Python数据分析之Python和Selenium爬取BOSS直聘岗位
一、数据爬取的代码
#encoding='utf-8'
from selenium import webdriver
import time
import re
import pandas as pd
import os
def close_windows():
#如果有登录弹窗,就关闭
try:
time.sleep(0.5)
if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("closeIcon"):
dr.find_element_by_class_name("jconfirm").find_element_by_class_name("closeIcon").click()
except BaseException as e:
print('close_windows,没有弹窗',e)
def get_current_region_job(k_index):
flag = 0
# page_num_set=0#每区获取多少条数据,对30取整
df_empty = pd.DataFrame(columns=['岗位', '地点', '薪资', '工作经验', '学历', '公司', '技能'])
while (flag == 0):
# while (page_num_set<151)&(flag == 0):#每次只能获取150条信息
time.sleep(0.5)
close_windows()
job_list = dr.find_elements_by_class_name("job-primary")
for job in job_list:#获取当前页的职位30条
job_name = job.find_element_by_class_name("job-name").text
# print(job_name)
job_area = job.find_element_by_class_name("job-area").text
salary = job.find_element_by_class_name("red").get_attribute("textContent") # 获取薪资
# salary_raw = job.find_element_by_class_name("red").get_attribute("textContent") # 获取薪资
# salary_split = salary_raw.split('·') # 根据·分割
# salary = salary_split[0] # 只取薪资,去掉多少薪
# if re.search(r'天', salary):
# continue
experience_education = job.find_element_by_class_name("job-limit").find_element_by_tag_name(
"p").get_attribute("innerHTML")
# experience_education_raw = '1-3年<em class="vline"></em>本科'
experience_education_raw = experience_education
split_str = re.search(r'[a-zA-Z =<>/"]{23}', experience_education_raw) # 搜索分割字符串<em class="vline"></em>
# print(split_str)
experience_education_replace = re.sub(r'[a-zA-Z =<>/"]{23}', ",", experience_education_raw) # 分割字符串替换为逗号
# print(experience_education_replace)
experience_education_list = experience_education_replace.split(',') # 根据逗号分割
# print('experience_education_list:',experience_education_list)
if len(experience_education_list)!=2:
print('experience_education_list不是2个,跳过该数据',experience_education_list)
break
experience = experience_education_list[0]
education = experience_education_list[1]
# print(experience)
# print(education)
company = job.find_element_by_class_name("company-text").find_element_by_class_name("name").text
skill_list = job.find_element_by_class_name("tags").find_elements_by_class_name("tag-item")
skill = []
for skill_i in skill_list:
skill_i_text = skill_i.text
if len(skill_i_text) == 0:
continue
skill.append(skill_i_text)
# print(job_name)
# print(skill)
df_empty.loc[k_index, :] = [job_name, job_area, salary, experience, education, company, skill]
k_index = k_index + 1
# page_num_set=page_num_set+1
print("已经读取数据{}条".format(k_index))
close_windows()
try:#点击下一页
cur_page_num=dr.find_element_by_class_name("page").find_element_by_class_name("cur").text
# print('cur_page_num',cur_page_num)
#点击下一页
element = dr.find_element_by_class_name("page").find_element_by_class_name("next")
dr.execute_script("arguments[0].click();", element)
time.sleep(1)
# print('点击下一页')
new_page_num=dr.find_element_by_class_name("page").find_element_by_class_name("cur").text
# print('new_page_num',new_page_num)
if cur_page_num==new_page_num:
flag = 1
break
except BaseException as e:
print('点击下一页错误',e)
break
print(df_empty)
if os.path.exists("数据.csv"):#存在追加,不存在创建
