python Elasticsearch索引建立和数据的上传详解
今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch。
ok,先来介绍一下Elaticsearch,它是一款基于lucene的实时分布式搜索和分析引擎,是后台系统,用来存储数据,检索数据,属于完全命令行交互。
那为什么选择python作为脚本进行命令的写入和数据的上传呢?那是因为Python里面有固定的模板,可以上传数据到Elasticsearch。
接下来就聊一聊该如何编写代码:
我们上传数据之后,数据到哪里去了呢?
存在索引里面了。
那么,何为索引??可以理解为是一个文件用来存放数据的,可以算是单个数据库的同义词。
所以上传数据前的第一步就是建立索引了,以下为Python代码
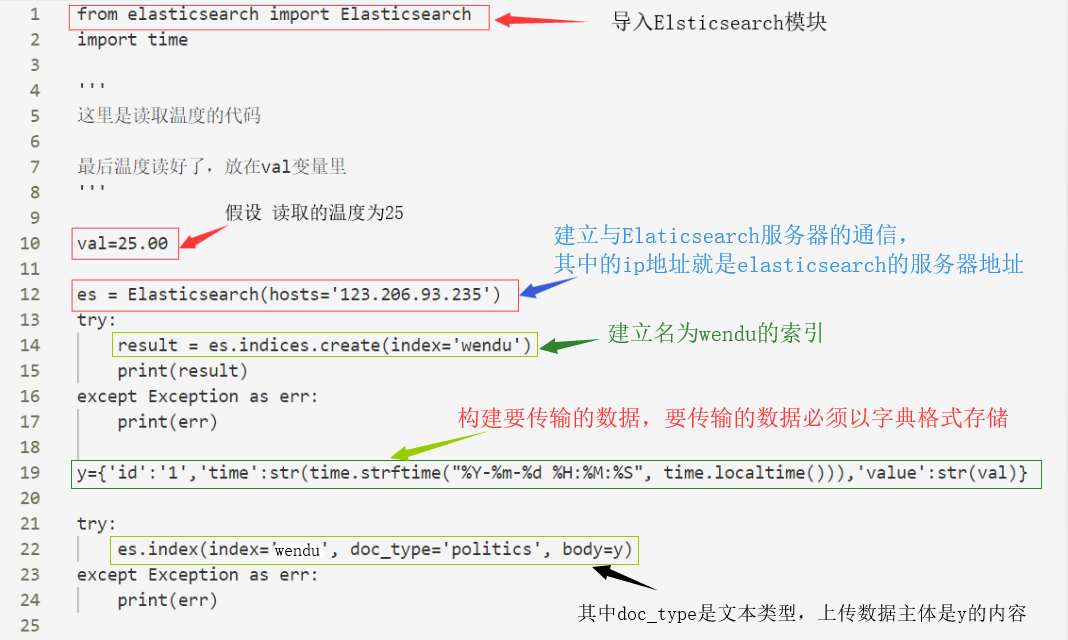
我是连接了一个温度传感器然后读取得到一个数据,按照本例来说就是默认25,传入一条数据至elasticsearch服务器。
如果索引建立成功他将会显示如下界面:

至此,基于python的Elaticsearch索引的建立和数据的上传就已经讲完啦,感谢大家的阅读和对我们的支持。
相关推荐
-
Python-ElasticSearch搜索查询的讲解
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Lucene 可能是目前存在的,不论开源还是私有的,拥有最先进,高性能和全功能搜索引擎功能的库.但是 Lucene 仅仅只是一个库.为了利用它,你需要编写 Java 程序,并在你的 java 程序里面直接集成 Lucene 包. 更坏的情况是,你需要对信息检索有一定程度的理解才能明白 Lucene 是怎么工作的.Lucene 是 很 复杂的. 在上一篇文章中介绍了ElasticS
-
Python对ElasticSearch获取数据及操作
使用Python对ElasticSearch获取数据及操作,供大家参考,具体内容如下 Version Python :2.7 ElasticSearch:6.3 代码: #!/usr/bin/env python # -*- coding: utf-8 -*- """ @Time : 2018/7/4 @Author : LiuXueWen @Site : @File : ElasticSearchOperation.py @Software: PyCharm @Descri
-

使用Python操作Elasticsearch数据索引的教程
Elasticsearch是一个分布式.Restful的搜索及分析服务器,Apache Solr一样,它也是基于Lucence的索引服务器,但我认为Elasticsearch对比Solr的优点在于: 轻量级:安装启动方便,下载文件之后一条命令就可以启动: Schema free:可以向服务器提交任意结构的JSON对象,Solr中使用schema.xml指定了索引结构: 多索引文件支持:使用不同的index参数就能创建另一个索引文件,Solr中需要另行配置: 分布式:Solr Cloud的配置比较
-
用python简单实现mysql数据同步到ElasticSearch的教程
之前博客有用logstash-input-jdbc同步mysql数据到ElasticSearch,但是由于同步时间最少是一分钟一次,无法满足线上业务,所以只能自己实现一个,但是时间比较紧,所以简单实现一个 思路: 网上有很多思路用什么mysql的binlog功能什么的,但是我对mysql了解实在有限,所以用一个很呆板的办法查询mysql得到数据,再插入es,因为数据量不大,而且10秒间隔同步一次,效率还可以,为了避免服务器之间的时间差和mysql更新和查询产生的时间差,所以在查询更新时间条件时是
-
安装ElasticSearch搜索工具并配置Python驱动的方法
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便. 我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的.我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单
-
python批量导入数据进Elasticsearch的实例
ES在之前的博客已有介绍,提供很多接口,本文介绍如何使用python批量导入.ES官网上有较多说明文档,仔细研究并结合搜索引擎应该不难使用. 先给代码 #coding=utf-8 from datetime import datetime from elasticsearch import Elasticsearch from elasticsearch import helpers es = Elasticsearch() actions = [] f=open('index.txt') i=
-
Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的. 存储以name_id为主键的索引,待插入或更新数据为: 一般会有有两种操作: 以下图片为个人见解,我没试过能不能直接运行,但形式上没错. 数据不存在,我需要插入地址为空字符串. 单条插入: 批量插入: 该数据存在,我需要更新地址字段为空字符串. 单条更新: 批量更新: 总结 以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的! 您可能感兴趣的文章: 使用
-
python Elasticsearch索引建立和数据的上传详解
