ML神器:sklearn的快速使用及入门
传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类。本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及它们的用法是怎么样的。希望你看完这篇文章可以最为快速的开始你的学习任务。
1. 获取数据
1.1 导入sklearn数据集
sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的理解和把握。(这一步我也亟需加强,一起加油!^-^)
首先呢,要想使用sklearn中的数据集,必须导入datasets模块:
from sklearn import datasets
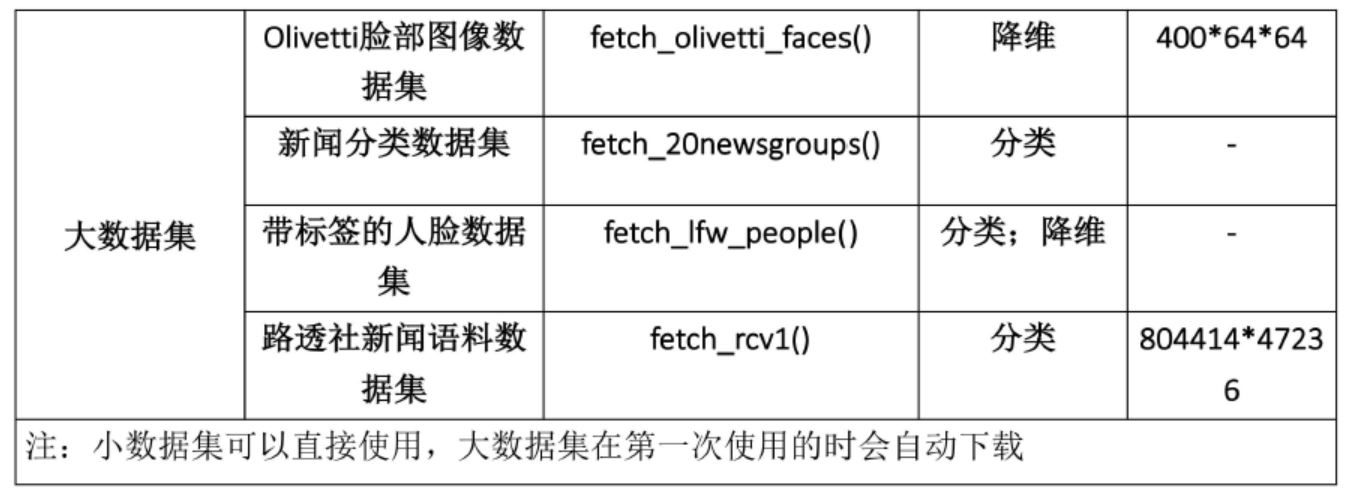
下图中包含了大部分sklearn中数据集,调用方式也在图中给出,这里我们拿iris的数据来举个例子:

iris = datasets.load_iris() # 导入数据集 X = iris.data # 获得其特征向量 y = iris.target # 获得样本label
1.2 创建数据集
你除了可以使用sklearn自带的数据集,还可以自己去创建训练样本,具体用法参见《Dataset loading utilities》,这里我们简单介绍一些,sklearn中的samples generator包含的大量创建样本数据的方法:


下面我们拿分类问题的样本生成器举例子:
from sklearn.datasets.samples_generator import make_classification X, y = make_classification(n_samples=6, n_features=5, n_informative=2, n_redundant=2, n_classes=2, n_clusters_per_class=2, scale=1.0, random_state=20) # n_samples:指定样本数 # n_features:指定特征数 # n_classes:指定几分类 # random_state:随机种子,使得随机状可重
>>> for x_,y_ in zip(X,y): print(y_,end=': ') print(x_) 0: [-0.6600737 -0.0558978 0.82286793 1.1003977 -0.93493796] 1: [ 0.4113583 0.06249216 -0.90760075 -1.41296696 2.059838 ] 1: [ 1.52452016 -0.01867812 0.20900899 1.34422289 -1.61299022] 0: [-1.25725859 0.02347952 -0.28764782 -1.32091378 -0.88549315] 0: [-3.28323172 0.03899168 -0.43251277 -2.86249859 -1.10457948] 1: [ 1.68841011 0.06754955 -1.02805579 -0.83132182 0.93286635]
2. 数据预处理
数据预处理阶段是机器学习中不可缺少的一环,它会使得数据更加有效的被模型或者评估器识别。下面我们来看一下sklearn中有哪些平时我们常用的函数:
from sklearn import preprocessing
2.1 数据归一化
为了使得训练数据的标准化规则与测试数据的标准化规则同步,preprocessing中提供了很多Scaler:
data = [[0, 0], [0, 0], [1, 1], [1, 1]] # 1. 基于mean和std的标准化 scaler = preprocessing.StandardScaler().fit(train_data) scaler.transform(train_data) scaler.transform(test_data) # 2. 将每个特征值归一化到一个固定范围 scaler = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(train_data) scaler.transform(train_data) scaler.transform(test_data) #feature_range: 定义归一化范围,注用()括起来
2.2 正则化(normalize)
当你想要计算两个样本的相似度时必不可少的一个操作,就是正则化。其思想是:首先求出样本的p-范数,然后该样本的所有元素都要除以该范数,这样最终使得每个样本的范数都为1。
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
2.3 one-hot编码
one-hot编码是一种对离散特征值的编码方式,在LR模型中常用到,用于给线性模型增加非线性能力。
data = [[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]] encoder = preprocessing.OneHotEncoder().fit(data) enc.transform(data).toarray()
3. 数据集拆分
在得到训练数据集时,通常我们经常会把训练数据集进一步拆分成训练集和验证集,这样有助于我们模型参数的选取。
