python解决12306登录验证码的实现
在家无聊,线代和高数看不懂,整点事情干,就准备预定回学校的高铁票,于是就有了这个文章
准备工作
1.pip安装chromediver,当然也可以手动解压(网上的教程好像没有提到pip,手动安装到C盘pycharm里面的Scripts就行了)
chromedriver.storage.googleapis.com/index.html这是chromedriver文件官网,在chrome里面设置查看自己的版本,然后找对应的版本就完了
2.注册个超级鹰,http://www.chaojiying.com/contact.html,挺厉害的打码平台,微信公众号绑定一下账号给1000积分,足够干12306验证码了
开始实战讲解
1.选择chrome打开12306然后切换到账号登录
默认是扫码登录
F12然后点击账号登录
3.复制xPath,/html/body/div[2]/div[2]/ul/li[2]/a
代码实现
from selenium.webdriver import Chrome
web = Chrome()
web.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(3)
web.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a').click()
2.下载验证码(截屏也可以)然后发送给超级鹰
超级鹰官网有个官方文档,下载然后pychram打开,其实就很简单,然后把账号密码改成你自己的,
from chaojiying import Chaojiying_Client
验证码需要时间加载,所以要sleep(3)就够了,
3.拿到坐标然后模拟点击
好像这个官方叫什么偏移量,挺高大上的,说白了就是建立一个坐标系,给个x,y然后点击就完了,默认左上方是原点
for pre_location in location_list:
#切割出来x,y坐标
location = pre_location.split(',')
x = int(location[0])
y = int(location[1])
ActionChains(web).move_to_element_with_offset(img,x,y).click().perform()
4.登录以后有个滑动验证
现在我还没有找到方法控制滑动速度,匀速运动,但是12306并没有因为这个验证失败
ActionChains(web).drag_and_drop_by_offset(button,340,0).perform()
button是那个滑块的Xpath,我记得好像是长度330,340肯定是够用了,那个0就是竖y的方向上的滑动
12306靠webdriver判断是不是爬虫
刚开始12306图片和滑动验证通过以后一直说验证失败,百思不得其解,百度发现是因为这个
这是正常页面下的,也就是我改了以后的,加一个这个代码,欺骗一下
def trick_not_chromedriver():
option = Options()
option.add_argument('--disable-blink-features=AutomationControlled')
return option
这个要调用在前面,靠后一点就不行了
全部代码
from selenium.webdriver import Chrome
import requests,time
from hashlib import md5
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#获取验证码
def get_verify_img(web):
web.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a').click()
time.sleep(5)
verify_img = web.find_element_by_xpath('//*[@id="J-loginImg"]')
return verify_img
#识别验证码返回坐标
def discern_verify_img(verify_img):
chaojiying = Chaojiying_Client('超级鹰账号', '密码', '软件ID')
responce = chaojiying.PostPic(verify_img.screenshot_as_png, 9004)
pre_location = responce['pic_str']
location_list = pre_location.split("|")
# 把split写错了,卡了半天
# type_pre_location = type(pre_location)
return location_list
# return type_pre_location
#拿到坐标模拟点击
def click_and_enter(web,location_list,img):
