y3, 'r-.') plt.plot(X2, y4, 'y-.') plt.plot(X2, y5, 'o-') plt.show()
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。后面我们会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。
模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:
plt = runplt() plt.plot(X, y, 'k.') X2 = [[0], [10], [14], [25]] model = LinearRegression() model.fit(X, y) y2 = model.predict(X2) plt.plot(X, y, 'k.') plt.plot(X2, y2, 'g-') # 残差预测值 yr = model.predict(X) for idx, x in enumerate(X): plt.plot([x, x], [y[idx], yr[idx]], 'r-') plt.show()
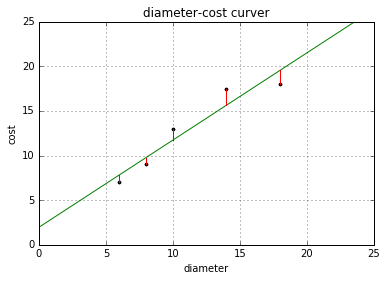
我们可以通过残差之和最小化实现最佳拟合,也就是说模型预测的值与训练集的数据最接近就是最佳拟合。对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)成本函数。就是让所有训练数据与模型的残差的平方之和最小化,如下所示:

其中, yi 是观测值, f(xi)f(xi) 是预测值。
import numpy as np
print('残差平方和: %.2f' % np.mean((model.predict(X) - y) ** 2))
残差平方和: 1.75
解一元线性回归的最小二乘法
通过成本函数最小化获得参数,我们先求相关系数 ββ 。按照频率论的观点,我们首先需要计算 xx 的方差和 xx 与 yy 的协方差。
方差是用来衡量样本分散程度的。如果样本全部相等,那么方差为0。方差越小,表示样本越集中,反正则样本越分散。方差计算公式如下:

Numpy里面有var方法可以直接计算方差,ddof参数是贝塞尔(无偏估计)校正系数(Bessel's correction),设置为1,可得样本方差无偏估计量。
print(np.var([6, 8, 10, 14, 18], ddof=1))
23.2
协方差表示两个变量的总体的变化趋势。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果两个变量不相关,则协方差为0,变量线性无关不表示一定没有其他相关性。协方差公式如下:

其中, x¯是直径 x的均值, xi的训练集的第 i个直径样本, y¯是价格y的均值, yi的训练集的第i个价格样本, n是样本数量。Numpy里面有cov方法可以直接计算方差。
import numpy as np print(np.cov([6, 8, 10, 14, 18], [7, 9, 13, 17.5, 18])[0][1])
22.65
现在有了方差和协方差,就可以计算相关系统 β 了。

算出β后,我们就可以计算α了:

将前面的数据带入公式就可以求出α了:

模型评估
前面我们用学习算法对训练集进行估计,得出了模型的参数。有些度量方法可以用来评估预测效果,我们用R方(r-squared)评估匹萨价格预测的效果。R方也叫确定系数(coefficient of determination),表示模型对现实数据拟合的程度。计算R方的方法有几种。一元线性回归中R方等于皮尔逊积矩相关系数(Pearson product moment correlation coefficient或Pearson's r)的平方。种方法计算的R方一定介于0~1之间的正数。其他计算方法,包括scikit-learn中的方法,不是用皮尔逊积矩相关系数的平方计算的,因此当模型拟合效果很差的时候R方会是负值。下面我们用scikit-learn方法来计算R方。

