eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试,那么问题来了,win7下的eclipse或intellij idea如何远程提交map/reduce任务到远程hadoop,并断点调试?
一、准备工作
1.1 在win7中,找一个目录,解压hadoop-2.6.0,本文中是D:\yangjm\Code\study\hadoop\hadoop-2.6.0 (以下用$HADOOP_HOME表示)
1.2 在win7中添加几个环境变量
HADOOP_HOME=D:\yangjm\Code\study\hadoop\hadoop-2.6.0
HADOOP_BIN_PATH=%HADOOP_HOME%\bin
HADOOP_PREFIX=D:\yangjm\Code\study\hadoop\hadoop-2.6.0
另外,PATH变量在最后追加;%HADOOP_HOME%\bin
二、eclipse远程调试
1.1 下载hadoop-eclipse-plugin插件
hadoop-eclipse-plugin是一个专门用于eclipse的hadoop插件,可以直接在IDE环境中查看hdfs的目录和文件内容。其源代码托管于github上,官网地址是 https://github.com/winghc/hadoop2x-eclipse-plugin
有兴趣的可以自己下载源码编译,百度一下N多文章,但如果只是使用 https://github.com/winghc/hadoop2x-eclipse-plugin/tree/master/release%20这里已经提供了各种编译好的版本,直接用就行,将下载后的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse/plugins目录下,然后重启eclipse就完事了
1.2 下载windows64位平台的hadoop2.6插件包(hadoop.dll,winutils.exe)
在hadoop2.6.0源码的hadoop-common-project\hadoop-common\src\main\winutils下,有一个vs.net工程,编译这个工程可以得到这一堆文件,输出的文件中,
hadoop.dll、winutils.exe 这二个最有用,将winutils.exe复制到$HADOOP_HOME\bin目录,将hadoop.dll复制到%windir%\system32目录 (主要是防止插件报各种莫名错误,比如空对象引用啥的)
注:如果不想编译,可直接下载编译好的文件 hadoop2.6(x64)V0.2.rar
1.3 配置hadoop-eclipse-plugin插件
启动eclipse,windows->show view->other

window->preferences->hadoop map/reduce 指定win7上的hadoop根目录(即:$HADOOP_HOME)

然后在Map/Reduce Locations 面板中,点击小象图标

添加一个Location
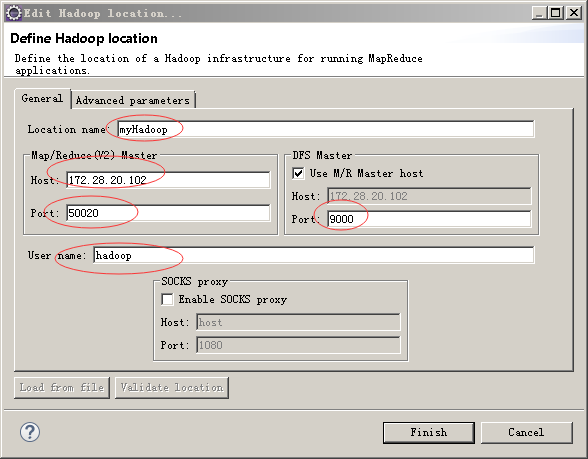
这个界面灰常重要,解释一下几个参数:
Location name 这里就是起个名字,随便起
Map/Reduce(V2) Master Host 这里就是虚拟机里hadoop master对应的IP地址,下面的端口对应 hdfs-site.xml里dfs.datanode.ipc.address属性所指定的端口
DFS Master Port: 这里的端口,对应core-site.xml里fs.defaultFS所指定的端口
最后的user name要跟虚拟机里运行hadoop的用户名一致,我是用hadoop身份安装运行hadoop 2.6.0的,所以这里填写hadoop,如果你是用root安装的,相应的改成root
这些参数指定好以后,点击Finish,eclipse就知道如何去连接hadoop了,一切顺利的话,在Project Explorer面板中,就能看到hdfs里的目录和文件了

可以在文件上右击,选择删除试下,通常第一次是不成功的,会提示一堆东西,大意是权限不足之类,原因是当前的win7登录用户不是虚拟机里hadoop的运行用户,解决办法有很多,比如你可以在win7上新建一个hadoop的管理员用户,然后切换成hadoop登录win7,再使用eclipse开发,但是这样太烦,最简单的办法:
hdfs-site.xml里添加
<property> <name>dfs.permissions</name> <value>false</value> </property>
然后在虚拟机里,运行hadoop dfsadmin -safemode leave
保险起见,再来一个 hadoop fs -chmod 777 /
总而言之,就是彻底把hadoop的安全检测关掉(学习阶段不需要这些,正式生产上时,不要这么干),最后重启hadoop,再到eclipse里,重复刚才的删除文件操作试下,应该可以了。
1.4 创建WoldCount示例项目
新建一个项目,选择Map/Reduce Project