for pre_location in location_list:
#切割出来x,y坐标
location = pre_location.split(',')
x = int(location[0])
y = int(location[1])
ActionChains(web).move_to_element_with_offset(img,x,y).click().perform()
def enter(web):
# input()
web.find_element_by_xpath('//*[@id="J-userName"]').send_keys('账号')
web.find_element_by_xpath('//*[@id="J-password"]').send_keys('密码')
web.find_element_by_xpath('//*[@id="J-login"]').click()
#滑动验证
def move_verify(web):
button = web.find_element_by_xpath('//*[@id="nc_1__scale_text"]/span')
ActionChains(web).drag_and_drop_by_offset(button,340,0).perform()
# 骗12306这不是chromedriver
def trick_not_chromedriver():
option = Options()
option.add_argument('--disable-blink-features=AutomationControlled')
return option
#现在有一个疫情防控的确认按钮,点一下这个
def yqfk(web):
web.get('https://kyfw.12306.cn/otn/leftTicket/init')
time.sleep(1)
web.find_element_by_xpath('//*[@id="qd_closeDefaultWarningWindowDialog_id"]').click()
#进入查询界面,思路正则表达式,不可信
def get_stick_text(web):
web.get('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2021-04-16&leftTicketDTO.from_station=TNV&leftTicketDTO.to_station=CZF&purpose_codes=0X00')
response = web.find_element_by_xpath('/html/body/pre').text
return (response)
#父子节点一个一个找,显示余票
if __name__ == '__main__':
web = Chrome(options=trick_not_chromedriver())
web.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(5)
# click_and_enter(discern_verify_img(get_verify_img()))
img = get_verify_img(web)
click_and_enter(web,discern_verify_img(img),img)
time.sleep(5)
enter(web)
time.sleep(5)
move_verify(web)
time.sleep(1)
yqfk(web)
time.sleep(2)
get_verify_img(web)
已经可以登录的,结果就是这个界面
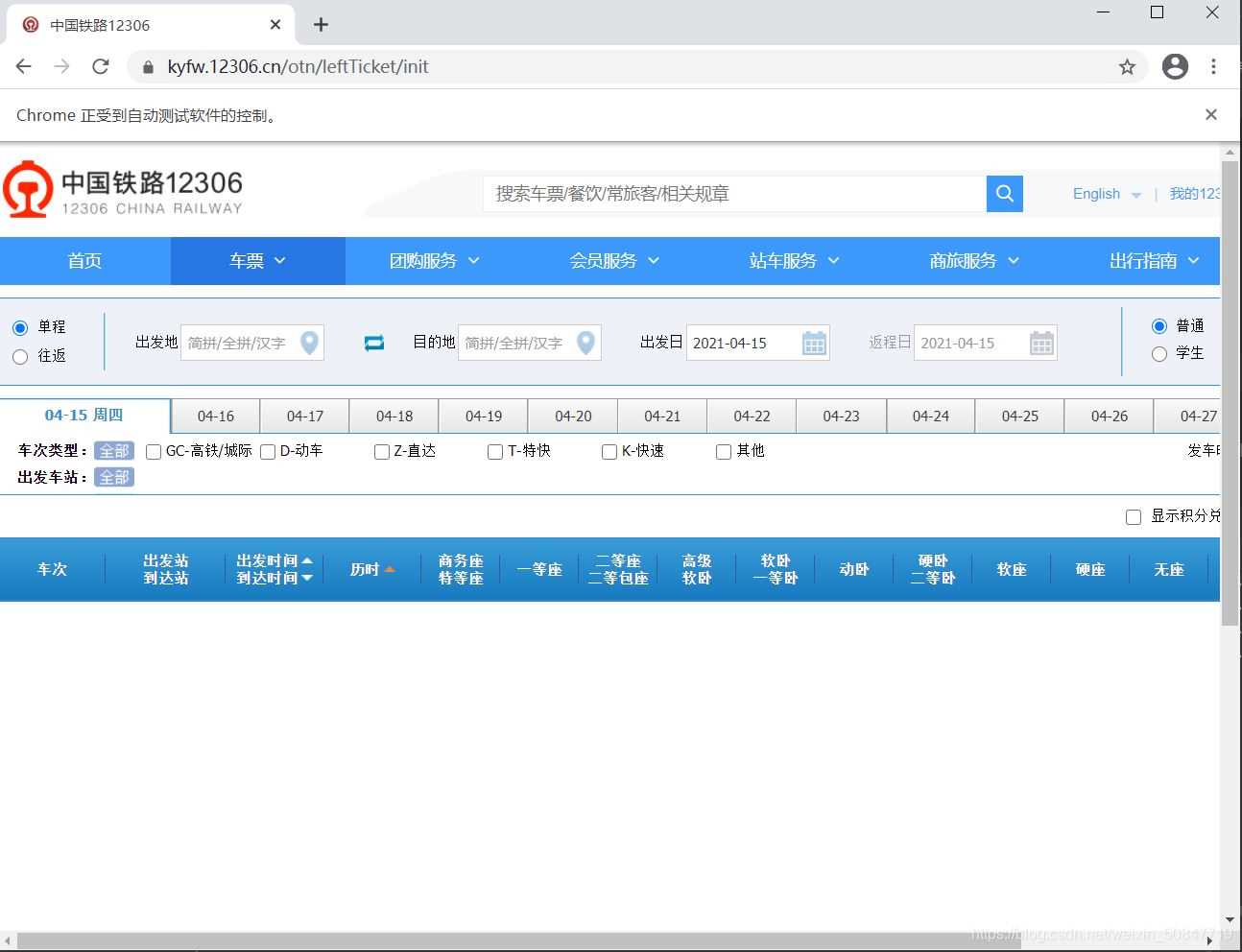
还有一个想法是余票检测,在搞了,应该快了
到此这篇关于python解决12306登录验证码的实现的文章就介绍到这了,更多相关python 12306登录验证码 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 模拟网站登录——滑块验证码的识别
普通滑动验证 以http://admin.emaotai.cn/login.aspx为例这类验证码只需要我们将滑块拖动指定位置,处理起来比较简单.拖动之前需要先将滚动条滚动到指定元素位置. import time from selenium import webdriver from selenium.webdriver import ActionChains # 新建selenium浏览器对象,后面是geckodriver.exe下载后本地路径 browser = webdriver.Fire
-
Python3+Appium安装及Appium模拟微信登录方法详解