df_empty.to_csv('数据.csv', mode='a', header=False, index=None, encoding='gb18030')
else:
df_empty.to_csv("数据.csv", index=False, encoding='gb18030')
return k_index
def main():
# 打开浏览器
# dr = webdriver.Firefox()
global dr
dr = webdriver.Chrome()
# dr = webdriver.Ie()
# # 后台打开浏览器
# option=webdriver.ChromeOptions()
# option.add_argument('headless')
# dr = webdriver.Chrome(chrome_options=option)
# print("打开浏览器")
# 将浏览器最大化显示
dr.maximize_window()
# 转到目标网址
# dr.get("https://www.zhipin.com/job_detail/?query=Python&city=100010000&industry=&position=")#全国
dr.get("https://www.zhipin.com/c101010100/?query=Python&ka=sel-city-101010100")#北京
print("打开网址")
time.sleep(5)
k_index = 0#数据条数、DataFrame索引
flag_hot_city=0
for i in range(3,17,1):
# print('第',i-2,'页')
# try:
# 获取城市
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i].click()#防止弹窗,改为下面两句
# element_hot_city_list_first = hot_city_list[i]
dr.execute_script("arguments[0].click();", hot_city_list[i])
# 输出城市名
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('城市:{}'.format(i-2),hot_city_list[i].text)
time.sleep(0.5)
# 获取区县
for j in range(1,50,1):
# print('第', j , '个区域')
# try:
# close_windows()
# hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
# 在这个for循环点一下城市,不然识别不到当前页面已经更新了
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i].click()#防止弹窗,改为下面
dr.execute_script("arguments[0].click();", hot_city_list[i])
#输出区县名称
close_windows()
city_district = dr.find_element_by_class_name("condition-district").find_elements_by_tag_name("a")
if len(city_district)==j:
print('遍历完所有区县,没有不可点击的,跳转下一个城市')
break
print('区县:',j, city_district[j].text)
# city_district_value=city_district[j].text#当前页面的区县值
# 点击区县
close_windows()
city_district= dr.find_element_by_class_name("condition-district").find_elements_by_tag_name("a")
close_windows()
# city_district[j].click()]#防止弹窗,改为下面两句
# element_city_district = city_district[j]
dr.execute_script("arguments[0].click();", city_district[j])
#判断区县是不是点完了
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('点击后这里应该是区县', hot_city_list[1].text)#如果是不限,说明点完了,跳出
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('如果点完了,这里应该是不限:',hot_city_list[1].text)
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
if hot_city_list[1].text == '不限':
print('当前区县已经点完了,点击下一个城市')
flag_hot_city=1
break
close_windows()
k_index = get_current_region_job(k_index)#获取职位,爬取数据
# 重新点回城市页面,再次获取区县。但此时多了区县,所以i+1
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i+1].click()#防止弹窗,改为下面两句
# element_hot_city_list_again = hot_city_list[i+1]
dr.execute_script("arguments[0].click();", hot_city_list[i+1])
# except BaseException as e:
# print('main的j循环-获取区县发生错误:', e)
# close_windows()
time.sleep(0.5)
# except BaseException as e:
# print('main的i循环发生错误:',e)
# close_windows()
time.sleep(0.5)
# 退出浏览器
dr.quit()
# p1.close()
if __name__ == '__main__':
main()
二、获取到的数据如图所示

三、数据分析的代码
# coding=utf-8
import collections
import wordcloud
import re
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号
def create_dir_not_exist(path): # 判断文件夹是否存在,不存在-新建
if not os.path.exists(path):
os.mkdir(path)
create_dir_not_exist(r'./image')
create_dir_not_exist(r'./image/city')
data = pd.read_csv('数据.csv', encoding='gb18030')
data_df = pd.DataFrame(data)