后面的Next就行了,然后放一上WodCount.java,代码如下:
package yjmyzz;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后再放一个log4j.properties,内容如下:(为了方便运行起来后,查看各种输出)
log4j.rootLogger=INFO, stdout
#log4j.logger.org.springframework=INFO
#log4j.logger.org.apache.activemq=INFO
#log4j.logger.org.apache.activemq.spring=WARN
#log4j.logger.org.apache.activemq.store.journal=INFO
#log4j.logger.org.activeio.journal=INFO
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n
最终的目录结构如下:

然后可以Run了,当然是不会成功的,因为没给WordCount输入参数,参考下图:
1.5 设置运行参数

因为WordCount是输入一个文件用于统计单词字,然后输出到另一个文件夹下,所以给二个参数,参考上图,在Program arguments里,输入
hdfs://172.28.20.xxx:9000/jimmy/input/README.txt
hdfs://172.28.20.xxx:9000/jimmy/output/
大家参考这个改一下(主要是把IP换成自己虚拟机里的IP),注意的是,如果input/READM.txt文件没有,请先手动上传,然后/output/ 必须是不存在的,否则程序运行到最后,发现目标目录存在,也会报错,这个弄完后,可以在适当的位置打个断点,终于可以调试了:

三、intellij idea 远程调试hadoop
3.1 创建一个maven的WordCount项目
pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>yjmyzz</groupId>
<artifactId>mapreduce-helloworld</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
</build>
</project>
项目结构如下:
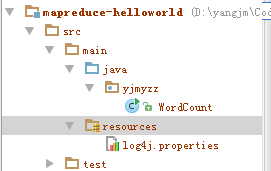
项目上右击-》Open Module Settings 或按F12,打开模块属性
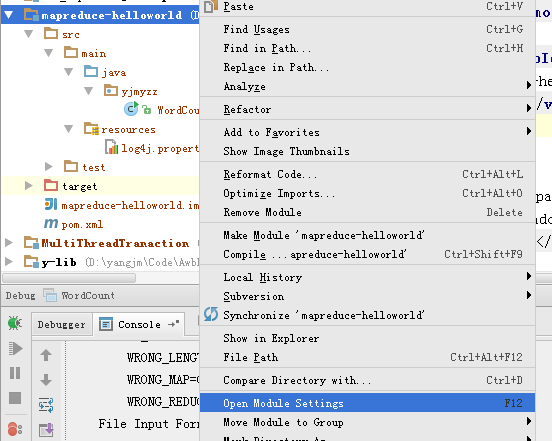
添加依赖的Libary引用

然后把$HADOOP_HOME下的对应包全导进来

导入的libary可以起个名称,比如hadoop2.6

3.2 设置运行参数

注意二个地方:
1是Program aguments,这里跟eclipes类似的做法,指定输入文件和输出文件夹
2是Working Directory,即工作目录,指定为$HADOOP_HOME所在目录
然后就可以调试了

intellij下唯一不爽的,由于没有类似eclipse的hadoop插件,每次运行完wordcount,下次再要运行时,只能手动命令行删除output目录,再行调试。为了解决这个问题,可以将WordCount代码改进一下,在运行前先删除output目录,见下面的代码:
package yjmyzz;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
/**
* 删除指定目录
*
* @param conf
* @param dirPath
* @throws IOException
*/
private static void deleteDir(Configuration conf, String dirPath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path targetPath = new Path(dirPath);
if (fs.exists(targetPath)) {
boolean delResult = fs.delete(targetPath, true);
if (delResult) {
System.out.println(targetPath + " has been deleted sucessfullly.");
} else {
System.out.println(targetPath + " deletion failed.");
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//先删除output目录
deleteDir(conf, otherArgs[otherArgs.length - 1]);
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
但是光这样还不够,在IDE环境中运行时,IDE需要知道去连哪一个hdfs实例(就好象在db开发中,需要在配置xml中指定DataSource一样的道理),将$HADOOP_HOME\etc\hadoop下的core-site.xml,复制到resouces目录下,类似下面这样:

里面的内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://172.28.20.***:9000</value> </property> </configuration>
上面的IP换成虚拟机里的IP即可。
相关推荐
-
java结合HADOOP集群文件上传下载
对HDFS上的文件进行上传和下载是对集群的基本操作,在<HADOOP权威指南>一书中,对文件的上传和下载都有代码的实例,但是对如何配置HADOOP客户端却是没有讲得很清楚,经过长时间的搜索和调试,总结了一下,如何配置使用集群的方法,以及自己测试可用的对集群上的文件进行操作的程序.首先,需要配置对应的环境变量: 复制代码 代码如下: hadoop_HOME="/home/work/tools/java/hadoop-client/hadoop" for f in $hadoo
-
Hadoop SSH免密码登录以及失败解决方案
1. 创建ssh-key 这里我们采用rsa方式,使用如下命令: xiaosi@xiaosi:~$ ssh-keygen -t rsa -f ~/.ssh/id_rsa Generating public/private rsa key pair. Created directory '/home/xiaosi/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identifi
-
Hadoop MapReduce多输出详细介绍
Hadoop MapReduce多输出 FileOutputFormat及其子类产生的文件放在输出目录下.每个reducer一个文件并且文件由分区号命名:part-r-00000,part-r-00001,等等.有时可能要对输出的文件名进行控制或让每个reducer输出多个文件.MapReduce为此提供了MultipleOutputFormat类. MultipleOutputFormat类可以将数据写到多个文件,这些文件的名称源于输出的键和值或者任意字符串.这允许每个reducer(或者只有
-
Hadoop 2.x伪分布式环境搭建详细步骤
本文以图文结合的方式详细介绍了Hadoop 2.x伪分布式环境搭建的全过程,供大家参考,具体内容如下 1.修改hadoop-env.sh.yarn-env.sh.mapred-env.sh 方法:使用notepad++(beifeng用户)打开这三个文件 添加代码:export JAVA_HOME=/opt/modules/jdk1.7.0_67 2.修改core-site.xml.hdfs-site.xml.yarn-site.xml.mapred-site.xml配置文件 1)修改core-
-