R方是0.6620说明测试集里面过半数的价格都可以通过模型解释。现在,让我们用scikit-learn来验证一下。LinearRegression的score方法可以计算R方:
# 测试集 X_test = [[8], [9], [11], [16], [12]] y_test = [[11], [8.5], [15], [18], [11]] model = LinearRegression() model.fit(X, y) model.score(X_test, y_test)
0.66200528638545164
多元回归
from sklearn.linear_model import LinearRegression
X = [[6, 2], [8, 1], [10, 0], [14, 2], [18, 0]]
y = [[7], [9], [13], [17.5], [18]]
model = LinearRegression()
model.fit(X, y)
X_test = [[8, 2], [9, 0], [11, 2], [16, 2], [12, 0]]
y_test = [[11], [8.5], [15], [18], [11]]
predictions = model.predict(X_test)
for i, prediction in enumerate(predictions):
print('Predicted: %s, Target: %s' % (prediction, y_test[i]))
print('R-squared: %.2f' % model.score(X_test, y_test))
Predicted: [ 10.06250019], Target: [11]
Predicted: [ 10.28125019], Target: [8.5]
Predicted: [ 13.09375019], Target: [15]
Predicted: [ 18.14583353], Target: [18]
Predicted: [ 13.31250019], Target: [11]
R-squared: 0.77
多项式回归
上例中,我们假设解释变量和响应变量的关系是线性的。真实情况未必如此。下面我们用多项式回归,一种特殊的多元线性回归方法,增加了指数项。现实世界中的曲线关系都是通过增加多项式实现的,其实现方式和多元线性回归类似。本例还用一个解释变量,匹萨直径。让我们用下面的数据对两种模型做个比较:
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
X_train = [[6], [8], [10], [14], [18]]
y_train = [[7], [9], [13], [17.5], [18]]
X_test = [[6], [8], [11], [16]]
y_test = [[8], [12], [15], [18]]
# 建立线性回归,并用训练的模型绘图
regressor = LinearRegression()
regressor.fit(X_train, y_train)
xx = np.linspace(0, 26, 100)
yy = regressor.predict(xx.reshape(xx.shape[0], 1))
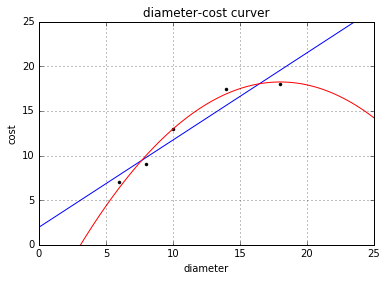
plt = runplt()
plt.plot(X_train, y_train, 'k.')
plt.plot(xx, yy)
quadratic_featurizer = PolynomialFeatures(degree=2)
X_train_quadratic = quadratic_featurizer.fit_transform(X_train)
X_test_quadratic = quadratic_featurizer.transform(X_test)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(X_train_quadratic, y_train)
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), 'r-')
plt.show()
print(X_train)
print(X_train_quadratic)
print(X_test)
print(X_test_quadratic)
print('1 r-squared', regressor.score(X_test, y_test))
print('2 r-squared', regressor_quadratic.score(X_test_quadratic, y_test))
[[6], [8], [10], [14], [18]]
[[ 1. 6. 36.]
[ 1. 8. 64.]
[ 1. 10. 100.]
[ 1. 14. 196.]
[ 1. 18. 324.]]
[[6], [8], [11], [16]]
[[ 1. 6. 36.]
[ 1. 8. 64.]
[ 1. 11. 121.]
[ 1. 16. 256.]]
('1 r-squared', 0.80972683246686095)
('2 r-squared', 0.86754436563450732)
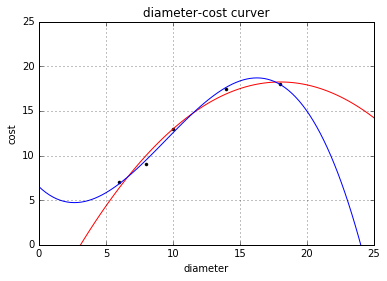
plt = runplt()
plt.plot(X_train, y_train, 'k.')
quadratic_featurizer = PolynomialFeatures(degree=2)
X_train_quadratic = quadratic_featurizer.fit_transform(X_train)
X_test_quadratic = quadratic_featurizer.transform(X_test)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(X_train_quadratic, y_train)
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), 'r-')
cubic_featurizer = PolynomialFeatures(degree=3)
X_train_cubic = cubic_featurizer.fit_transform(X_train)
X_test_cubic = cubic_featurizer.transform(X_test)
regressor_cubic = LinearRegression()
regressor_cubic.fit(X_train_cubic, y_train)
xx_cubic = cubic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_cubic.predict(xx_cubic))
plt.show()
print(X_train_cubic)
print(X_test_cubic)
print('2 r-squared', regressor_quadratic.score(X_test_quadratic, y_test))
print('3 r-squared', regressor_cubic.score(X_test_cubic, y_test))
[[ 1.00000000e+00 6.00000000e+00 3.60000000e+01 2.16000000e+02]
[ 1.00000000e+00 8.00000000e+00 6.40000000e+01 5.12000000e+02]
[ 1.00000000e+00 1.00000000e+01 1.00000000e+02 1.00000000e+03]
[ 1.00000000e+00 1.40000000e+01 1.96000000e+02 2.74400000e+03]
[ 1.00000000e+00 1.80000000e+01 3.24000000e+02 5.83200000e+03]]
[[ 1.00000000e+00 6.00000000e+00 3.60000000e+01 2.16000000e+02]
[ 1.00000000e+00 8.00000000e+00 6.40000000e+01 5.12000000e+02]
[ 1.00000000e+00 1.10000000e+01 1.21000000e+02 1.33100000e+03]
[ 1.00000000e+00 1.60000000e+01 2.56000000e+02 4.09600000e+03]]
('2 r-squared', 0.86754436563450732)
('3 r-squared', 0.83569241560369567)
plt = runplt()
plt.plot(X_train, y_train, 'k.')
quadratic_featurizer = PolynomialFeatures(degree=2)
X_train_quadratic = quadratic_featurizer.fit_transform(X_train)
X_test_quadratic = quadratic_featurizer.transform(X_test)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(X_train_quadratic, y_train)
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), 'r-')
seventh_featurizer = PolynomialFeatures(degree=7)
X_train_seventh = seventh_featurizer.fit_transform(X_train)
X_test_seventh = seventh_featurizer.transform(X_test)
regressor_seventh = LinearRegression()
regressor_seventh.fit(X_train_seventh, y_train)
xx_seventh = seventh_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_seventh.predict(xx_seventh))
plt.show()
print('2 r-squared', regressor_quadratic.score(X_test_quadratic, y_test))
print('7 r-squared', regressor_seventh.score(X_test_seventh, y_test))

