Python3爬虫使用Fidder实现APP爬取示例
之前爬取都是网页上的数据,今天要来说一下怎么借助Fidder来爬取手机APP上的数据。
一、环境配置
1、Fidder的安装和配置
没有安装Fidder软件的可以进入 这个网址 下载,然后就是傻瓜式的安装,安装步骤很简单。在安装完成后,打开软件,进行如下设置:
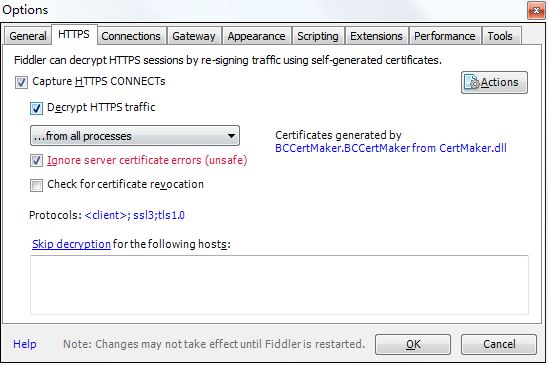
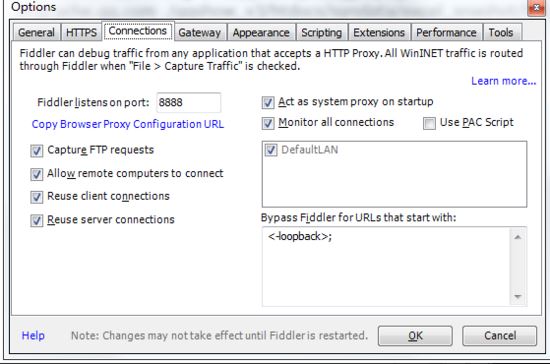
这里使用默认的8888端口就好了,如果要修改的话,要避免和其他端口冲突。
2、手机的配置
首先打开cmd,输入ipconfig查看IP地址,记录下这个IP地址:
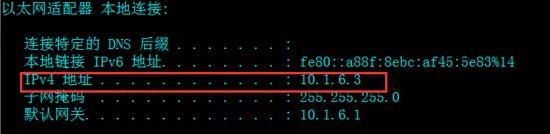
想要使用FIdder进行手机抓包,要让手机和PC处在同一个内网中,方法就是连接同一个无线网络。然后打开手机,进入Wi-FI设置修改代理为手动代理,再把上面的IP地址和8888端口号输入进去:
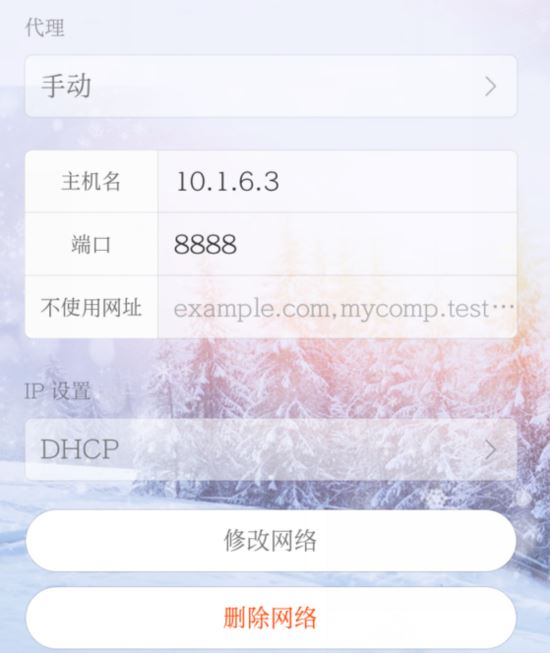
然后打开浏览器,输入http://127.0.0.1:8888,会看到如下界面,点击FidderRoot certificate下载证书:
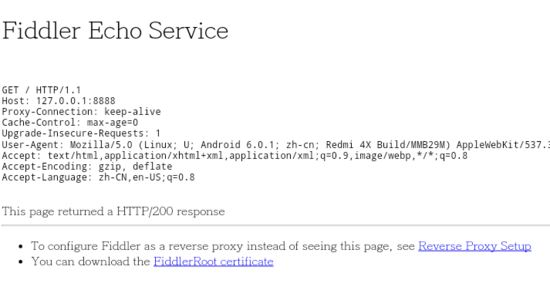
下载好之后如果出现无法安装的情况,可以进入设置进行手动安装证书,我的安装步骤是“设置->系统安全->从SD卡安装”,不同的手机安装步骤不同,不过也差不多吧。
3、抓包测试
在完成上面的步骤之后,我们先进行一下抓包测试,打开手机的浏览器,然后打开百度的网页,可以看到出现了对应的包,这样就可以进行之后的抓取了。

二、抓取步骤
这次使用的APP是王者荣耀盒子,打开APP,点击英雄,可以看到第一个英雄-上官婉儿,然后点进去。
然后在Fidder中可以找到如下这个包:

然后在右侧可以看到如下信息:
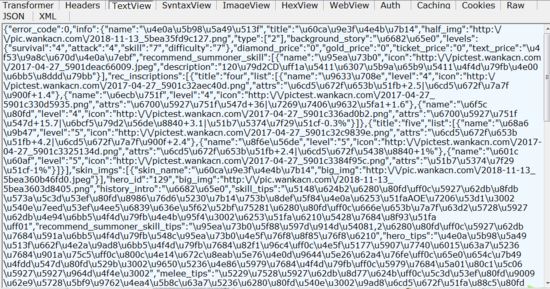
把这些信息复制一下,然后解码一下就可以看到如下数据了,包括英雄名字、英雄图片、英雄技能等信息:

但是在推荐装备的信息里,只有装备的id值,却没有装备的名字,那我们要怎么获得这些装备的名字呢?还是同样的办法,点击查看所有装备,然后抓包,找到对应的包,再进行爬取。在获得所有的装备和对应的id后,可以再爬取所有的英雄名称,然后就可以制作我们自己的英雄攻略了==
运行结果如下:

三、完整代码
"""
Version: Python3.5
Author: OniOn
Time: 2018/11/26 21:20
"""
import requests
# 装备信息
EQUIP_LIST = []
# 英雄信息
HERO_LIST = []
# 爬取英雄信息
def get_hero(hero_id):
url = "http://gamehelper.gm825.com/wzry/hero/detail?hero_id={}&channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=192384A3D29A295307CA7B96762D3911&ovr=6.0.1&device=Xiaomi_Redmi+4X&net_type=1&client_id=&info_ms=&info_ma=Z6OSFnQs6mXn4axI72A6yENV6NHXHBW%2FwZ6YjXKCGko%3D&mno=0&info_la=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&info_ci=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=bFL4zw1N%2FGL43totbQy7Q9D8UfrPgiMUFRNSpM25pnY%3D&os_level=23&os_id=a2aa922677827ab1&resolution=720_1280&dpi=320&client_ip=10.12.88.95&pdunid=257ed0277cf4".format(
hero_id)
res = requests.post(url)
js = res.json()
img_url = js['info']['big_img']
skill_tips = js['info']['skill_tips'] # 使用技巧
skill_list = [] # 技能介绍
for i in js['info']['skill_list']:
desc = i['description'] if '<br>' not in i['description'] else i['description'].replace('<br>', '')
skill_list.append({
"name": i['name'] + "({})".format(i['intro']),
"type": i['tags'],
"desc": desc
})
print("英雄图片链接:{}".format(img_url))
print("英雄使用技巧:{}".format(skill_tips))
for i in skill_list:
print('{} 类型:{} \n技能介绍:{}'.format(i['name'], i['type'], i['desc']))
print("推荐装备:", end="")
equip_choice = [] # 推荐装备
all_money =
for i in js['info']['equip_choice'][]['list']:
equip_choice.append(EQUIP_LIST[int(i['equip_id'])]['name'])
all_money += int(EQUIP_LIST[int(i['equip_id'])]['price'])
print(' '.join(equip_choice), " (装备总金额:{})".format(all_money))
# 爬取所有装备的基本信息
def get_all_equip():
url = "http://gamehelper.gm825.com/wzry/equip/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=192384A3D29A295307CA7B96762D3911&ovr=6.0.1&device=Xiaomi_Redmi+4X&net_type=1&client_id=&info_ms=&info_ma=Z6OSFnQs6mXn4axI72A6yENV6NHXHBW%2FwZ6YjXKCGko%3D&mno=0&info_la=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&info_ci=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=bFL4zw1N%2FGL43totbQy7Q9D8UfrPgiMUFRNSpM25pnY%3D&os_level=23&os_id=a2aa922677827ab1&resolution=720_1280&dpi=320&client_ip=10.12.88.95&pdunid=257ed0277cf4"
res = requests.get(url)
for i in res.json()['list']:
EQUIP_LIST.append({
'price': i['price'],
'name': i['name'],
# 'equip_id': i['equip_id']
})
# 爬取所有英雄的基本信息
def get_all_hero():
# 英雄定位: type 1-战士 2-法师 3-坦克 4-刺客 5-射手 6-辅助
type_list = ['战士', '法师', '坦克', '刺客', '射手', '辅助']
url = "http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=192384A3D29A295307CA7B96762D3911&ovr=6.0.1&device=Xiaomi_Redmi+4X&net_type=1&client_id=&info_ms=&info_ma=Z6OSFnQs6mXn4axI72A6yENV6NHXHBW%2FwZ6YjXKCGko%3D&mno=0&info_la=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&info_ci=zdisjKfT0Zj1UXN2un%2BlyA%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=bFL4zw1N%2FGL43totbQy7Q9D8UfrPgiMUFRNSpM25pnY%3D&os_level=23&os_id=a2aa922677827ab1&resolution=720_1280&dpi=320&client_ip=10.12.88.95&pdunid=257ed0277cf4"
res = requests.get(url)
for i in res.json()['list']:
HERO_LIST.append({
"name": i['name'],
"id": i['hero_id'],
'type': '/'.join([type_list[int(j) - ] for j in i['type']])
})
if __name__ == '__main__':
get_all_hero()
length = len(HERO_LIST)
print("-" * 50)
for i in range(0, length // 5 * 5, 5):
print('{}(id:{}) '.format(HERO_LIST[i]['name'], HERO_LIST[i]['id']), end=' ')
print('{}(id:{}) '.format(HERO_LIST[i + 1]['name'], HERO_LIST[i + 1]['id']), end=' ')
print('{}(id:{}) '.format(HERO_LIST[i + 2]['name'], HERO_LIST[i + 2]['id']), end=' ')
print('{}(id:{}) '.format(HERO_LIST[i + 3]['name'], HERO_LIST[i + 3]['id']), end=' ')
print('{}(id:{}) '.format(HERO_LIST[i + 4]['name'], HERO_LIST[i + 4]['id']))
for i in range(length // 5 * 5, length):
print('{}(id:{}) '.format(HERO_LIST[i]['name'], HERO_LIST[i]['id']), end=' ')
print('\n', "-" * 50)
get_all_equip()
get_hero(input("\n请输入您想查看的英雄id:"))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
详解Linux防火墙iptables禁IP与解封IP常用命令
在Linux服务器被攻击的时候,有的时候会有几个主力IP.如果能拒绝掉这几个IP的攻击的话,会大大减轻服务器的压力,说不定服务器就能恢复正常了. 在Linux下封停IP,有封杀网段和封杀单个IP两种形式.一般来说,现在的攻击者不会使用一个网段的IP来攻击(太招摇了),IP一般都是散列的.于是下面就详细说明一下封杀单个IP的命令,和解封单个IP的命令. Linux防火墙:iptables禁IP与解封IP常用命令 在Linux下,使用ipteables来维护IP规则表.要封停或者是解封IP,其实就是
-

Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
Nginx利用Lua+Redis实现动态封禁IP的方法
一.背景 我们在日常维护网站中,经常会遇到这样一个需求,为了封禁某些爬虫或者恶意用户对服务器的请求,我们需要建立一个动态的 IP 黑名单.对于黑名单之内的 IP ,拒绝提供服务. 本文给大家介绍的是Nginx利用Lua+Redis实现动态封禁IP的方法,下面话不多说了,来一起看看详细的介绍吧 二.架构 实现 IP 黑名单的功能有很多途径: 1.在操作系统层面,配置 iptables,拒绝指定 IP 的网络请求: 2.在 Web Server 层面,通过 Nginx 自身的 deny 选项 或者
-
Python3爬虫学习之应对网站反爬虫机制的方法分析
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法.分享给大家供大家参考,具体如下: 如何应对网站的反爬虫机制 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略. 例如打开搜狐首页,先来看一下Chrome的头信息(F12打开开发者模式)如下: 如图,访问头信息中显示了浏览器以及系统的信息(headers所含信息众多,具体可自行查询) Python中urllib中的request模块提供了模拟浏览器访问的功能,代码如下: from
-
Python3爬虫学习入门教程
本文实例讲述了Python3爬虫相关入门知识.分享给大家供大家参考,具体如下: 在网上看到大多数爬虫教程都是Python2的,但Python3才是未来的趋势,许多初学者看了Python2的教程学Python3的话很难适应过来,毕竟Python2.x和Python3.x还是有很多区别的,一个系统的学习方法和路线非常重要,因此我在联系了一段时间之后,想写一下自己的学习过程,分享一下自己的学习经验,顺便也锻炼一下自己. 一.入门篇 这里是Python3的官方技术文档,在这里需要着重说一下,语言的技术文
-
Python3爬虫全国地址信息
PHP方式写的一团糟所以就用python3重写了一遍,所以因为第二次写了,思路也更清晰了些. 提醒:可能会有502的错误,所以做了异常以及数据库事务处理,暂时没有想到更好的优化方法,所以就先这样吧.待更懂python再进一步优化哈 欢迎留言赐教~ #!C:\Users\12550\AppData\Local\Programs\Python\Python37\python.exe # -*- coding: utf-8 -*- from urllib.request import urlopen
-
python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻 1. 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 2.首先,我们要写爬虫,可以借鉴
-
Python3爬虫教程之利用Python实现发送天气预报邮件
前言 此次的目标是爬取指定城市的天气预报信息,然后再用Python发送邮件到指定的邮箱. 下面话不多说了,来一起看看详细的实现过程吧 一.爬取天气预报 1.首先是爬取天气预报的信息,用的网站是中国天气网,网址是http://www.weather.com.cn/static/html/weather.shtml,任意选择一个城市(比如武汉),然后要爬取的内容为下面的部分: 先查看网页源代码,并没有找到第一张图中的内容,说明是这些天气信息是通过别的方式加载出来的.我们打开开发者工具,点击XHR选项
-
Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验.(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到) 1.划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数.代理可以根据自己需要选择,当然免费的也是有
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带