一.Appium安装 我们知道selenium是桌面浏览器自动化操作工具(Web Browser Automation) appium是继承selenium自动化思想旨在使手机app操作也能自动化的工具(Mobile App Automation Made Awesome). appium可以通过Desktop App和npm两种方式安装.Desktop App类似于selenium IDE提供一个图形界面式操作工具:npm类似于selenium就只能使用命令行. 如果对appium还不太熟悉,
-
教你怎么用python批量登录带有验证码的网站
一.介绍 原理为使用selenium驱动chorme打开一个新的进程并打开数组中的网址,之后程序自动输入我们事先填入的账号密码,通过已实现的验证码识别模块填写验证码进行登录.登陆完成后自动切换页面,进行下一个页面的登录 二.准备 部署环境:win10 开发环境:python2.7 chrome版本89.0.4389.128 三.实践 3.1 下载驱动 设置查看chorme版本 下载对应版本的chromedriver 解压后,将chromedriver.exe分别放进chrome浏览器目录 和 P
-
python tkinter制作用户登录界面的简单实现
本文只是几年前学习的tkinter的时候写的测试程序,十分之简陋,只是学习用,没什么其他用处. 学习一下莫烦Python的tkinter教程,根据教程制作了用户登录注册页.基本功能为检查登录.注册. 运行如下: 代码如下: # -*- coding: utf-8 -*- """ Created on Sun Aug 5 10:34:10 2018 @author: Administrator """ import tkinter a
-
用python登录带弱图片验证码的网站
上一篇介绍了使用python模拟登陆网站,但是登陆的网站都是直接输入账号及密码进行登陆,现在很多网站为了加强用户安全性和提高反爬虫机制都会有包括字符.图片.手机验证等等各式各样的验证码.图片验证码就是其中一种,而且识别难度越来越大,人为都比较难识别.本篇我们简单介绍一下使用python登陆带弱图片验证码的网站. 图片验证码 一般都通过加干扰线.粘连或扭曲等方式来增加强度. 登陆 我们选择一个政务网站(图片验证码的强度较低). 点击个人用户登录 访问网站首页以后我们发现需要先点击个人用户登陆,且元
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python中requests模拟登录的三种方式(携带cookie/session进行请求网站)
一,cookie和session的区别 cookie在客户的浏览器上,session存在服务器上 cookie是不安全的,且有失效时间 session是在cookie的基础上,服务端设置session时会向浏览器发送设置一个设置cookie的请求,这个cookie包括session的id当访问服务端时带上这个session_id就可以获取到用户保存在服务端对应的session 二,爬虫处理cookie和session 带上cookie和session的好处: 能够请求到登录后的界面 带上cook
-
python爬取企查查企业信息之selenium自动模拟登录企查查
最近接了个小项目需要批量搜索企查查上的相关企业并把指定信息保存到Excel文件中,由于企查查需要登录后才能查看所有搜索到的信息所以第一步需要模拟登录企查查. python模拟登录企查查最重要的是自动拖拽验证插件 先介绍下项目中使用到的工具与库 Python的selenium库: Web应用程序测试的工具,Selenium可以模拟用户在浏览器中的操作,就像真实用户使用一样. 官方技术文档:https://www.selenium.dev/selenium/docs/api/py/index.htm
-
python解决12306登录验证码的实现
在家无聊,线代和高数看不懂,整点事情干,就准备预定回学校的高铁票,于是就有了这个文章 准备工作 1.pip安装chromediver,当然也可以手动解压(网上的教程好像没有提到pip,手动安装到C盘pycharm里面的Scripts就行了) chromedriver.storage.googleapis.com/index.html这是chromedriver文件官网,在chrome里面设置查看自己的版本,然后找对应的版本就完了 2.注册个超级鹰,http://www.chaojiying.co
-
Python 实现12306登录功能实例代码
下面一段代码给大家带来了python实现12306登录功能,具体代码如下所示: #!/usr/bin/env python import requests import urllib.parse import random import time req = requests.session() import sys import re import urllib3 import getpass # 密文输入 urllib3.disable_warnings() # 登陆------------
-
python实现12306登录并保存cookie的方法示例