('2 r-squared', 0.86754436563450732)
('7 r-squared', 0.49198460568655)
可以看出,七次拟合的R方值更低,虽然其图形基本经过了所有的点。可以认为这是拟合过度(over-fitting)的情况。这种模型并没有从输入和输出中推导出一般的规律,而是记忆训练集的结果,这样在测试集的测试效果就不好了。
正则化
LASSO方法会产生稀疏参数,大多数相关系数会变成0,模型只会保留一小部分特征。而岭回归还是会保留大多数尽可能小的相关系数。当两个变量相关时,LASSO方法会让其中一个变量的相关系数会变成0,而岭回归是将两个系数同时缩小。
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
from sklearn.cross_validation import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
X_scaler = StandardScaler()
y_scaler = StandardScaler()
X_train = X_scaler.fit_transform(X_train)
y_train = y_scaler.fit_transform(y_train.reshape(-1, 1))
X_test = X_scaler.transform(X_test)
y_test = y_scaler.transform(y_test.reshape(-1, 1))
regressor = SGDRegressor(loss='squared_loss',penalty="l1")
scores = cross_val_score(regressor, X_train, y_train.reshape(-1, 1), cv=5)
print('cv R', scores)
print('mean of cv R', np.mean(scores))
regressor.fit_transform(X_train, y_train)
print('Test set R', regressor.score(X_test, y_test))
('cv R', array([ 0.74761441, 0.62036841, 0.6851797 , 0.63347999, 0.79476346]))
('mean of cv R', 0.69628119572104885)
('Test set R', 0.75084948718041566)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python机器学习库scikit-learn安装与基本使用教程
本文实例讲述了Python机器学习库scikit-learn安装与基本使用.分享给大家供大家参考,具体如下: 引言 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口,可以让用户简单.高效地进行数据挖掘和数据分析. scikit-learn安装 python 中安装许多模板库之前都有依赖关系,安装 scikit-learn 之前需要以下先决条件: Python(>= 2.6 or >= 3
-
用scikit-learn和pandas学习线性回归的方法
对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了. 1. 获取数据,定义问题 没有数据,当然没法研究机器学习啦.:) 这里我们用UCI大学公开的机器学习数据来跑线性回归. 数据的介绍在这:http://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant 数据的下载地址在这:http://archive.ics.uci.edu/ml/mach
-

