Apache Pulsar结合Hudi构建Lakehouse方案分析
目录
- 1. 动机
- 2. 分析
- 3. 当前方案
- 4. 新的Lakehouse存储方案
- 4.1 新的存储布局
- 4.2 支持高效Upserts
- 4.3 将Hudi表当做Pulsar Topic
- 4.4 可扩展的元数据管理
- 5. 引用
1. 动机
Lakehouse最早由Databricks公司提出,其可作为低成本、直接访问云存储并提供传统DBMS管系统性能和ACID事务、版本、审计、索引、缓存、查询优化的数据管理系统,Lakehouse结合数据湖和数据仓库的优点:包括数据湖的低成本存储和开放数据格式访问,数据仓库强大的管理和优化能力。Delta Lake,Apache Hudi和Apache Iceberg是三种构建Lakehouse的技术。
与此同时,Pulsar提供了一系列特性:包括分层存储、流式卸载、列式卸载等,让其成为一个可以统一批和事件流的存储层。特别是分层存储的特性,然Pulsar成为一个轻量级数据湖,但是Pulsar还是缺乏一些性能优化,比如索引,数据版本(在传统DBMS管理系统中非常常见),引入列式卸载程序的目的是为了缩小性能差距,但是还不够。
本提议尝试将Apache Pulsar作为Lakehouse,该提案仅提供顶层设计,详细设计和实现在后面的子提议中解决;
2. 分析
本部分将分析构建Lakehouse需要的关键特性,然后分析Pulsar是否满足要求以及识别还有哪些差距。
Lakehouse有如下关键特性:
- 事务支持:企业级Lakehouse中很多数据pipeliine会并发读写数据,支持ACID事务可以保证并发读写的一致性,特别是使用SQL;Delta Lake,Iceberg,Hudi三个数据湖框架都基于低成本的对象存储实现了事务层,都支持事务。Pulsar在2.7.0版本后引入了事务支持,并且支持跨topic的事务;
- Schema约束和治理:Lakehouse需要支持Schema的约束和演进,支持数仓型Schema范式,如星型/雪花型Schema,另外系统应该能够推理数据完整性,并且应该具有健壮的治理和审核机制,上述三个系统都有该能力。Pulsar有内置的Schema注册服务,它满足Schema约束和治理的基本要求,但是可能仍有一些地方需要改进。
- BI支持:Lakehouses可以直接在源数据上使用BI工具,这样可以减少陈旧性,提高新鲜度,减少等待时间,并降低必须同时在数据湖和仓库中操作两个数据副本的成本。三个数据湖框架与Apache Spark的集成非常好,同时可以允许Redshift,Presto/Athena查询源数据,Hudi社区也已经完成了对多引擎如Flink的支持。Pulsar暴露了分层存储中的段以供直接访问,这样可以与流行的数据处理引擎紧密集成。 但是Pulsar中的分层存储本身在服务BI工作负载方面仍然存在性能差距,我们将在该提案中解决这些差距。
- 存储与计算分离:这意味着存储和计算使用单独的集群,因此这些系统可以单独水平无限扩容。三个框均支持存储与计算分离。Pulsar使用了存储与计算分离的多层体系结构部署。
- 开放性:使用开放和标准化的数据格式,如Parquet,并且它们提供了API,因此各种工具和引擎(包括机器学习和Python / R库)可以"直接"有效地访问数据,三个框架支持Parquet格式,Iceberg还支持ORC格式,对于ORC格式Hudi社区正在支持中。Pulsar还不支持任何开放格式,列存卸载支持Parquet格式。
- 支持从非结构化数据到结构化数据的多种数据类型:Lakehouse可用于存储,优化,分析和访问许多新数据应用程序所需的数据类型,包括图像,视频,音频,半结构化数据和文本。尚不清楚Delta,Iceberg,Hudi如何支持这一点。Pulsar支持各种类型数据。
- 支持各种工作负载:包括数据科学,机器学习以及SQL和分析。 可能需要多种工具来支持所有这些工作负载,但它们都依赖于同一数据存储库。三个框架与Spark紧密结合,Spark提供了广泛的工具选择。Pulsar也与Spark有着紧密结合。
- 端到端流:实时报告是许多企业的常态,对流的支持消除了对专门用于服务实时数据应用程序的单独系统的需求,Delta Lake和Hudi通过变更日志提供了流功能。 但这不是真正的“流”。Pulsar是一个真正的流系统。