print("\n查看是否有缺失值\n", data_df.isnull().sum())
data_df_del_empty = data_df.dropna(subset=['岗位'], axis=0)
# print("\n删除缺失值‘岗位'的整行\n",data_df_del_empty)
data_df_del_empty = data_df_del_empty.dropna(subset=['公司'], axis=0)
# print("\n删除缺失值‘公司'的整行\n",data_df_del_empty)
print("\n查看是否有缺失值\n", data_df_del_empty.isnull().sum())
print('去除缺失值后\n', data_df_del_empty)
data_df_python_keyword = data_df_del_empty.loc[data_df_del_empty['岗位'].str.contains('Python|python')]
# print(data_df_python_keyword)#筛选带有python的行
# 区间最小薪资
data_df_python_keyword_salary = data_df_python_keyword['薪资'].str.split('-', expand=True)[0]
print(data_df_python_keyword_salary) # 区间最小薪资
# Dataframe新增一列 在第 列新增一列名为' ' 的一列 数据
data_df_python_keyword.insert(7, '区间最小薪资(K)', data_df_python_keyword_salary)
print(data_df_python_keyword)
# 城市地区
data_df_python_keyword_location_city = data_df_python_keyword['地点'].str.split('·', expand=True)[0]
print(data_df_python_keyword_location_city) # 北京
data_df_python_keyword_location_district = data_df_python_keyword['地点'].str.split('·', expand=True)[1]
print(data_df_python_keyword_location_district) # 海淀区
data_df_python_keyword_location_city_district = []
for city, district in zip(data_df_python_keyword_location_city, data_df_python_keyword_location_district):
city_district = city + district
data_df_python_keyword_location_city_district.append(city_district)
print(data_df_python_keyword_location_city_district) # 北京海淀区
# Dataframe新增一列 在第 列新增一列名为' ' 的一列 数据
data_df_python_keyword.insert(8, '城市地区', data_df_python_keyword_location_city_district)
print(data_df_python_keyword)
data_df_python_keyword.insert(9, '城市', data_df_python_keyword_location_city)
data_df_python_keyword.insert(10, '地区', data_df_python_keyword_location_district)
data_df_python_keyword.to_csv("data_df_python_keyword.csv", index=False, encoding='gb18030')
print('-------------------------------------------')
def draw_bar(row_lable, title):
figsize_x = 10
figsize_y = 6
global list1_education, list2_education, df1, df2
plt.figure(figsize=(figsize_x, figsize_y))
list1_education = []
list2_education = []
for df1, df2 in data_df_python_keyword.groupby(row_lable):
list1_education.append(df1)
list2_education.append(len(df2))
# print(list1_education)
# print(list2_education)
# 利用 * 解包方式 将 一个排序好的元组,通过元组生成器再转成list
# print(*sorted(zip(list2_education,list1_education)))
# print(sorted(zip(list2_education,list1_education)))
# 排序,两个列表对应原始排序,按第几个列表排序,注意先后位置
list2_education, list1_education = (list(t) for t in zip(*sorted(zip(list2_education, list1_education))))
plt.bar(list1_education, list2_education)
plt.title('{}'.format(title))
plt.savefig('./image/{}分析.jpg'.format(title))
# plt.show()
plt.close()
# 学历
draw_bar('学历', '学历')
draw_bar('工作经验', '工作经验')
draw_bar('区间最小薪资(K)', '14个热门城市的薪资分布情况(K)')
# -----------------------------------------
# 根据城市地区求均值
list_group_city1 = []
list_group_city2 = []
for df1, df2 in data_df_python_keyword.groupby(data_df_python_keyword['城市地区']):
# print(df1)
# print(df2)
list_group_city1.append(df1)
salary_list_district = [int(i) for i in (df2['区间最小薪资(K)'].values.tolist())]
district_salary_mean = round(np.mean(salary_list_district), 2) # 每个区县的平均薪资 round(a, 2)保留2位小数
