对Keras自带Loss Function的深入研究
本文研究Keras自带的几个常用的Loss Function。
1. categorical_crossentropy VS. sparse_categorical_crossentropy
注意到二者的主要差别在于输入是否为integer tensor。在文档中,我们还可以找到关于二者如何选择的描述:

解释一下这里的Integer target 与 Categorical target,实际上Integer target经过独热编码就变成了Categorical target,举例说明:
(类别数5) Integer target: [1,2,4] Categorical target: [[0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 0. 1.]]
在Keras中提供了to_categorical方法来实现二者的转化:
from keras.utils import to_categorical categorical_labels = to_categorical(int_labels, num_classes=None)
注意categorical_crossentropy和sparse_categorical_crossentropy的输入参数output,都是softmax输出的tensor。我们都知道softmax的输出服从多项分布,
因此categorical_crossentropy和sparse_categorical_crossentropy应当应用于多分类问题。
我们再看看这两个的源码,来验证一下:
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/python/keras/backend.py
--------------------------------------------------------------------------------------------------------------------
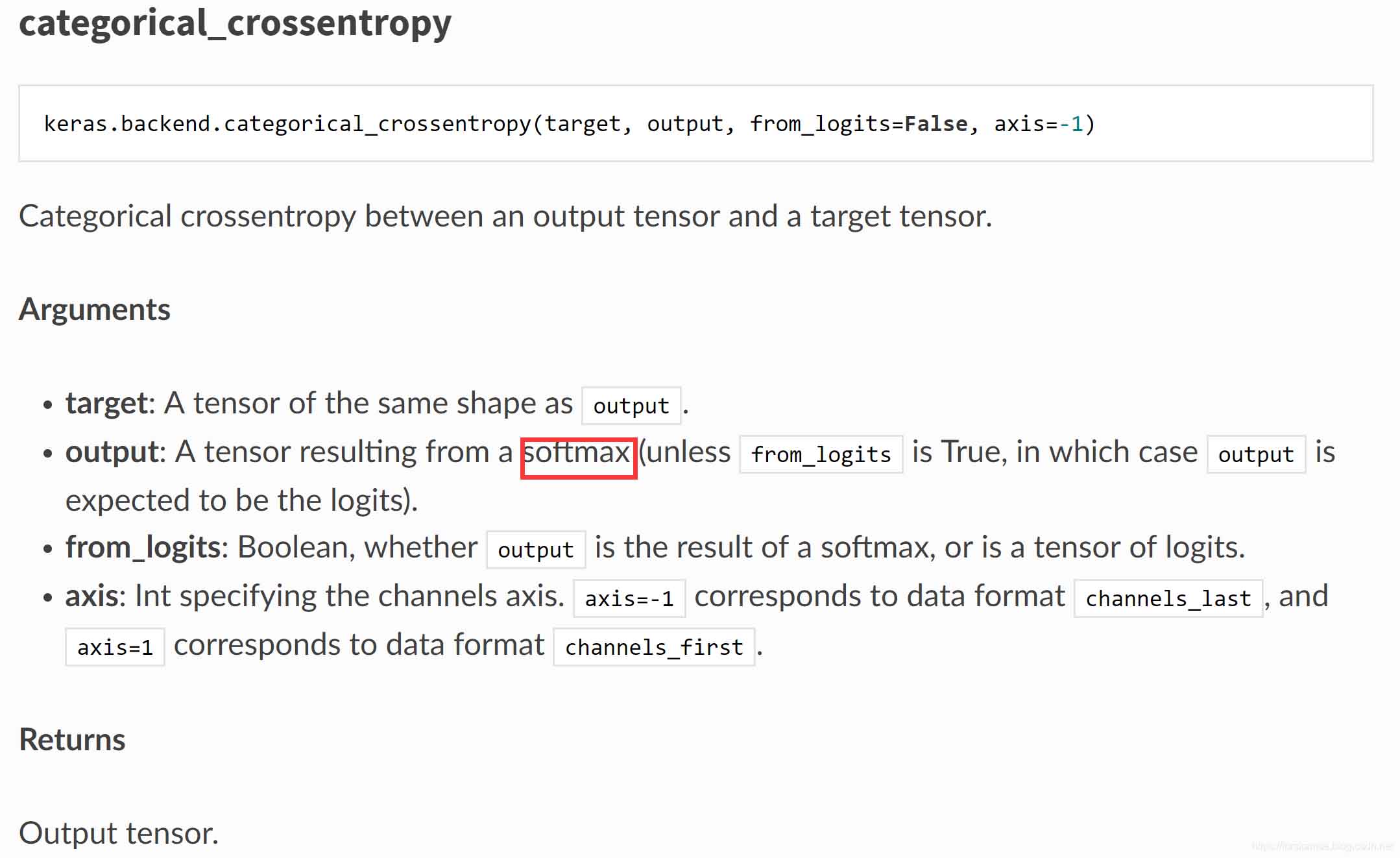
def categorical_crossentropy(target, output, from_logits=False, axis=-1):
"""Categorical crossentropy between an output tensor and a target tensor.