可以看到Pulsar满足构建Lakehouse的所有条件。然而现在的分层存储有很大的性能差距,例如:
- Pulsar并不以开放和标准的格式存储数据,如Parquet;
- Pulsar不会为卸载的数据部署任何索引机制;
- Plusar不支持高效的Upserts;
这里旨在解决Pulsar存储层的性能问题,使Pulsar能作为Lakehouse。
3. 当前方案
图1展示了当前Pulsar流的存储布局。
- Pulsar在ZooKeeper中存储了段(segment)元数据;
- 最新的段存储在Apache BookKeeper中(更快地存储层)
- 旧的段从Apache BookKeeper卸载到分层存储(便宜的存储层)。 卸载的段的元数据仍保留在Zookeeper中,引用的是分层存储中卸载的对象。

当前的方案有一些缺点:
- 它不使用任何开放式存储格式来存储卸载的数据。 这意味着很难与更广泛的生态系统整合。
- 它将所有元数据信息保留在ZooKeeper中,这可能会限制可伸缩性。
4. 新的Lakehouse存储方案
新方案建议在分层存储中使用Lakehouse存储卸载的数据。该提案建议使用Apache Hudi作为Lakehouse存储,原因如下:
- 云提供商在Apache Hudi上提供了很好的支持。
- Apache Hudi已经作为顶级项目毕业。
- Apache Hudi同时支持Spark和Flink多引擎。同时在中国有一个相当活跃的社区。
4.1 新的存储布局
图2展示了Pulsar topic新的布局。
- 最新片段(未卸载片段)的元数据存储在ZooKeeper中。
- 最新片段(未卸载片段)的数据存储在BookKeeper中。
- 卸载段的元数据和数据直接存储在分层存储中。 因为它是仅追加流。 我们不必使用像Apache Hudi这样的Lakehouse存储库。 但是如果我们也将元数据存储在分层存储中,则使用Lakehouse存储库来确保ACID更有意义。

4.2 支持高效Upserts
Pulsar不直接支持upsert。它通过主题(topic)压缩支持upsert。 但是当前的主题压缩方法既不可扩展,也不高效。
- 主题压缩在代理内(broker)完成。 它无法支持大量数据的插入,特别是在数据集很大的情况下。
- 主题压缩不支持将数据存储在分层存储中。
为了支持高效且可扩展的Upsert,该提案建议使用Apache Hudi将压缩后的数据存储在分层存储中。 图3展示了使用Apache Hudi支持主题压缩中的有效upserts的方法。
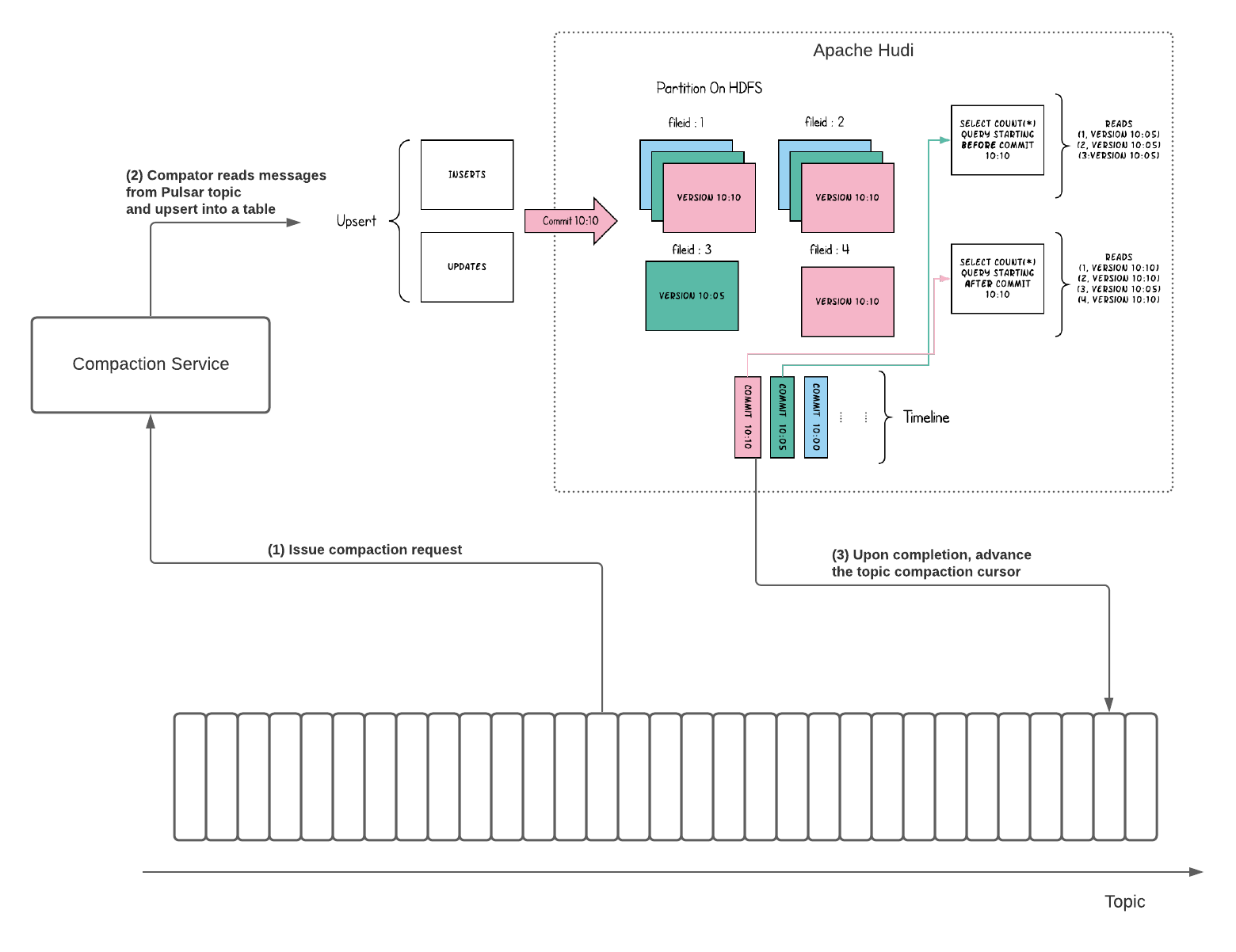
该想法是实现主题压缩服务。主题压缩服务可以作为单独的服务(即Pulsar函数)运行以压缩主题。
- 代理向压缩服务发出主题压缩请求。
- 压缩服务接收压缩请求,并读取消息并将其向上插入到Hudi表中。
- 完成upsert之后,将主题压缩游标前进到它压缩的最后一条消息。
主题压缩游标将引用位置的元数据存储在存储Hudi表的分层存储中。
4.3 将Hudi表当做Pulsar Topic
Hudi会在不同的即时时间维护对表执行的所有操作的时间轴,这有助于提供表的即时视图,同时还有效地支持按_arrival_顺序进行数据检索。Hudi支持从表中增量拉取变更。我们可以支持通过Hudi表备份的_ReadOnly_主题。这允许应用程序从Pulsar代理流式传输Hudi表的变更。图4展示了这个想法。

4.4 可扩展的元数据管理
当我们开始将所有数据存储在分层存储中时,该提案建议不存储卸载或压缩数据的元数据,而只依赖分层存储来存储卸载或压缩数据的元数据。
该提案提议在以下目录布局中组织卸载和压缩的数据。
- <tenant>/
- <namespace>/
- <topics>/
- segments/ <= Use Hudi to store the list of segments to guarantee ACID
- segment_<segment-id>
- ...
- cursors/
- <cursor A>/ <= Use Hudi to store the compacted table for cursor A.
- <cursor B>/ <= ...
5. 引用