今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch. ok,先来介绍一下Elaticsearch,它是一款基于lucene的实时分布式搜索和分析引擎,是后台系统,用来存储数据,检索数据,属于完全命令行交互. 那为什么选择python作为脚本进行命令的写入和数据的上传呢?那是因为Python里面有固定的模板,可以上传数据到Elasticsearch. 接下来就聊一聊该如何编写代码: 我们上传数据之后,数据到哪里去了呢? 存在索引里面了. 那
-
用Python实现定时备份Mongodb数据并上传到FTP服务器
实现的功能:在win7下,每天晚上1点,自动将 F:/data中所有文件进行压缩,以[mongodb+日期]命名,将压缩好的文件存储在本地目录 F:\MongoDbData\,然后将这个压缩好的文件上传到ftp://192.168.0.101/MongoDBup/目录下 分三步: 第一步:搭建FTP服务器,配置好FTP环境. 第二步:用python编写压缩文件并实现FTP上传的脚本第三步:使用win7自带的任务计划程序定时执行python脚本 1. 环境 Python:3.6.1Python I
-
Python Cloudinary实现图像和视频上传详解
Cloudinary提供了一个API,用于将图像.视频和任何其他类型的文件上传到云端.上传到Cloudinary的文件通过安全备份和修订历史记录安全存储在云中.Cloudinary的API允许从您的服务器.直接从访问者的浏览器或移动应用程序或通过远程公共URL获取安全上传. Cloudinary的Python SDK封装了Cloudinari的上传API并简化了集成.Python方法可用于轻松地将Python图像和视频上传到云端,Python视图助手方法可用于直接从浏览器上传到Cloudinar
-
Java大文件上传详解及实例代码
Java大文件上传详解 前言: 上周遇到这样一个问题,客户上传高清视频(1G以上)的时候上传失败. 一开始以为是session过期或者文件大小受系统限制,导致的错误.查看了系统的配置文件没有看到文件大小限制,web.xml中seesiontimeout是30,我把它改成了120.但还是不行,有时候10分钟就崩了. 同事说,可能是客户这里服务器网络波动导致网络连接断开,我觉得有点道理.但是我在本地测试的时候发觉上传也失败,网络原因排除. 看了日志,错误为: java.lang.OutOfMemor
-
node.js使用express框架进行文件上传详解
关于node.js使用express框架进行文件上传,主要来自于最近对Settings-Sync插件做的研究. 目前的研究算是取得的比较好的进展. Settings-Sync中通过快捷键上传文件,其实主要还是请求后端接口. 于是我便使用node.js模拟一个服务,这个服务其实就相当于github api(Settings-Sync实际请求的接口,比如token验证,gist存储创建等都是来自github 对应的api). 话不多说,直接代码贴起讲解: 1.创建一个node.js项目(这里我以ex
-
java使用webuploader实现跨域上传详解
前言 项目中使用webuploader进行文件上传,需要用到跨域,查看webuploader的issues发现是支持上传的,但是他们写的回复都是不清不白的,有点迷糊:想了半天才知道咋回事,也可能是我比较笨,再次记录下java中详细的处理. webuploader进行上传,会执行2个请求:一个option请求,一个post(根据你的webuploader的配置method 值决定),需要在option请求中对响应头进行处理,post响应头也进行响应的处理. 以servlet为例: @WebServ
-
Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主要又分为描述统计学和推断统计学.给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学.另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学. 2.数据的概括性度量: 1)集中趋势的度量: 众数:众数(Mode
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
SpringBoot+Elasticsearch实现数据搜索的方法详解
目录 一.简介 二.代码实践 2.1.导入依赖 2.2.配置环境变量 2.3.创建 elasticsearch 的 config 类 2.4.索引管理 2.5.文档管理 三.小结 一.简介 在上篇 ElasticSearch 文章中,我们详细的介绍了 ElasticSearch 的各种 api 使用. 实际的项目开发过程中,我们通常基于某些主流框架平台进行技术开发,比如 SpringBoot,今天我们就以 SpringBoot 整合 ElasticSearch 为例,给大家详细的介绍 Elast
-
python FastApi实现数据表迁移流程详解
目录 啥是数据迁移 1.需要新的数据表 2.需要对现有表结构进行调整 回到ORM 迁移手段 安装alembic 初始化项目 修改alembic.ini 修改alembic/env.py 开始生成迁移工作 变更数据库 FAQ 啥是数据迁移 在我们平时的开发过程中,经常需要对一些数据进行调整.一般会有以下几种场景: 1.需要新的数据表 我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能. 大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库)