Arguments:
target: A tensor of the same shape as `output`.
output: A tensor resulting from a softmax
(unless `from_logits` is True, in which
case `output` is expected to be the logits).
from_logits: Boolean, whether `output` is the
result of a softmax, or is a tensor of logits.
axis: Int specifying the channels axis. `axis=-1` corresponds to data
format `channels_last', and `axis=1` corresponds to data format
`channels_first`.
Returns:
Output tensor.
Raises:
ValueError: if `axis` is neither -1 nor one of the axes of `output`.
"""
rank = len(output.shape)
axis = axis % rank
# Note: nn.softmax_cross_entropy_with_logits_v2
# expects logits, Keras expects probabilities.
if not from_logits:
# scale preds so that the class probas of each sample sum to 1
output = output / math_ops.reduce_sum(output, axis, True)
# manual computation of crossentropy
epsilon_ = _to_tensor(epsilon(), output.dtype.base_dtype)
output = clip_ops.clip_by_value(output, epsilon_, 1. - epsilon_)
return -math_ops.reduce_sum(target * math_ops.log(output), axis)
else:
return nn.softmax_cross_entropy_with_logits_v2(labels=target, logits=output)
--------------------------------------------------------------------------------------------------------------------
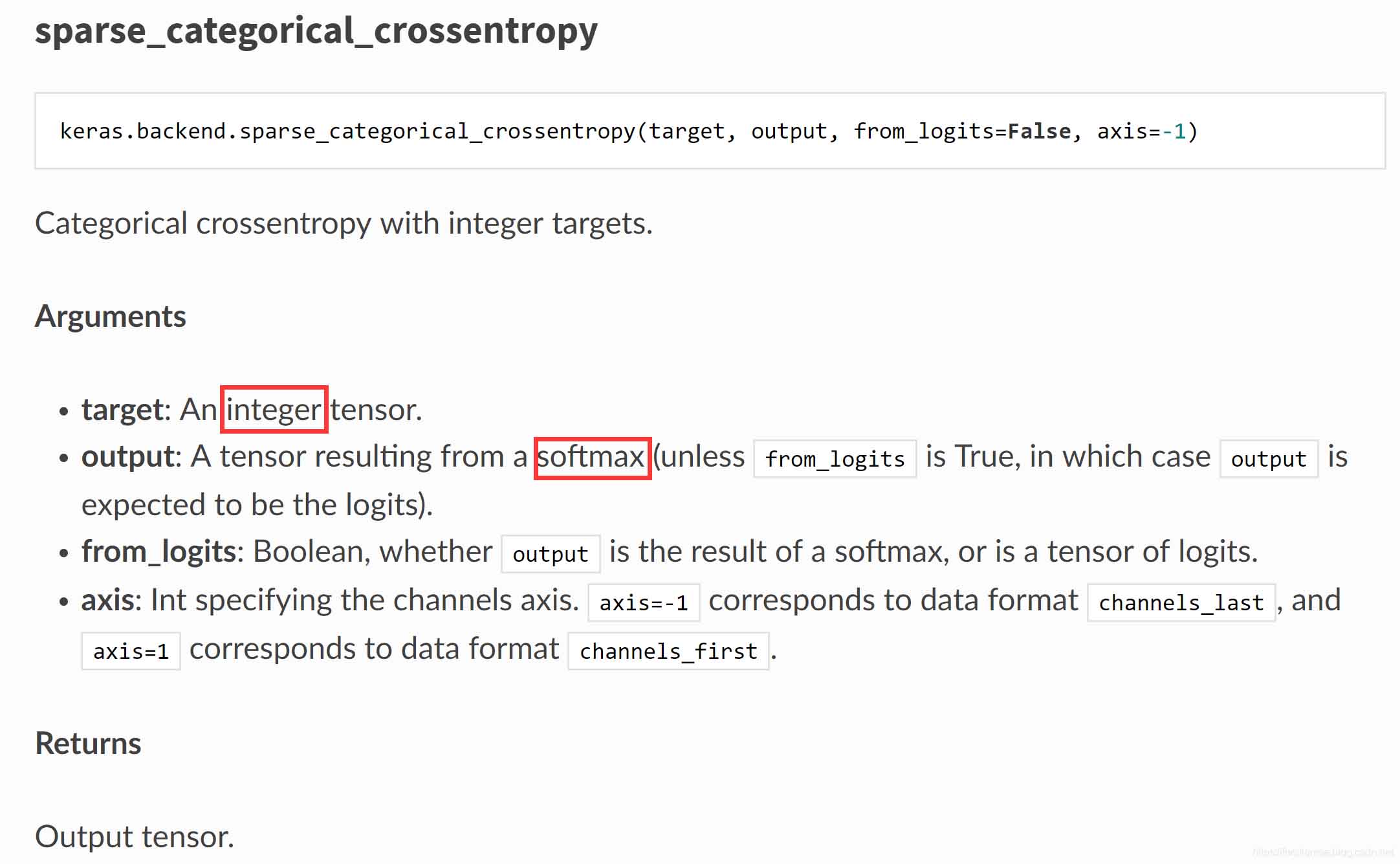
