基于RabbitMQ的简单应用(详解)
虽然后台使用了读写分离技术,能够在一定程度上抗击高并发,但是如果并发量特别巨大时,主数据库不能同时处理高并发的请求,这时数据库容易宕机。
问题:
现在的问题是如何既能保证数据库正常运行,又能实现用户数据的入库操作?
解决方案:
引入rabbitMQ技术:

说明:
当数据库的访问压力过载时,这时会将过载以后的数据先保存到rabbitMQ中。其中的数据结构是队列的形式,先进先出。这时数据库从队列中取数据执行。一直到队列中的数据全部操作完成为止。
RabbitMQ就是消息的中间件。
RabbitMQ介绍:

RabbitMQ性能分析:

1.MSMQ:是微软的产品 应用于.net框架
2.ActiveMQ:是apache的产品 做业务用图广泛
3.RabbitQM:是爱立信的产品(早期手机生产厂商)基于erlang语言(函数式编程大数据 scala语言)
4.ZeroMQ:大数据中应用广泛,缺点容易丢失数据.但是业务系统中使用率较少
5.KafkaMQ:大数据项目中使用,50万/秒 现在主流
5.RabbitMQ环境搭建:
1.配置JDK:
2.固定虚拟机IP地址:

3.连接虚拟机:
编辑文件跳转路径:
Vim go
Cd /usr/local/src
2.安装rabbitMQ:
1.新建文件rabbitmq
/usr/local/src/rabbitmq
2.将安装文件导入

3.安装rabbitMQ

4.开启远程用户访问:
将文件复制到指定目录下:
cp /usr/share/doc/rabbitmq-server-3.6.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
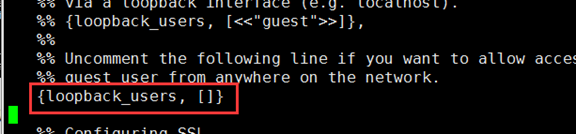
修改新复制的文件64行

1.将%%去掉
2.将,号去掉
修改为:
5.开启rabbitMQ:
执行命令:
rabbitmq-plugins enable rabbitmq_management

表示启动成功
6.开放端口15672和5672
iptables -I INPUT -p tcp --dport 15672 -j ACCEPT
访问rabbitMQ的控制台
iptables -I INPUT -p tcp --dport 5672 -j ACCEPT
程序连接rabbitMQ的端口
或者关闭防火墙
7.启动/停止服务
service rabbitmq-server start 启动
service rabbitmq-server stop 停止
service rabbitmq-server restart 重启

8.远程登录:
访问:
用户名和密码都是guest

9.视图解析:

10.建立管理员:
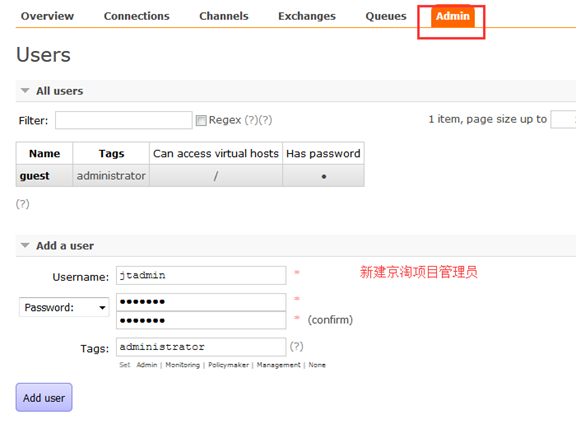
11.构建虚拟主机:
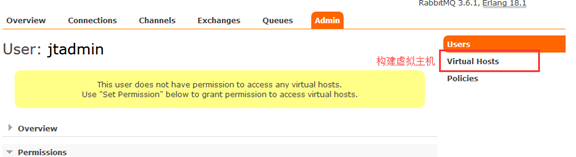

11.构建虚拟主机:



6.rabbitMQ的工作模式:
1.简单模式:

p:proverder 生产者
c:consumer 消费者
红色部分:队列 先进先出
原理说明:
生产者负责向队列中添加消息.消费者负责消费队列中的消息.
消费者通过监听器,实时监控消息队列.如果消息队列中有消息则消费,如果没有消息 则等待消息.
2.测试代码:
1.定义Connection