list_group_city2.append(district_salary_mean)
list_group_city2, list_group_city1 = (list(t) for t in
zip(*sorted(zip(list_group_city2, list_group_city1), reverse=False)))
#
# print(list_group_city1)
# print(list_group_city2)
plt.figure(figsize=(10, 50))
plt.barh(list_group_city1, list_group_city2)
# 坐标轴上的文字说明
for ax, ay in zip(list_group_city1, list_group_city2):
# 设置文字说明 第一、二个参数:坐标轴上的值; 第三个参数:说明文字;ha:垂直对齐方式;va:水平对齐方式
plt.text(ay, ax, '%.2f' % ay, ha='center', va='bottom')
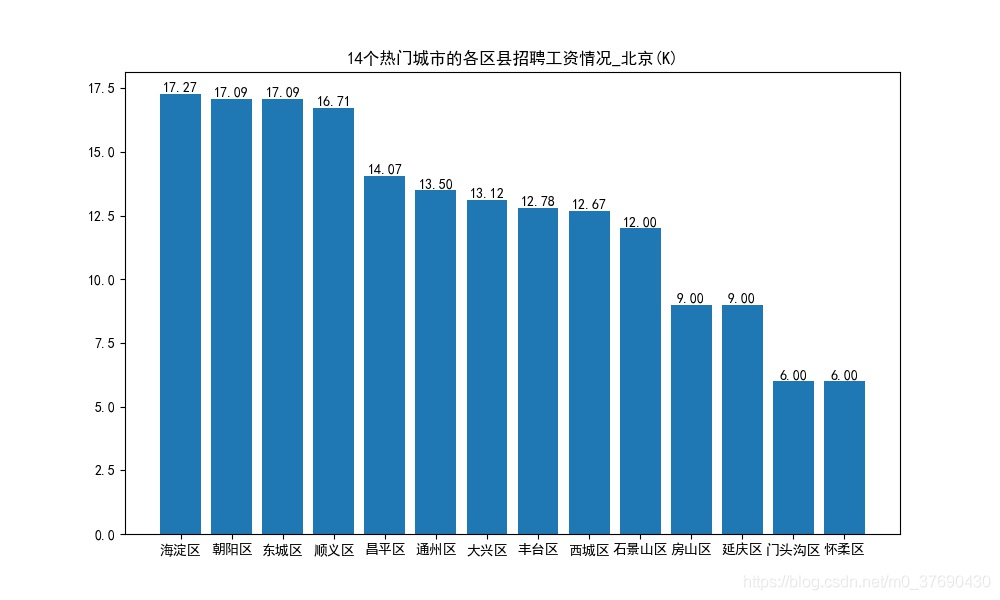
plt.title('14个热门城市的各区县招聘工资情况(K)')
plt.savefig('./image/14个热门城市的各区县招聘工资情况(K).jpg')
# plt.show()
plt.close()
# -----------------------------------------
# 根据城市分组排序,
list_group_city11 = []
list_group_city22 = []
list_group_city33 = []
list_group_city44 = []
for df_city1, df_city2 in data_df_python_keyword.groupby(data_df_python_keyword['城市']):
# print(df_city1)#市
# print(df_city2)
list_group_district2 = [] # 区县列表
district_mean_salary2 = [] # 工资均值列表
for df_district1, df_district2 in df_city2.groupby(data_df_python_keyword['地区']):
# print(df_district1)#区县
# print(df_district2)#工作
list_group_district2.append(df_district1) # 记录区县
salary_list_district2 = [int(i) for i in (df_district2['区间最小薪资(K)'].values.tolist())] # 工资列表
district_salary_mean2 = round(np.mean(salary_list_district2), 2) # 每个区县的平均薪资 round(a, 2)保留2位小数
district_mean_salary2.append(district_salary_mean2) # 记录区县的平均工作的列表
district_mean_salary2, list_group_district2 = (list(tt) for tt in zip(
*sorted(zip(district_mean_salary2, list_group_district2), reverse=True)))
plt.figure(figsize=(10, 6))
plt.bar(list_group_district2, district_mean_salary2)
# 坐标轴上的文字说明
for ax, ay in zip(list_group_district2, district_mean_salary2):
# 设置文字说明 第一、二个参数:坐标轴上的值; 第三个参数:说明文字;ha:垂直对齐方式;va:水平对齐方式
plt.text(ax, ay, '%.2f' % ay, ha='center', va='bottom')
plt.title('14个热门城市的各区县招聘工资情况_{}(K)'.format(df_city1))
plt.savefig('./image/city/14个热门城市的各区县招聘工资情况_{}(K).jpg'.format(df_city1))
# plt.show()
plt.close()
# ----------------------------------------------------
skill_all = data_df_python_keyword['技能']
print(skill_all)
skill_list = []
for i in skill_all:
# print(type(i))
print(i)
# print(i.split(", | ' | \[ | \] | \" | "))
result = re.split(r'[,\' \[, \] ]', i)
print(result)
# if type(i) == list:
skill_list = skill_list + result
print('++++++++++++++++++++++++++++++++')
# print(skill_list)
list_new = skill_list
# 词频统计
word_counts = collections.Counter(list_new) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(30) # 获取前10最高频的词
# print (word_counts_top10) # 输出检查
# print (word_counts_top10[0][0]) # 输出检查
# 生成柱状图
list_x = []
list_y = []
for i in word_counts_top10:
list_x.append(i[0])
list_y.append(i[1])
print('list_x', list_x[1:])
print('list_y', list_y[1:])
plt.figure(figsize=(30, 5))
plt.bar(list_x[1:], list_y[1:])
plt.savefig('./image/技能栈_词频_柱状图.png')
# plt.show()
plt.close()
list_new = " ".join(list_new) # 列表转字符串,以空格间隔
# print(list_new)
wc = wordcloud.WordCloud(
width=800,
height=600,
background_color="#ffffff", # 设置背景颜色
max_words=50, # 词的最大数(默认为200)
max_font_size=60, # 最大字体尺寸
min_font_size=10, # 最小字体尺寸(默认为4)
# colormap='bone', # string or matplotlib colormap, default="viridis"
colormap='hsv', # string or matplotlib colormap, default="viridis"