def sparse_categorical_crossentropy(target, output, from_logits=False, axis=-1):
"""Categorical crossentropy with integer targets.
Arguments:
target: An integer tensor.
output: A tensor resulting from a softmax
(unless `from_logits` is True, in which
case `output` is expected to be the logits).
from_logits: Boolean, whether `output` is the
result of a softmax, or is a tensor of logits.
axis: Int specifying the channels axis. `axis=-1` corresponds to data
format `channels_last', and `axis=1` corresponds to data format
`channels_first`.
Returns:
Output tensor.
Raises:
ValueError: if `axis` is neither -1 nor one of the axes of `output`.
"""
rank = len(output.shape)
axis = axis % rank
if axis != rank - 1:
permutation = list(range(axis)) + list(range(axis + 1, rank)) + [axis]
output = array_ops.transpose(output, perm=permutation)
# Note: nn.sparse_softmax_cross_entropy_with_logits
# expects logits, Keras expects probabilities.
if not from_logits:
epsilon_ = _to_tensor(epsilon(), output.dtype.base_dtype)
output = clip_ops.clip_by_value(output, epsilon_, 1 - epsilon_)
output = math_ops.log(output)
output_shape = output.shape
targets = cast(flatten(target), 'int64')
logits = array_ops.reshape(output, [-1, int(output_shape[-1])])
res = nn.sparse_softmax_cross_entropy_with_logits(
labels=targets, logits=logits)
if len(output_shape) >= 3:
# If our output includes timesteps or spatial dimensions we need to reshape
return array_ops.reshape(res, array_ops.shape(output)[:-1])
else:
return res
categorical_crossentropy计算交叉熵时使用的是nn.softmax_cross_entropy_with_logits_v2( labels=targets, logits=logits),而sparse_categorical_crossentropy使用的是nn.sparse_softmax_cross_entropy_with_logits( labels=targets, logits=logits),二者本质并无区别,只是对输入参数logits的要求不同,v2要求的是logits与labels格式相同(即元素也是独热的),而sparse则要求logits的元素是个数值,与上面Integer format和Categorical format的对比含义类似。
综上所述,categorical_crossentropy和sparse_categorical_crossentropy只不过是输入参数target类型上的区别,其loss的计算在本质上没有区别,就是交叉熵;二者是针对多分类(Multi-class)任务的。
2. Binary_crossentropy
二元交叉熵,从名字中我们可以看出,这个loss function可能是适用于二分类的。文档中并没有详细说明,那么直接看看源码吧:
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/python/keras/backend.py
--------------------------------------------------------------------------------------------------------------------
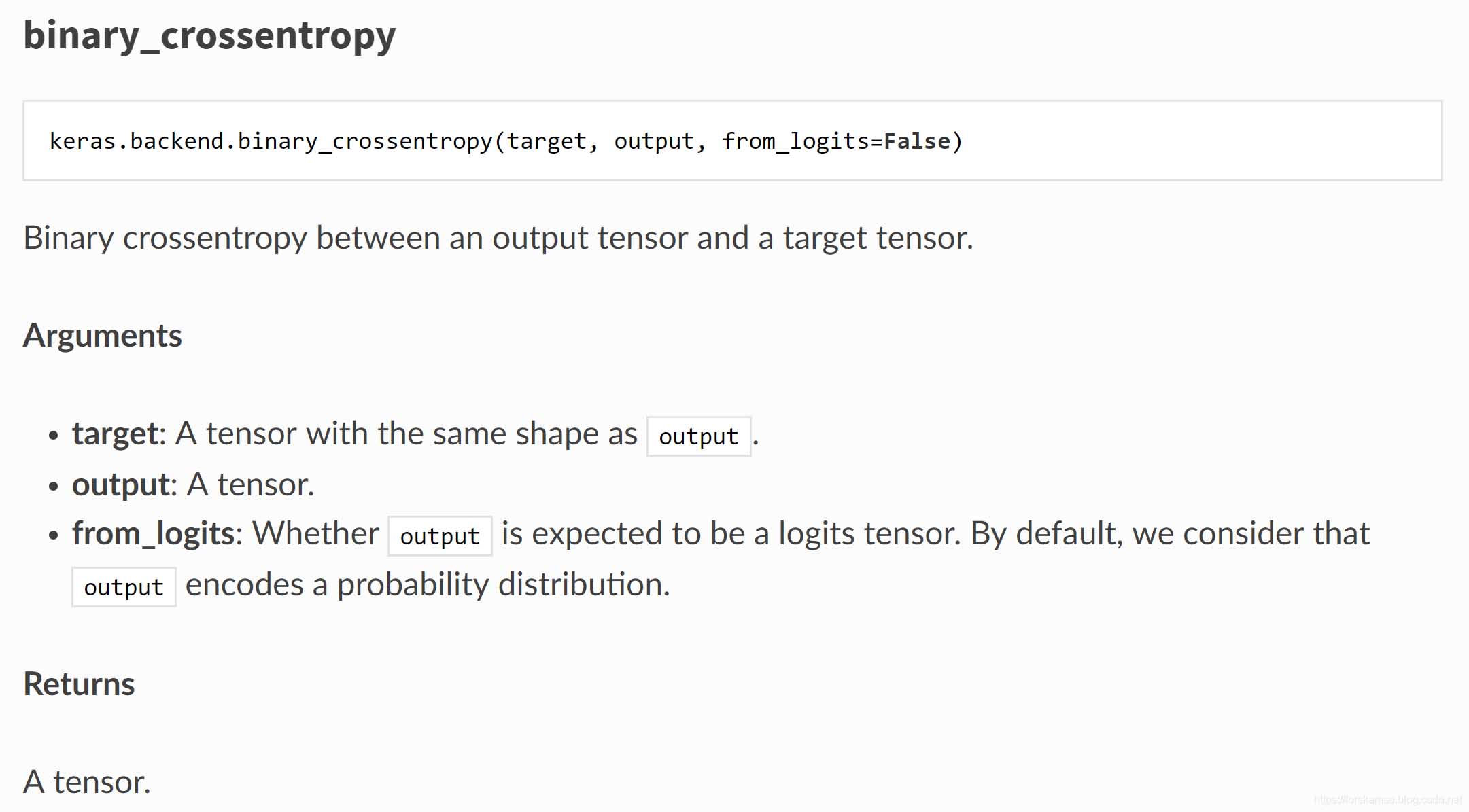
def binary_crossentropy(target, output, from_logits=False):
"""Binary crossentropy between an output tensor and a target tensor.
Arguments:
target: A tensor with the same shape as `output`.
output: A tensor.
from_logits: Whether `output` is expected to be a logits tensor.
By default, we consider that `output`
encodes a probability distribution.
Returns:
A tensor.
