java字节字符转换流操作详解
本文实例讲述了java字节字符转换流操作。分享给大家供大家参考,具体如下:
一 基本概念
1、认识文本和文本文件
java的文本(char)是16位无符号,是字符的unicode编码(双字节编码)
文件是byte byte byte 的数据序列
文本文件是文本(char)序列按照某种编码方案(utf-8,utf-16be,gbk)序列化为byte的存储结果。
2、字符流(Reader Writer)---操作的都是文本文件
字符的处理:一次处理一个字符
字符的底层任然是基本的字节序列
3、字符流的基本实现
InputStreamReader完成byte流解析未char流,按照编码解析
OutputStreamWriter 提供完成char流到byte流,按照编码处理
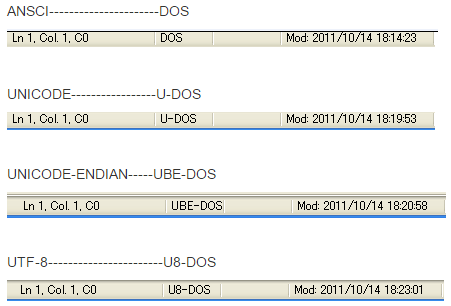
4、UE编码查看方法
UltraEdit-32的状态栏可以显示文件的编码类型,详细情况如下:
5、Myeclipse编码查看方法
Project->Property->Resource
二 实例
package com.imooc.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class IsrAndOswDemo {
public static void main(String[] args)throws IOException {
FileInputStream in = new FileInputStream("e:\\javaio\\test2.txt");
InputStreamReader isr = new InputStreamReader(in,"utf-8");//默认项目的编码,操作的时候,要写文件本身的编码格式
FileOutputStream out = new FileOutputStream("e:\\javaio\\test1.txt");
OutputStreamWriter osw = new OutputStreamWriter(out,"utf-8");
/*int c ;
while((c = isr.read())!=-1){
System.out.print((char)c);
}*/
char[] buffer = new char[8*1024];
int c;
/*批量读取,放入buffer这个字符数组,从第0个位置开始放置,最多放buffer.length个
返回的是读到的字符的个数
*/
while(( c = isr.read(buffer,0,buffer.length))!=-1){
String s = new String(buffer,0,c);
System.out.print(s);
osw.write(buffer,0,c);
osw.flush();
}
isr.close();
osw.close();
}
}
三 运行结果
中国1jd
四 说明
用UE创建的utf-8和用myeclipse创建的utf-8,文件大小不一样,该程序是用myeclipse创建的utf-8进行测试的。
五 utf-8无bom和utf-8什么区别
utf-8+bom比utf-8多了三个字节前缀:0xEF0xBB0xBF,有这三个字节前缀的文本或字符串,程序可以自动判断它为utf-8格式,并按照utf-8格式来解析文本或字符串,否则,一个文本或者字符串在未知编码的情况下,需要按照字符编码规范去一个个验证
六 utf-8编码说明
https://baike.baidu.com/item/UTF-8/481798?fr=aladdin
七 编码实例
打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit中的”编辑-十六进制函数“,观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的。
2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25。
3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储。
4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的。
更多关于java相关内容感兴趣的读者可查看本站专题:《Java字符与字符串操作技巧总结》、《Java数组操作技巧总结》、《Java数学运算技巧总结》、《Java数据结构与算法教程》及《Java操作DOM节点技巧总结》
希望本文所述对大家java程序设计有所帮助。
相关推荐
-
Java实现输入流转化为String
在平时Java开发时,难免会遇见输入流转化为String类型的需求,我从事Android开发经常会遇见这样的需求,于是我将这个做成一个工具类分享给大家,希望能帮助大家,这也是我第一次写个人博客,希望大家支持.谢谢! public static String streamToString(InputStream is) { BufferedReader reader = new BufferedReader(new InputStreamReader(is)); //new一个StringBuff
-
java编程中字节流转换成字符流的实现方法
java编程中字节流转换成字符流的实现方法 import java.io.*; /*readLine方法是字符流BufferReader类中的方法 * 而键盘录入的方法是字节流InputStream的方法 * 那么能不能将字节流转成字符流再使用字符流缓冲区中的readLine方法呢? * * InputStreamReader类是字节流转向字符流的桥梁.(它本身是一个字符流所以在构造时接受一个字节流) * * */ public class TransStreamDemo { public st
-
Java实现文件和base64流的相互转换功能示例
本文实例讲述了Java实现文件和base64流的相互转换功能.分享给大家供大家参考,具体如下: import java.io.FileInputStream; import java.io.FileOutputStream; import sun.misc.BASE64Decoder; import sun.misc.BASE64Encoder; /** * 文件与base64的互相转换操作 */ public class testFile { public static void main(S
-

java字符流缓冲区详解
本文实例为大家分享了java字符流缓冲区的具体方法,供大家参考,具体内容如下 1. 为什么要缓冲区? 程序频繁地操作一个资源(如文件),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入到内存的一块区域中,以后直接从此区域中读取数据即可,因为读内存速度比较快,这样提高性能.在IO中引入缓冲区,主要是提高流的读写效率. 2. 缓冲技术的原理? 总的来说,缓冲区就是内存里的一块区域,把数据先存内存里,然后一次性写入,类似数据库的批量操作,这样效率比较高 3. BufferedWriter类
-
Java字符流和字节流对文件操作的区别
记得当初自己刚开始学习Java的时候,对Java的IO流这一块特别不明白,所以写了这篇随笔希望能对刚开始学习Java的人有所帮助,也方便以后自己查询.Java的IO流分为字符流(Reader,Writer)和字节流(InputStream,OutputStream),字节流顾名思义字节流就是将文件的内容读取到字节数组,然后再输出到另一个文件中.而字符流操作的最小单位则是字符.可以先看一下IO流的概述: 下面首先是通过字符流对文件进行读取和写入: package lib; import java.