windows 32位eclipse远程hadoop开发环境搭建
本文假设hadoop环境在远程机器(如linux服务器上),hadoop版本为2.5.2 注:本文eclipse/intellij idea 远程调试hadoop 2.6.0主要参考了并在其基础上有所调整 由于我喜欢在win7 64位上安装32位的软件,比如32位jdk,32位eclipse,所以虽然本文中的操作系统是win7 64位,但是所有的软件都是32位的. 软件版本: 操作系统:win7 64位 eclipse: eclipse-jee-mars-2-win32 java: 1.8.0_
-
Hadoop streaming详细介绍
Hadoop streaming Hadoop为MapReduce提供了不同的API,可以方便我们使用不同的编程语言来使用MapReduce框架,而不是只局限于Java.这里要介绍的就是Hadoop streaming API.Hadoop streaming 使用Unix的standard streams作为我们mapreduce程序和MapReduce框架之间的接口.所以你可以用任何语言来编写MapReduce程序,只要该语言可以往standard input/output上进行读写. st
-
使用Maven搭建Hadoop开发环境
关于Maven的使用就不再啰嗦了,网上很多,并且这么多年变化也不大,这里仅介绍怎么搭建Hadoop的开发环境. 1. 首先创建工程 复制代码 代码如下: mvn archetype:generate -DgroupId=my.hadoopstudy -DartifactId=hadoopstudy -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false 2. 然后在pom.xml文件里添加hadoop的依赖
-
Java访问Hadoop分布式文件系统HDFS的配置说明
配置文件 m103替换为hdfs服务地址. 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDFS,文件无法创建.读取. <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <co
-
Hadoop中的Python框架的使用指南
最近,我加入了Cloudera,在这之前,我在计算生物学/基因组学上已经工作了差不多10年.我的分析工作主要是利用Python语言和它很棒的科学计算栈来进行的.但Apache Hadoop的生态系统大部分都是用Java来实现的,也是为Java准备的,这让我很恼火.所以,我的头等大事变成了寻找一些Python可以用的Hadoop框架. 在这篇文章里,我会把我个人对这些框架的一些无关科学的看法写下来,这些框架包括: Hadoop流 mrjob dumbo hadoopy pydoop 其它 最终,在
-
eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试,那么问题来了,win7下的eclipse或intellij idea如何远程提交map/reduce任务到远程hadoop,并断点调试? 一.准备工作 1.1 在win7中,找一个目录,解压hadoop-2.6.0,本文中是D:\yangjm\Code\study\hadoop\hadoop-2.
-
详述IntelliJ IDEA远程调试Tomcat的方法(图文)
在调试代码的过程中,为了更好的定位及解决问题,有时候需要我们使用远程调试的方法.在本文中,就让我们一起来看看,如何利用 IntelliJ IDEA 进行远程 Tomcat 的调试. 首先,配置remote: 如上图所示,点击Edit Configurations,进入如下界面: 如上图所示,我们进入了Run/Debug Configurations界面,然后点击左上角的+,选择Remote: 标注 1:运行远程 JVM 的命令行参数: 标注 2:传输方式,默认为Socket: 标注 3:调试模式
-
Intellij IDEA远程debug教程实战和要点总结(推荐)
远程调试,特别是当你在本地开发的时候,你需要调试服务器上的程序时,远程调试就显得非常有用. JAVA 支持调试功能,本身提供了一个简单的调试工具JDB,支持设置断点及线程级的调试同时,不同的JVM通过接口的协议联系,本地的Java文件在远程JVM建立联系和通信.此篇是Intellij IDEA远程调试的教程汇总和原理解释,知其然而又知其所以然. 本机Intellij IDEA远程调试配置 1,打开Inteliij IDEA,顶部菜单栏选择Run-> Edit Configurations,进入下
-
Hadoop 使用IntelliJ IDEA 进行远程调试代码的配置方法
一 .前言 昨天晚上遇到一个奇葩的问题, 搞好的环境DataNode启动报错. 报错信息提示的模棱两可,没办法定位原因. 办法,开启远程调试- 注意 : 开启远程调试的代码,必须与本地idea的代码必须保持一致. 二 .服务器端配置 2.1. 设置启动远程debug端口 修改 服务器上的配置文件 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 增加 环境变量即可. 组件 环境变量设置 NameNode export HADOOP_NAMENODE_OPTS="-a
-
Intellij IDEA基于Springboot的远程调试(图文)
简介 本篇博客介绍一下在Intellij IDEA下对Springboot类型的项目的远程调试功能.所谓的远程调试就是服务端程序运行在一台远程服务器上,我们可以在本地服务端的代码(前提是本地的代码必须和远程服务器运行的代码一致)中设置断点,每当有请求到远程服务器时时能够在本地知道远程服务端的此时的内部状态. 方法 首先,打开Edit configurations,点击+号,创建一个Remote应用. 填写name,配置Host地址(远程服务器地址)和端口(选一个未被占用的端口).然后复制For
-
Intellij idea远程debug连接tomcat实现单步调试
web项目部署到tomcat上之后,有时需要打断点单步调试,如果用的是Intellij idea,可以通过如下方法实现: 开启debug端口,启动tomcat 以tomcat7.0.75为例,打开bin目录下的catalina.bat文件,如下图,可以看到默认的debug端口是8000,如果本地的8000已经被占用,请改成一个未占用的端口号: 在bin目录下执行命令catalina.bat jpda start,可以启动tomcat并开启远程调试的端口 在Intellij idea中远程连接to
-
Linux 中Tomcat远程调试代码的实现方法
Linux 中的tomcat远程调试代码 1,是要编辑catalina.sh文件. 而且要改成这 样: CATALINA_OPTS="-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp :transport=dt_socket,server=y,suspend=n,address=5888" 2.eclipse 中设置: 第一步: 第二步: 第三步: 以上就是Linux 中Tomcat远程调试代码的实现方法,如有疑问请留言
-
PHP远程调试之XDEBUG
开发的时候我都是使用XDebug在本地调试,但是最近加入一些项目中去,环境太复杂了,要在本地搭建一个开发环境真的太麻烦了,那么我们怎么使用xdebug来远程调试呢? 我这里使用虚拟机搭建了一个模拟环境来实验说明: 1.虚拟机IP:192.168.174.130 ,虚拟机用于搭建lampp环境 2.实体机IP:192.168.174.1,这个是IDE的开发环境. 首先我在虚拟机里面安装了一个lampp,而且增加了一vhosts,具体如下: vim /opt/lampp/etc/extra/http
-
PyCharm+PySpark远程调试的环境配置的方法
前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑. Version :Spark 1.5.0.Python 2.7.14 1. 远程Spark集群环境 首先Spark集群要配置好且能正常启动,版本号可以在Spark对应版本的官方网站查到,注意:Spark 1.5.0作为一个比较古老的版本,不支持Python 3.6+
-
IntelliJ IDEA远程Debug Linux的Java程序,找问题不要只会看日志了(推荐)
1 前言 我们习惯于在本地开发的时候debug,能快速定位与解决问题,那部署在服务器上是不是就没有办法了呢?只能通过查看日志来定位? 不是的,在远端的服务器上,我们一样可以debug. 2 IDEA的debug 我们先来看一下在IntelliJ IDEA直接debug是怎样的. 先准备一个简单的Java程序: package com.pkslow.basic; import java.util.Map; public class RemoteDebug { public static void