"""
# Note: nn.sigmoid_cross_entropy_with_logits
# expects logits, Keras expects probabilities.
if not from_logits:
# transform back to logits
epsilon_ = _to_tensor(epsilon(), output.dtype.base_dtype)
output = clip_ops.clip_by_value(output, epsilon_, 1 - epsilon_)
output = math_ops.log(output / (1 - output))
return nn.sigmoid_cross_entropy_with_logits(labels=target, logits=output)
可以看到源码中计算使用了nn.sigmoid_cross_entropy_with_logits,熟悉tensorflow的应该比较熟悉这个损失函数了,它可以用于简单的二分类,也可以用于多标签任务,而且应用广泛,在样本合理的情况下(如不存在类别不均衡等问题)的情况下,通常可以直接使用。
补充:keras自定义loss function的简单方法
首先看一下Keras中我们常用到的目标函数(如mse,mae等)是如何定义的
from keras import backend as K
def mean_squared_error(y_true, y_pred):
return K.mean(K.square(y_pred - y_true), axis=-1)
def mean_absolute_error(y_true, y_pred):
return K.mean(K.abs(y_pred - y_true), axis=-1)
def mean_absolute_percentage_error(y_true, y_pred):
diff = K.abs((y_true - y_pred) / K.clip(K.abs(y_true), K.epsilon(), np.inf))
return 100. * K.mean(diff, axis=-1)
def categorical_crossentropy(y_true, y_pred):
'''Expects a binary class matrix instead of a vector of scalar classes.
'''
return K.categorical_crossentropy(y_pred, y_true)
def sparse_categorical_crossentropy(y_true, y_pred):
'''expects an array of integer classes.
Note: labels shape must have the same number of dimensions as output shape.
If you get a shape error, add a length-1 dimension to labels.
'''
return K.sparse_categorical_crossentropy(y_pred, y_true)
def binary_crossentropy(y_true, y_pred):
return K.mean(K.binary_crossentropy(y_pred, y_true), axis=-1)
def kullback_leibler_divergence(y_true, y_pred):
y_true = K.clip(y_true, K.epsilon(), 1)
y_pred = K.clip(y_pred, K.epsilon(), 1)
return K.sum(y_true * K.log(y_true / y_pred), axis=-1)
def poisson(y_true, y_pred):
return K.mean(y_pred - y_true * K.log(y_pred + K.epsilon()), axis=-1)
def cosine_proximity(y_true, y_pred):
y_true = K.l2_normalize(y_true, axis=-1)
y_pred = K.l2_normalize(y_pred, axis=-1)
return -K.mean(y_true * y_pred, axis=-1)
所以仿照以上的方法,可以自己定义特定任务的目标函数。比如:定义预测值与真实值的差
from keras import backend as K
def new_loss(y_true,y_pred):
return K.mean((y_pred-y_true),axis = -1)
然后,应用你自己定义的目标函数进行编译
from keras import backend as K
def my_loss(y_true,y_pred):
return K.mean((y_pred-y_true),axis = -1)
model.compile(optimizer=optimizers.RMSprop(lr),loss=my_loss,
metrics=['accuracy'])
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

关于keras多任务多loss回传的思考
如果有一个多任务多loss的网络,那么在训练时,loss是如何工作的呢? 比如下面: model = Model(inputs = input, outputs = [y1, y2]) l1 = 0.5 l2 = 0.3 model.compile(loss = [loss1, loss2], loss_weights=[l1, l2], ...) 其实我们最终得到的loss为 final_loss = l1 * loss1 + l2 * loss2 我们最终的优化效果是最小化final_los
-
使用keras框架cnn+ctc_loss识别不定长字符图片操作
我就废话不多说了,大家还是直接看代码吧~ # -*- coding: utf-8 -*- #keras==2.0.5 #tensorflow==1.1.0 import os,sys,string import sys import logging import multiprocessing import time import json import cv2 import numpy as np from sklearn.model_selection import train_test_s
-
Keras loss函数剖析
我就废话不多说了,大家还是直接看代码吧~ ''' Created on 2018-4-16 ''' def compile( self, optimizer, #优化器 loss, #损失函数,可以为已经定义好的loss函数名称,也可以为自己写的loss函数 metrics=None, # sample_weight_mode=None, #如果你需要按时间步为样本赋权(2D权矩阵),将该值设为"temporal".默认为"None",代表按样本赋权(1D权),和f