-
Java字节流与基本数据类型的转换实例
在实际开发中,我们经常遇到与嵌入式进行通信的情况,而由于一些嵌入式设备的处理能力较差,往往以二进制的数据流的形式传输数据,在此将这些常见的转换做一总结. 注意:默认传输时使用小端模式 将字节流转换为int类型数据 public static int getInt(byte[] bytes) { return (0xff & bytes[0]) | (0xff00 & (bytes[1] << 8)) | (0xff0000 & (bytes[2] << 16
-
详解Java中字符流与字节流的区别
本文为大家分析了Java中字符流与字节流的区别,供大家参考,具体内容如下 1. 什么是流 Java中的流是对字节序列的抽象,我们可以想象有一个水管,只不过现在流动在水管中的不再是水,而是字节序列.和水流一样,Java中的流也具有一个"流动的方向",通常可以从中读入一个字节序列的对象被称为输入流:能够向其写入一个字节序列的对象被称为输出流. 2. 字节流 Java中的字节流处理的最基本单位为单个字节,它通常用来处理二进制数据.Java中最基本的两个字节流类是InputStream和Out
-
Java 中IO流字符流详解及实例
Java-IO流 字符流 java的文本(char)是16位无符号整数,是字符的unicode编码(双字节编码). 文件是byte byte byte ... 的数据序列. 文本文件是文本(char)序列按照某种编码方案(uft-8.utf-16be.gbk)序列化为byte的存储结果. 字符流(Reader.Writer)-->操作的是文本.文本文件 1.字符的处理,一次处理一个字符 2.字符的底层仍然是基本的字节序列 3.字符流的基本实现: InputStreamReader是字节流通向字符
-
Java编程中字节流与字符流IO操作示例
IO流基本概念 IO流用来处理设备之间的数据传输 Java对数据的操作是通过流的方式 Java用于操作流的对象都是在IO包上 流按操作数据分为两种:字节流和字符流 流按流向分为:输入流,输出流. 字节流的抽象基类:InputStream,OutputStream 字符流的抽象基类:Reader,Writer 注:由这4个类派生出来的子类名称都是以其父类名作为子类名的后缀. 如:InputStream的子类:FileInputStream 如:Reader的子类FileReader 如创建一个F
-
详解Java编程中面向字符的输出流
面向字符的输出流都是类 Writer 的子类,其类层次结构如图所示. 下表列出了 Writer 的主要子类及说明. 使用 FileWriter 类写入文件 FileWriter 类是 Writer 子类 OutputStreamWriter 类的子类,因此 FileWriter 类既可以使用 Writer类的方法也可以使用 OutputStreamWriter 类的方法来创建对象. 在使用 FileWriter 类写入文件时,必须先调用 FileWriter()构造方法创建 FileWriter
-
详细解读Java编程中面向字符的输入流
字符流是针对字符数据的特点进行过优化的,因而提供一些面向字符的有用特性,字符流的源或目标通常是文本文件. Reader和Writer是java.io包中所有字符流的父类.由于它们都是抽象类,所以应使用它们的子类来创建实体对象,利用对象来处理相关的读写操作.Reader和Writer的子类又可以分为两大类:一类用来从数据源读入数据或往目的地写出数据(称为节点流),另一类对数据执行某种处理(称为处理流). 面向字符的输入流类都是Reader的子类,其类层次结构如图所示. 下表列出了 Reader 的
-
Java字符流与字节流区别与用法分析
本文实例讲述了Java字符流与字节流区别与用法.分享给大家供大家参考,具体如下: 字节流与字符流主要的区别是他们的的处理方式 流分类: 1.Java的字节流 InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先. 2.Java的字符流 Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先. InputStream,OutputStream,Reader,writer都是抽象类.所以不能直接new 字节流是最基本的,所有的Inpu