[1] Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
[2] What is a Lakehouse? https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
[3] Diving Deep into the inner workings of the Lakehouse and Delta Lake. https://databricks.com/blog/2020/09/10/diving-deep-into-the-inner-workings-of-the-lakehouse-and-delta-lake.html
以上就是Apache Pulsar结合Hudi构建Lakehouse方案分析的详细内容,更多关于Apache Pulsar结合Hudi构建Lakehouse的资料请关注我们其它相关文章!
相关推荐
-

深入解析Apache Hudi内核文件标记机制
目录 1. 摘要 2. 为何引入Markers机制 3. 现有的直接标记机制及其局限性 4. 基于时间线服务器的标记机制提高写入性能 5. 标记相关的写入选项 6. 性能 7. 总结 1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3.Aliyun OSS)上针对非常大批量写入的性能问题. 并且演示如何通过引入基于时间轴服
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Lakehouse数据湖并发控制陷阱分析
目录 1. 概述 2. 数据湖并发控制中的陷阱 3. 模型 1:单写入,内联表服务 4. 模型2:单写入,异步表服务 5. 模型3:多写入 1. 概述 如今数据湖上的事务被认为是 Lakehouse 的一个关键特征. 但到目前为止,实际完成了什么? 目前有哪些方法? 它们在现实世界中的表现如何? 这些问题是本博客的重点. 有幸从事过各种数据库项目——RDBMS (Oracle).NoSQL 键值存储 (Voldemort).流数据库 (ksqlDB).闭源实时数据存储,当然还有 Apache H
-
Vertica集成Apache Hudi重磅使用指南
目录 1. 摘要 2. Apache Hudi介绍 3. 环境准备 4. Vertica和Apache Hudi集成 4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3 4.2 配置 Vertica 和 Apache HUDI 集成 4.3 如何让 Vertica 查看更改的数据 4.3.1 写入数据 4.3.2 更新数据 4.3.3 创建和查看数据的历史快照 1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
Apache Pulsar结合Hudi构建Lakehouse方案分析
目录 1. 动机 2. 分析 3. 当前方案 4. 新的Lakehouse存储方案 4.1 新的存储布局 4.2 支持高效Upserts 4.3 将Hudi表当做Pulsar Topic 4.4 可扩展的元数据管理 5. 引用 1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakehouse结合数据湖和数据仓库的优点:包括数据湖的低成本存储和开放数据格式访
-
Z-Order加速Hudi大规模数据集方案分析
目录 1. 背景 2. Z-Order介绍 3. 具体实现 3.1 z-value的生成和排序 3.1.1 基于映射策略的z值生成方法 3.1.2 基于RangeBounds的z-value生成策略 3.2 与Hudi结合 3.2.1 表数据的Z排序重组 3.2.2 收集保存统计信息 3.2.3 应用到Spark查询 4. 测试结果 1. 背景 多维分析是大数据分析的一个典型场景,这种分析一般带有过滤条件.对于此类查询,尤其是在高基字段的过滤查询,理论上只我们对原始数据做合理的布局,结合相关过滤
-
基于MongoDB数据库索引构建情况全面分析