1.1.定义生产者


3.定义消费者:

2.工作模式:

原理说明:
生产者为消息队列中生产消息,多个消费者争抢执行权利,谁抢到谁执行.
实用场景:秒杀业务 抢红包等
测试代码:

3.发布订阅模式:

x:exchange 交换机
P:表示生产者
C1-2:表示多个消费者
原理说明:
当生产者生产消息后,先将消息发往交换机.交换机再将消息发往订阅了当前消息的队列,再次有各个队列的消费者执行.
类似于 广播

定义消费者::

4.路由模式:

x:表示交换机 type=direct 表示路由
路由模式中,需要定义路由key
原理说明:
1.当生产者发布消息时,会定义指定的路由key 例如 key:error
2.这时交换机会根据路由key发往满足条件的队列中.如果队列中没有符合条件的路由key将不能执行该消息.
5.主题模式:

Type:topic 表示主题模式
- * (star) can substitute for exactly one word.
- # (hash) can substitute for zero or more words.
- 有坑 效果一样
7.订单实现RabbitMQ
1.引入配置文件:
classpath:jdbc.propertiesclasspath:env.properties /hp月n、 口山闰廷比二曰站叩四瞿二月当“习 classpath:rabbitmq.properties IUe> /value>" v:shapes="图片_x0020_42">
2.引入生产者
1.引入配置文件

2.定义发送端

3.发送端代码
通过代码相rabbitmq中发送数据

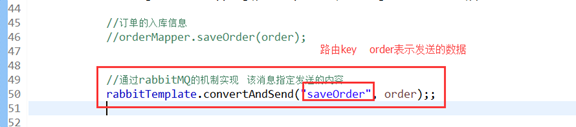
4.定义接收端:
引入配置文件

5.定义接收端:

6.测试成功
以上这篇基于RabbitMQ的简单应用(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
消息队列 RabbitMQ 与 Spring 整合使用的实例代码
一.什么是 RabbitMQ RabbitMQ 是实现 AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性.扩展性.高可用性等方面表现不俗.消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然. RabbitMQ 是由 Erlang 语言开发,安装 RabbitMQ 服务需要先安装 Erlang 语言包. 二.如何与 Spring 集成 1. 我们都需要哪些 Jar 包? 抛开单独使用 Spring 的包不说,
-
spring boot整合RabbitMQ(Direct模式)
springboot集成RabbitMQ非常简单,如果只是简单的使用配置非常少,springboot提供了spring-boot-starter-amqp项目对消息各种支持. 1.新建一个Spring Boot工程,命名为:"rabbitmq-hello". 在pom.xml中引入如下依赖内容,其中spring-boot-starter-amqp用于支持RabbitMQ. <dependency> <groupId>org.springframework.boo
-