random_state=20, # 设置有多少种随机生成状态,即有多少种配色方案
# mask=plt.imread("mask2.gif"), # 读取遮罩图片!!
font_path='simhei.ttf'
)
my_wordcloud = wc.generate(list_new)
plt.imshow(my_wordcloud)
plt.axis("off")
# plt.show()
wc.to_file('./image/技能栈_词云.png') # 保存图片文件
plt.close()
四、学历分析

五、工作经验分析

六、14个热门城市的各区县招聘薪资情况

七、各城市各区县的薪资情况
北京
上海

其余12个城市不再展示,生成代码都一样
八、技能栈


到此这篇关于Python数据分析之Python和Selenium爬取BOSS直聘岗位的文章就介绍到这了,更多相关Python和Selenium爬取BOSS直聘内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-

python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
python selenium实现智联招聘数据爬取
一.主要目的 最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程. 二.前期准备 操作系统:windows10 浏览器:谷歌浏览器(Google Chrome) 浏览器驱动:chromedriver.exe (我的版本->89.0.4389.128 ) 程序中我使用的模块 import csv import os import re import json import time import requests from sele
-
基于python requests selenium爬取excel vba过程解析
目的:基于办公与互联网隔离,自带的office软件没有带本地帮助工具,因此在写vba程序时比较不方便(后来发现07有自带,心中吐血,瞎折腾些什么).所以想到通过爬虫在官方摘录下来作为参考. 目标网站:https://docs.microsoft.com/zh-cn/office/vba/api/overview/ 所使工具: python3.7,requests.selenium库 前端方面:使用了jquery.jstree(用于方便的制作无限层级菜单 设计思路: 1.分析目标页面,可分出两部分
-
Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖
-
python数据分析之员工个人信息可视化
一.实验目的 (1)熟练使用Counter类进行统计 (2)掌握pandas中的cut方法进行分类 (3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形 二.实验内容 采集到的数据集如下表格所示: 三.实验要求 1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示. 2.男生和女生各占公司总人数的比例,并用扇形图进行展示. 3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图进行展示. import pan
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
python基于selenium爬取斗鱼弹幕
针对弹幕的爬取我们如果只需要获取看到的网页里面的而数据,使用selenium就能实现,对于直播平台来说,往往有第三方平台api让你获取数据(可以获取发弹幕,发弹幕者的名字礼物等等,这需要客户端向弹幕服务器发送登录请求,心跳信息的发送等等)只获取弹幕信息储存到txt文件中,上代码,上图片 代码如下: import time from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 使用headless无界
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
Python selenium爬取微信公众号文章代码详解
参照资料:selenium webdriver添加cookie: https://www.jb51.net/article/193102.html 需求: 想阅读微信公众号历史文章,但是每次找回看得地方不方便. 思路: 1.使用selenium打开微信公众号历史文章,并滚动刷新到最底部,获取到所有历史文章urls. 2.对urls进行遍历访问,并进行下载到本地. 实现 1.打开微信客户端,点击某个微信公众号->进入公众号->打开历史文章链接(使用浏览器打开),并通过开发者工具获取到cookie
-
python学习之panda数据分析核心支持库
前言 Python是一门实现数据可视化很好的语言,他们里面的很多库可以很好的画出图形,形象明了. 今天我们就来说说:Pandas数据分析核心支持库 初识Pandas: Pandas 是 Python 语言的一个扩展程序库,用于数据分析. Pandas 是一个开放源码.BSD 许可的库,提供高性能.易于使用的数据结构和数据分析工具. Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=