-
解决keras GAN训练是loss不发生变化,accuracy一直为0.5的问题
1.Binary Cross Entropy 常用于二分类问题,当然也可以用于多分类问题,通常需要在网络的最后一层添加sigmoid进行配合使用,其期望输出值(target)需要进行one hot编码,另外BCELoss还可以用于多分类问题Multi-label classification. 定义: For brevity, let x = output, z = target. The binary cross entropy loss is loss(x, z) = - sum_i (x[
-
keras 自定义loss层+接受输入实例
loss函数如何接受输入值 keras封装的比较厉害,官网给的例子写的云里雾里, 在stackoverflow找到了答案 You can wrap the loss function as a inner function and pass your input tensor to it (as commonly done when passing additional arguments to the loss function). def custom_loss_wrapper(input_
-
keras中epoch,batch,loss,val_loss用法说明
1.epoch Keras官方文档中给出的解释是:"简单说,epochs指的就是训练过程接中数据将被"轮"多少次" (1)释义: 训练过程中当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个epoch,网络会在每个epoch结束时报告关于模型学习进度的调试信息. (2)为什么要训练多个epoch,即数据要被"轮"多次 在神经网络中传递完整的数据集一次是不够的,对于有限的数据集(是在批梯度下降情况下),使用一个迭代过程,更新权重一
-
对Keras自带Loss Function的深入研究
本文研究Keras自带的几个常用的Loss Function. 1. categorical_crossentropy VS. sparse_categorical_crossentropy 注意到二者的主要差别在于输入是否为integer tensor.在文档中,我们还可以找到关于二者如何选择的描述: 解释一下这里的Integer target 与 Categorical target,实际上Integer target经过独热编码就变成了Categorical target,举例说明: (类
-
keras中的loss、optimizer、metrics用法
用keras搭好模型架构之后的下一步,就是执行编译操作.在编译时,经常需要指定三个参数 loss optimizer metrics 这三个参数有两类选择: 使用字符串 使用标识符,如keras.losses,keras.optimizers,metrics包下面的函数 例如: sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', opt
-
Pytorch 的损失函数Loss function使用详解
1.损失函数 损失函数,又叫目标函数,是编译一个神经网络模型必须的两个要素之一.另一个必不可少的要素是优化器. 损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等. 损失Loss必须是标量,因为向量无法比较大小(向量本身需要通过范数等标量来比较). 损失函数一般分为4种,平方损失函数,对数损失函数,HingeLoss 0-1 损失函数,绝对值损失函数. 我们先定义两个二维数组,然后用不同的损失函数计算其损失值. import
-
解决Keras自带数据集与预训练model下载太慢问题
keras的数据集源码下载地址太慢.尝试过修改源码中的下载地址,直接报错. 从源码或者网络资源下好数据集,下载好以后放到目录 ~/.keras/datasets/ 下面. 其中:cifar10需要改文件名为cifar-10-batches-py.tar.gz ,cifar100改为 cifar-100-python.tar.gz , mnist改为 mnist.npz 预训练models放到 ~/.keras/models/ 路径下面即可. 补充知识:Keras下载的数据集以及预训练模型
-
keras 多任务多loss实例
记录一下: # Three loss functions category_predict1 = Dense(100, activation='softmax', name='ctg_out_1')( Dropout(0.5)(feature1) ) category_predict2 = Dense(100, activation='softmax', name='ctg_out_2')( Dropout(0.5)(feature2) ) dis = Lambda(eucl_dist, nam
-
keras 自定义loss损失函数,sample在loss上的加权和metric详解
首先辨析一下概念: 1. loss是整体网络进行优化的目标, 是需要参与到优化运算,更新权值W的过程的 2. metric只是作为评价网络表现的一种"指标", 比如accuracy,是为了直观地了解算法的效果,充当view的作用,并不参与到优化过程 在keras中实现自定义loss, 可以有两种方式,一种自定义 loss function, 例如: # 方式一 def vae_loss(x, x_decoded_mean): xent_loss = objectives.binary_
-
浅谈keras中loss与val_loss的关系
loss函数如何接受输入值 keras封装的比较厉害,官网给的例子写的云里雾里, 在stackoverflow找到了答案 You can wrap the loss function as a inner function and pass your input tensor to it (as commonly done when passing additional arguments to the loss function). def custom_loss_wrapper(input_
-
keras 解决加载lstm+crf模型出错的问题
错误展示 new_model = load_model("model.h5") 报错: 1.keras load_model valueError: Unknown Layer :CRF 2.keras load_model valueError: Unknown loss function:crf_loss 错误修改 1.load_model修改源码:custom_objects = None 改为 def load_model(filepath, custom_objects, c