Python scikit-learn 做线性回归的示例代码
一.概述 机器学习算法在近几年大数据点燃的热火熏陶下已经变得被人所"熟知",就算不懂得其中各算法理论,叫你喊上一两个著名算法的名字,你也能昂首挺胸脱口而出.当然了,算法之林虽大,但能者还是有限,能适应某些环境并取得较好效果的算法会脱颖而出,而表现平平者则被历史所淡忘.随着机器学习社区的发展和实践验证,这群脱颖而出者也逐渐被人所认可和青睐,同时获得了更多社区力量的支持.改进和推广. 以最广泛的分类算法为例,大致可以分为线性和非线性两大派别.线性算法有著名的逻辑回归.朴素贝叶斯.最大熵等,
-
基于Python和Scikit-Learn的机器学习探索
你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎.我同时在为一家俄罗斯移动运营商开发大数据产品.这是我第一次在网上写文章,不喜勿喷. 现在,很多人想开发高效的算法以及参加机器学习的竞赛.所以他们过来问我:"该如何开始?".一段时间以前,我在一个俄罗斯联邦政府的下属机构中领导了媒体和社交网络大数据分析工具的开发.我仍然有一些我团队使用过的文档,我乐意与你们分享.前提是读者已经有很好的数学和机器学习方面的知识(我的团队主要由MIPT(莫斯科物理与技术大学)和
-
python的scikit-learn将特征转成one-hot特征的方法
如下所示: enc = OneHotEncoder(categorical_features=np.array([0,1,2]),n_values=[5,4,2]) enc.fit(train_data) train_data = enc.transform(train_data).toarray() test_data = enc.transform(test_data).toarray() 以上这篇python的scikit-learn将特征转成one-hot特征的方法就是小编分享给大家的全
-
python中scikit-learn机器代码实例
我们给大家带来了关于学习python中scikit-learn机器代码的相关具体实例,以下就是全部代码内容: # -*- coding: utf-8 -*- import numpy from sklearn import metrics from sklearn.svm import LinearSVC from sklearn.naive_bayes import MultinomialNB from sklearn import linear_model from sklearn.data
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要
-
Python机器学习之scikit-learn库中KNN算法的封装与使用方法
本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法.分享给大家供大家参考,具体如下: 1.工具准备,python环境,pycharm 2.在机器学习中,KNN是不需要训练过程的算法,也就是说,输入样例可以直接调用predict预测结果,训练数据集就是模型.当然这里必须将训练数据和训练标签进行拟合才能形成模型. 3.在pycharm中创建新的项目工程,并在项目下新建KNN.py文件. import numpy as np from math import s
-
python机器学习库scikit-learn:SVR的基本应用
scikit-learn是python的第三方机器学习库,里面集成了大量机器学习的常用方法.例如:贝叶斯,svm,knn等. scikit-learn的官网 : http://scikit-learn.org/stable/index.html点击打开链接 SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支. scikit-learn中提供了基于libsvm的SVR解决方案. PS:libsvm是台湾大学林智仁教授等开发设
-
TensorFlow实现iris数据集线性回归
本文将遍历批量数据点并让TensorFlow更新斜率和y截距.这次将使用Scikit Learn的内建iris数据集.特别地,我们将用数据点(x值代表花瓣宽度,y值代表花瓣长度)找到最优直线.选择这两种特征是因为它们具有线性关系,在后续结果中将会看到.本文将使用L2正则损失函数. # 用TensorFlow实现线性回归算法 #---------------------------------- # # This function shows how to use TensorFlow to #
-
人工智能-Python实现多项式回归