基于RabbitMQ的简单应用(详解)
虽然后台使用了读写分离技术,能够在一定程度上抗击高并发,但是如果并发量特别巨大时,主数据库不能同时处理高并发的请求,这时数据库容易宕机. 问题: 现在的问题是如何既能保证数据库正常运行,又能实现用户数据的入库操作? 解决方案: 引入rabbitMQ技术: 说明: 当数据库的访问压力过载时,这时会将过载以后的数据先保存到rabbitMQ中.其中的数据结构是队列的形式,先进先出.这时数据库从队列中取数据执行.一直到队列中的数据全部操作完成为止. RabbitMQ就是消息的中间件. RabbitMQ介
-
基于AngularJS的简单使用详解
Angular Js 的初步认识和使用 一: 1.模块化 定义模块和控制器 ng-app="myapp" controller="myctrl" 指定模型 ng-model="" 获取的属性值: ng-bind="属性名"或者{{属性名}} 2.初始化模块(在Script中进行) var myapp1 =angular.module("myapp",[]); 3.定义模块的控制器,并依赖注入, $scope
-
基于tomcat配置文件server.xml详解
1. 入门示例:虚拟主机提供web服务 该示例通过设置虚拟主机来提供web服务,因为是入门示例,所以设置极其简单,只需修改$CATALINA_HOME/conf/server.xml文件为如下内容即可.其中大部分都采用了默认设置,只是在engine容器中添加了两个Host容器. <?xml version="1.0" encoding="UTF-8"?> <Server port="8005" shutdown="SH
-
基于JavaScript表单脚本(详解)
什么是表单? 一个表单有三个基本组成部分: 表单标签:这里面包含了处理表单数据所用CGI程序的URL以及数据提交到服务器的方法. 表单域:包含了文本框.密码框.隐藏域.多行文本框.复选框.单选框.下拉选择框和文件上传框等. 表单按钮:包括提交按钮.复位按钮和一般按钮:用于将数据传送到服务器上的CGI脚本或者取消输入,还可以用表单按钮来控制其他定义了处理脚本的处理工作. JavaScript与表单间的关系:JS最初的应用就是用于分担服务器处理表单的责任,打破依赖服务器的局面,尽管目前web和jav
-
基于Vue单文件组件详解
本文将详细介绍Vue单文件组件 概述 在很多 Vue 项目中,使用 Vue.component 来定义全局组件,紧接着用 new Vue({ el: '#container '}) 在每个页面内指定一个容器元素. 这种方式在很多中小规模的项目中运作的很好,在这些项目里 JavaScript 只被用来加强特定的视图.但当在更复杂的项目中,或者前端完全由 JavaScript 驱动的时候,下面这些缺点将变得非常明显: 1.全局定义 (Global definitions) 强制要求每个 compon
-
基于canvas粒子系统的构建详解
前面的话 本文将从最基本的imageData对象的理论知识说开去,详细介绍canvas粒子系统的构建 imageData 关于图像数据imageData共有3个方法,包括getImageData().putImageData().createImageData() [getImageData()] 2D上下文可以通过getImageData()取得原始图像数据.这个方法接收4个参数:画面区域的x和y坐标以及该区域的像素宽度和高度 例如,要取得左上角坐标为(10,5).大小为50*50像素的区域的
-
基于Jexus-5.6.3使用详解
一.Jexus Web Server配置 在 jexus 的工作文件夹中(一般是"/usr/jexus")有一个基本的配置文件,文件名是"jws.conf". jws.conf 中至少有 SiteConfigDir 和 SiteLogDir 两行信息: SiteConfigDir=siteconf #指的是存放网站配置文件放在siteconf这个文件夹中,可以使用基于jws.exe文件的相对路径 SiteLogDir=log #指的是jexus日志文件放在log这个
-
基于Android RxCache使用方法详解
前言 我为什么使用这个库? 事实上Android开发中缓存功能的实现选择有很多种,File缓存,SP缓存,或者数据库缓存,当然还有一些简单的库/工具类,比如github上的这个: [ASimpleCache]:a simple cache for android and java 但是都不是很好用(虽然可能学习成本比较低,因为它使用起来相对简单),我可能需要很多的静态常量来作为key存储缓存数据value,并设置缓存的有效期,这可能需要很多Java代码去实现,并且过程繁琐. 如果您使用的网络请求
-
tornado+celery的简单使用详解
celery是实现一个简单,灵活可靠的分布式任务队列系统的好选择 tornado则不用过多介绍 在开发机上安装rabbitmq这里就不介绍了 首先是task文件的编写 task.py #coding=utf-8 from celery import Celery from celery.bin import worker as celery_worker import celeryconfig broker = 'amqp://' backend = 'amqp' app = Celery('c
-
基于ROS 服务通信模式详解
ROS 服务通信模式 摘自<ROS机器人开发实践> 服务(services)是节点之间通讯的另一种方式.服务允许节点发送请求(request) 并获得一个响应(response) AddTwoInts.h文件是根据AddTwoInts.srv文件生成的 还会自动生成 AddTwoIntsRequest.h AddTwoIntsResponse.h AddTwoInts.h所在的目录是 \catkin_ws\devel AddTwoInts.srv int64 a int64 b --- int