# 作用:将数据集划分为 训练集和测试集 # 格式:train_test_split(*arrays, **options) from sklearn.mode_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) """ 参数 --- arrays:样本数组,包含特征向量和标签 test_size: float-获得多大比重的测试样本 (默认:0.25) int - 获得多少个测试样本 train_size: 同test_size random_state: int - 随机种子(种子固定,实验可复现) shuffle - 是否在分割之前对数据进行洗牌(默认True) 返回 --- 分割后的列表,长度=2*len(arrays), (train-test split) """
4. 定义模型
在这一步我们首先要分析自己数据的类型,搞清出你要用什么模型来做,然后我们就可以在sklearn中定义模型了。sklearn为所有模型提供了非常相似的接口,这样使得我们可以更加快速的熟悉所有模型的用法。在这之前我们先来看看模型的常用属性和功能:
# 拟合模型 model.fit(X_train, y_train) # 模型预测 model.predict(X_test) # 获得这个模型的参数 model.get_params() # 为模型进行打分 model.score(data_X, data_y) # 线性回归:R square; 分类问题: acc
4.1 线性回归
from sklearn.linear_model import LinearRegression # 定义线性回归模型 model = LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1) """ 参数 --- fit_intercept:是否计算截距。False-模型没有截距 normalize: 当fit_intercept设置为False时,该参数将被忽略。 如果为真,则回归前的回归系数X将通过减去平均值并除以l2-范数而归一化。 n_jobs:指定线程数 """

4.2 逻辑回归LR
from sklearn.linear_model import LogisticRegression # 定义逻辑回归模型 model = LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1) """参数 --- penalty:使用指定正则化项(默认:l2) dual: n_samples > n_features取False(默认) C:正则化强度的反,值越小正则化强度越大 n_jobs: 指定线程数 random_state:随机数生成器 fit_intercept: 是否需要常量 """
4.3 朴素贝叶斯算法NB
from sklearn import naive_bayes model = naive_bayes.GaussianNB() # 高斯贝叶斯 model = naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None) model = naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None) """ 文本分类问题常用MultinomialNB 参数 --- alpha:平滑参数 fit_prior:是否要学习类的先验概率;false-使用统一的先验概率 class_prior: 是否指定类的先验概率;若指定则不能根据参数调整 binarize: 二值化的阈值,若为None,则假设输入由二进制向量组成 """
4.4 决策树DT
from sklearn import tree model = tree.DecisionTreeClassifier(criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False) """参数 --- criterion :特征选择准则gini/entropy max_depth:树的最大深度,None-尽量下分 min_samples_split:分裂内部节点,所需要的最小样本树 min_samples_leaf:叶子节点所需要的最小样本数 max_features: 寻找最优分割点时的最大特征数 max_leaf_nodes:优先增长到最大叶子节点数 min_impurity_decrease:如果这种分离导致杂质的减少大于或等于这个值,则节点将被拆分。 """
4.5 支持向量机SVM
from sklearn.svm import SVC model = SVC(C=1.0, kernel='rbf', gamma='auto') """参数 --- C:误差项的惩罚参数C gamma: 核相关系数。浮点数,If gamma is ‘auto' then 1/n_features will be used instead. """
4.6 k近邻算法KNN
from sklearn import neighbors #定义kNN分类模型 model = neighbors.KNeighborsClassifier(n_neighbors=5, n_jobs=1) # 分类 model = neighbors.KNeighborsRegressor(n_neighbors=5, n_jobs=1) # 回归 """参数 --- n_neighbors: 使用邻居的数目 n_jobs:并行任务数 """
4.7 多层感知机(神经网络)
from sklearn.neural_network import MLPClassifier
# 定义多层感知机分类算法
model = MLPClassifier(activation='relu', solver='adam', alpha=0.0001)
"""参数
---
hidden_layer_sizes: 元祖
activation:激活函数
solver :优化算法{‘lbfgs', ‘sgd', ‘adam'}