目录 1.概述 1.1 有监督学习 1.2 多项式回归 2 概念 3 案例实现——方法1 3.1 案例分析 3.2 代码实现 3.3 结果 3.4 可视化 4 案例实现——方法2 4.1 代码 4.2 结果 4.3 可视化 1.概述 1.1 有监督学习 1.2 多项式回归 上一次我们讲解了线性回归,这次我们重点分析多项式回归. 多项式回归(Polynomial Regression) 是研究一个因变量与一 个或多个自变量间多项式的回归分析方法.如果自变量只有一个 时,称为一元多项式回归:如果自变
-
分享15 个python中的 Scikit-Learn 技能
目录 1.数据集 2.数据拆分 3.线性回归 4.逻辑回归 5.决策树 6.Bagging 7.Boosting 8.随机森林 9.XGBoost 10.支持向量机(SVM) 11.混淆矩阵 12.K-均值聚类 13.DBSCAN聚类 14.标准化和规范化 标准化 正常化 15.特征提取 前言: Scikit-Learn 是一个非常棒的 python 库,用于实现机器学习模型和统计建模.通过它,我们不仅可以实现各种回归.分类.聚类的机器学习模型,它还提供了降维.特征选择.特征提取.集成技术和内置
-
python 缺失值处理的方法(Imputation)
一.缺失值的处理方法 由于各种各样的原因,真实世界中的许多数据集都包含缺失数据,这些数据经常被编码成空格.nans或者是其他的占位符.但是这样的数据集并不能被scikit - learn算法兼容,因为大多数的学习算法都会默认数组中的元素都是数值,因此素偶有的元素都有自己的代表意义. 使用不完整的数据集的一个基本策略就是舍弃掉整行或者整列包含缺失值的数值,但是这样处理会浪费大量有价值的数据.下面是处理缺失值的常用方法: 1.忽略元组 当缺少类别标签时通常这样做(假定挖掘任务涉及分类时),除非元组有
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有
-
对Python random模块打乱数组顺序的实例讲解
在我们使用一些数据的过程中,我们想要打乱数组内数据的顺序但不改变数据本身,可以通过改变索引值来实现,也就是将索引值重新随机排列,然后生成新的数组.功能主要由python中random模块的sample()函数实现. sample(population, k) method of random.Random instance Chooses k unique random elements from a population sequence or set. 下面的代码实现的是打乱iris数据,i
-
python计算auc的方法
1.安装scikit-learn 1.1 Scikit-learn 依赖 Python (>= 2.6 or >= 3.3), NumPy (>= 1.6.1), SciPy (>= 0.9). 分别查看上述三个依赖的版本: python -V 结果: Python 2.7.3 python -c 'import scipy; print scipy.version.version' scipy版本结果: 0.9.0 python -c "import numpy; pr
-
python缺失值的解决方法总结
1.解决方法 (1)忽视元组. 缺少类别标签时,通常这样做(假设挖掘任务与分类有关),除非元组有多个属性缺失值,否则该方法不太有效.当个属性缺值的百分比变化很大时,其性能特别差. (2)人工填写缺失值. 一般来说,这种方法需要很长时间,当数据集大且缺少很多值时,这种方法可能无法实现. (3)使用全局常量填充缺失值. 将缺失的属性值用同一常数(如Unknown或负无限)替换.如果缺失值都是用unknown替换的话,挖掘程序可能会认为形成有趣的概念.因为有同样的价值unknown.因此,这种方法很简
-
Python Pytorch学习之图像检索实践
目录 背景 图像表现 搜索 随着电子商务和在线网站的出现,图像检索在我们的日常生活中的应用一直在增加. 亚马逊.阿里巴巴.Myntra等公司一直在大量利用图像检索技术.当然,只有当通常的信息检索技术失败时,图像检索才会开始工作. 背景 图像检索的基本本质是根据查询图像的特征从集合或数据库中查找图像. 大多数情况下,这种特征是图像之间简单的视觉相似性.在一个复杂的问题中,这种特征可能是两幅图像在风格上的相似性,甚至是互补性. 由于原始形式的图像不会在基于像素的数据中反映这些特征,因此我们需要将这些
-
scikit-learn线性回归,多元回归,多项式回归的实现
匹萨的直径与价格的数据 %matplotlib inline import matplotlib.pyplot as plt def runplt(): plt.figure() plt.title(u'diameter-cost curver') plt.xlabel(u'diameter') plt.ylabel(u'cost') plt.axis([0, 25, 0, 25]) plt.grid(True) return plt plt = runplt() X = [[6], [8],