经过倒腾12306的登录,还是实现了,请求头很重要...各位感兴趣的可以继续写下去..... import sys import time import requests from PIL import Image import json import os import Headers import SessionUtil import UrlUtils class Ticket(object): def __init__(self): self.answer = { "1": &q
-
Python 识别12306图片验证码物品的实现示例
1.PIL介绍以及图片分割 Python 3 安装: pip3 install Pillow 1.1 image 模块 Image模块是在Python PIL图像处理中常见的模块,主要是用于对这个图像的基本处理,它配合open.save.convert.show-等功能使用. from PIL import Image #打开文件代表打开pycharm中的文件 im = Image.open('1.jpg') #展示图片 im.show() 1.Crop类 拷贝这个图像.如果用户想粘贴一些数据
-
python+selenium行为链登录12306(滑动验证码滑块)
使用python网络爬虫登录12306,网站界面如下.因为网站的反爬是不断升级的,以下代码虽然当前可用,但早晚必将会不再能满足登录需求.但是知识的价值,是不容置疑的. from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time from selenium.webdriver import ChromeOptions # 去除浏览器识别 opt
-
使用Python神器对付12306变态验证码
临近春节,我们小编带领大家用Python抢火车票! 首先我们需要splinter 安装: pip install splinter -i http://pypi.douban.com/simple –trusted-host pypi.douban.com 然后还需要一个浏览器的驱动,当然用chrome啦 下载地址: http://chromedriver.storage.googleapis.com/index.html?path=2.20/ 根据下载的自己的电脑系统选择下载包,我的windo
-
Python实现破解12306图片验证码的方法分析
本文实例讲述了Python实现破解12306图片验证码的方法.分享给大家供大家参考,具体如下: 不知从何时起,12306的登录验证码竟然变成了按字找图,可以说是又提高了一个等次,竟然把图像识别都用上了.不过有些图片,不得不说有些变态,图片的清晰图就更别说了,明显是从网络上的图库中搬过来的. 谁知没多久,网络就惊现破解12306图片验证码的Python代码了,作为一个爱玩爱刺激的网虫,当然要分享一份过来. 代码大致流程: 1.将验证码图片下载下来,然后切图: 2.利用百度识图进行图片分析: 3.再
-
基于Python实现原生的登录验证码详情
目录 1.概述 2.验证码实现的演进过程 2.1 路由及页面 2.2 视图函数中验证码的推导 2.2.1 图片发送到前端 2.2.2 引入动态图片 2.2.3 内存管理模块图片 2.2.4 完整图片验证码 2.3 登录验证中使用验证码 2.4 前端页面点击自动刷新 3.效果展示 4.小结 1.概述 在前面的文章中,我有分享了vue+drf+第三方滑动验证码接入的实现(文中也留了分享图片验证码功能的实现),即本文将要分享的是基于 python 实现原生的登录验证码 通常的验证码,人眼看上去更像是一
-
python爬虫模拟登录之图片验证码实现详解
我们在用爬虫对门户网站进行模拟登录是总会有输入图片验证码的,例如这种 那我们怎么解决这个问题实现全自动的模拟登录呢?只要思想不滑坡,办法总比困难多.我这里使用的是百度智能云里面的文字识别功能,每天好像可以免费使用个几百次,识别效果也还行,对一般人而言是够用了. 接下来说说,怎么使用. 首先,打开百度智能云(https://cloud.baidu.com/)进行登入,再进入人工智能->文字识别里创建应用. 在使用名称和底下应用描述随便写写,然后点立即创建. 创建完成,就可以拿到 AppID .AP
-
Selenium+Python 自动化操控登录界面实例(有简单验证码图片校验)
从最简单的Web浏览器的登录界面开始,登录界面如下: 进行Web页面自动化测试,对页面上的元素进行定位和操作是核心.而操作又是以定位为前提的,因此,对页面元素的定位是进行自动化测试的基础. 页面上的元素就像人一样,有各种属性,比如元素名字,元素id,元素属性(class属性,name属性)等等.webdriver就是利用元素的这些属性来进行定位的. 可以用于定位的常用的元素属性: id name class name tag name link text partial link text xp