前面的话 本文将详细介绍MongoDB数据库索引构建情况分析 概述 创建索引可以加快索引相关的查询,但是会增加磁盘空间的消耗,降低写入性能.这时,就需要评判当前索引的构建情况是否合理.有4种方法可以使用 1.mongostat工具 2.profile集合介绍 3.日志 4.explain分析 mongostat mongostat是mongodb自带的状态检测工具,在命令行下使用.它会间隔固定时间获取mongodb的当前运行状态,并输出.如果发现数据库突然变慢或者有其他问题的话,首先就要考虑采用
-
Vue项目实现换肤功能的一种方案分析
需求:网站换肤,主题切换.网站的主题色可以在几种常用颜色之间进行切换,还有相关图片.图标也要跟随主题进行切换. 不多说,先看下最终的实现效果: 文章由两部分组成:css切换,图片图标切换 css切换 1.在 static 目录下新建一个 styles 文件夹,在 styles 下新建一个 theme.scss 文件(项目使用了sass,会自动编译成css文件,如果没有使用这些预处理工具可以直接新建 theme.css),将需要替换的 CSS 声明在此文件中. .theme-test-btn {
-
Apache Pulsar 微信大流量实时推荐场景下实践详解
目录 导语 作者简介 实践 1:大流量场景下的 K8s 部署实践 实践 2:非持久化 Topic 的应用 实践 3:负载均衡与 Broker 缓存优化 实践 4:COS Offloader 开发与应用 未来展望与计划 导语 本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为<Apache Pulsar 在微信的大流量实时推荐场景实践>的分享.本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化.非持久化 Topic 的应用.负载均衡与 Bro
-
SpringBoot整合Apache Pulsar教程示例
目录 正文 准备工作 创建 SpringBoot 项目 添加 Maven 依赖 编写消息生产者 编写消息消费者 测试 总结 正文 推荐一个基于SpringBoot开发的全平台数据(数据库管理工具)功能比较完善,建议下载使用: github.com/EdurtIO/datacap 目前已经支持30多种数据源 Apache Pulsar 是一个开源的分布式 Pub-Sub 消息传递平台.它提供高可用性.持久性和性能,适用于处理大量的实时数据.SpringBoot 是一个非常流行的 Java Web
-
apache日志文件详解和实用分析命令
一.日志分析 如果apache的安装时采用默认的配置,那么在/logs目录下就会生成两个文件,分别是access_log和error_log 1).access_log access_log为访问日志,记录所有对apache服务器进行请求的访问,它的位置和内容由CustomLog指令控制,LogFormat指令可以用来简化该日志的内容和格式 例如,我的其中一台服务器配置如下: 复制代码 代码如下: CustomLog "| /usr/sbin/rotatelogs /var/log/apache
-
由Apache 500错误引出的临时文件问题分析解决
查看apache日志,发觉是mod_fcgid模块异常,提示"Connection reset by peer:mod_fcgid:error reading data from FastCGI server"."Premature end of script headers:index.php"."process /usr/... apache/cgi-bin exit(communication error, get unexpected signal
-
较为全面的Asp.net提交验证方案分析 (上)
比如: 验证码存储在页面代码或Cookies里,暴露给客户端: 通过Session存储的验证码,虽然解决了安全问题,但一个用户只使用一个变量存储验证码,假如用户同时打开一个以上的页面,分别提交的话,就无法正常使用了: 验证码不会过期,这会留下隐患,使暴力破解变得可行(当然也可以通过刷新间隔.提交间隔.黑名单等手段加以控制): 此外还有伴随着提交产生的另一个问题--重复提交. 为解决上述问题,我曾走过不少弯路,后来总结出了一个方案可以很好的解决这些问题,本文将结合ADO.NET Entity Fr