alpha:L2惩罚(正则化项)参数。
"""
5. 模型评估与选择篇
5.1 交叉验证
from sklearn.model_selection import cross_val_score cross_val_score(model, X, y=None, scoring=None, cv=None, n_jobs=1) """参数 --- model:拟合数据的模型 cv : k-fold scoring: 打分参数-‘accuracy'、‘f1'、‘precision'、‘recall' 、‘roc_auc'、'neg_log_loss'等等 """
5.2 检验曲线
使用检验曲线,我们可以更加方便的改变模型参数,获取模型表现。
from sklearn.model_selection import validation_curve train_score, test_score = validation_curve(model, X, y, param_name, param_range, cv=None, scoring=None, n_jobs=1) """参数 --- model:用于fit和predict的对象 X, y: 训练集的特征和标签 param_name:将被改变的参数的名字 param_range: 参数的改变范围 cv:k-fold 返回值 --- train_score: 训练集得分(array) test_score: 验证集得分(array) """
6. 保存模型
最后,我们可以将我们训练好的model保存到本地,或者放到线上供用户使用,那么如何保存训练好的model呢?主要有下面两种方式:
6.1 保存为pickle文件
import pickle
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)
6.2 sklearn自带方法
from sklearn.externals import joblib
# 保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
对sklearn的使用之数据集的拆分与训练详解(python3.6)
研修课上讲了两个例子,融合一下. 主要演示大致的过程: 导入->拆分->训练->模型报告 以及几个重要问题: ①标签二值化 ②网格搜索法调参 ③k折交叉验证 ④增加噪声特征(之前涉及) from sklearn import datasets #从cross_validation导入会出现warning,说已弃用 from sklearn.model_selection import train-test_split from sklearn.grid_search import Gri
-
Python使用sklearn库实现的各种分类算法简单应用小结
本文实例讲述了Python使用sklearn库实现的各种分类算法简单应用.分享给大家供大家参考,具体如下: KNN from sklearn.neighbors import KNeighborsClassifier import numpy as np def KNN(X,y,XX):#X,y 分别为训练数据集的数据和标签,XX为测试数据 model = KNeighborsClassifier(n_neighbors=10)#默认为5 model.fit(X,y) predicted = m
-
使用sklearn之LabelEncoder将Label标准化的方法
LabelEncoder可以将标签分配一个0-n_classes-1之间的编码 将各种标签分配一个可数的连续编号: >>> from sklearn import preprocessing >>> le = preprocessing.LabelEncoder() >>> le.fit([1, 2, 2, 6]) LabelEncoder() >>> le.classes_ array([1, 2, 6]) >>>
-
使用sklearn进行对数据标准化、归一化以及将数据还原的方法
在对模型训练时,为了让模型尽快收敛,一件常做的事情就是对数据进行预处理. 这里通过使用sklearn.preprocess模块进行处理. 一.标准化和归一化的区别 归一化其实就是标准化的一种方式,只不过归一化是将数据映射到了[0,1]这个区间中. 标准化则是将数据按照比例缩放,使之放到一个特定区间中.标准化后的数据的均值=0,标准差=1,因而标准化的数据可正可负. 二.使用sklearn进行标准化和标准化还原 原理: 即先求出全部数据的均值和方差,再进行计算. 最后的结果均值为0,方差是1,从公
-
Python使用sklearn实现的各种回归算法示例
本文实例讲述了Python使用sklearn实现的各种回归算法.分享给大家供大家参考,具体如下: 使用sklearn做各种回归 基本回归:线性.决策树.SVM.KNN 集成方法:随机森林.Adaboost.GradientBoosting.Bagging.ExtraTrees 1. 数据准备 为了实验用,我自己写了一个二元函数,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3.其中x1的取值范围是0~50,x2的取值范围是-10~10,x1和x2的训练集一共有5
-
ML神器:sklearn的快速使用及入门
传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类.本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及它们的用法是怎么样的.希望你看完这篇文章可以最为快速的开始你的学习任务. 1. 获取数据 1.1 导入sklearn数据集 sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论
-
Playwright快速上手指南(入门教程)
目录 1. 为什么选择Playwright 1.1 Playwright的优势 1.2 已知局限性 2. Playwright使用 2.1 安装 2.2 自动录制 2.3 定制化编写 2.4 网络拦截(Mock接口),示例如下: 2.6 异步执行,示例如下: 2.7 Pytest结合,示例如下: 2.8 移动端操作,示例如下: 3. 总结 Playwright是由微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium.Fi
-

Gradle快速安装及入门
1.什么是Gradle Gradle是一种结合了Ant和Maven两者优势的下一代构建工具,既有Ant构建灵活性的优点,也保留Maven约定优于配置的思想,在灵活构建和约定构建之间达到了很好的平衡. 2.安装Gradle (1)Gradle属于解压配置即可使用的软件 下载解压gradle-4.1-all.zip,例如解压到:D:/ gradle-4.1 (2)window中设置gradle环境变量: GRADLE_HOME D:/ gradle-4.1 path
-
python常用库之NumPy和sklearn入门
Numpy 和 scikit-learn 都是python常用的第三方库.numpy库可以用来存储和处理大型矩阵,并且在一定程度上弥补了python在运算效率上的不足,正是因为numpy的存在使得python成为数值计算领域的一大利器:sklearn是python著名的机器学习库,它其中封装了大量的机器学习算法,内置了大量的公开数据集,并且拥有完善的文档,因此成为目前最受欢迎的机器学习学习与实践的工具. 1. NumPy库 首先导入Numpy库 import numpy as np 1.1 nu
-
快速入门python学习笔记
本篇不是教给大家如何去学习python,有需要详细深入学习的朋友可以参阅:Python基础语言学习笔记总结(精华)本文通过一周快速学习python入门知识总计了学习笔记和心得,分享给大家. ##一:语法元素 ###1.注释,变量,空格的使用 注释 单行注释以#开头,多行注释以''开头和结尾 变量 变量前面不需要声明数据类型,但是必须赋值 变量命名可以使用大小写字母,数字和下划线的组合,但是首字母只能是大小写字母或者下划线,不能使用空格 中文等非字母符号也可以作为名字 空格的使用 表示缩进关系的空
-
centos7.2搭建nginx的web服务器部署uniapp项目
Panther 从一位小白走来,虽然现在也还是小白,但是我取之于民,不定时将自己所学到的都分享给大家,在上一篇博客中有讲到thingsboard的多设备共显,因为现在处于学习的阶段接触的东西比较多同样也比较杂,希望我的文章可以给大家提供一丢丢的帮助 one 购买腾讯云 https://cloud.tencent.com/ 产品 – 云服务器 – 立即选购 – 快速配置 – 地域 – 入门配置 – centos 7.2 – 购买 事例控制台 https://console.cloud.tencen
-
如何使用 vue-cli 创建模板项目
场景 吾辈曾经只是个 Java 后端开发人员,原本对前端的了解大致只有 HTML/CSS/JavaScript/JQuery 级别,后来接触到了 nodejs.不仅是工作之需,吾辈个人而言也非常想要了解现代前端技术.然而天可怜见,吾辈刚入门 nodejs 并没有发现什么,但发现想要构建一个项目,需要用到前端工具链实在太多了.配置文件的数量甚至远远超过后端. 所以为了快速开发,入门之后遇到问题再去解决,吾辈选择了使用 nodejs + npm + vuejs + webpack + vscode
-
新手如何快速入门Python(菜鸟必看篇)
学习任何一门语言都是从入门(1年左右),通过不间断练习达到熟练水准(3到5年),少数人最终能精通语言,成为执牛耳者,他们是金字塔的最顶层.虽然万事开头难,但好的开始是成功的一半,今天这篇文章就来谈谈如何开始入门Python.只要方向对了,就不怕路远. 设定目标 当你决定入门 Python 时,需要一个清晰且短期内可实现的目标,比如通过学习找一份初级程序员工作,目标明确后,你需要了解企业对初级程序员有哪些技能要求,下面是我从拉勾网找的一个初级 Python 工程师的任职要求: 1.熟悉 Pytho
-
Appium的使用与入门(这款神器你值得拥有)
从石器时代开始,原始人来已经开始学会制造并使用工具,以满足自己的生活所需,这也是人类和动物最本质的区别,人类懂得制造并使用工具而动物不会. 21 世纪的现代社会更是如此,企业与企业之间是人才的竞争,而人的竞争力则严重依赖其会使用工具的多少以及熟练程度,毕竟古人有云:「君子生非异也,善假于物也」. 软件测试作为软件发布前的最后一个环节,起着至关重要的作用.虽然在很多公司里相对于开发来讲,公司对测试岗都不太重视,但这绝对不能掩盖其地位的重要性,稍有疏漏,就可能给公司带来巨大的损失. 纵观国内各公司大
-
hibernate4快速入门实例详解
Hibernate是什么 Hibernate是一个轻量级的ORMapping框架 ORMapping原理(Object RelationalMapping) ORMapping基本对应规则: 1:类跟表相对应 2:类的属性跟表的字段相对应 3:类的实例与表中具体的一条记录相对应 4:一个类可以对应多个表,一个表也可以对应对个类 5:DB中的表可以没有主键,但是Object中必须设置主键字段 6:DB中表与表之间的关系(如:外键)映射成为Object之间的关系 7:Object中属性的个数和名称可