Python MNIST手写体识别详解与试练
【人工智能项目】MNIST手写体识别实验及分析

1.实验内容简述
1.1 实验环境
本实验采用的软硬件实验环境如表所示:

在Windows操作系统下,采用基于Tensorflow的Keras的深度学习框架,对MNIST进行训练和测试。
采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络、短期和长期的网络以及更广泛的一般网络。使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层次的,网络组建相对直观,所以本次选用Keras人工智能框架,其专注于用户友好,模块化和可扩展性。
1.2 MNIST数据集介绍
MNIST(官方网站)是非常有名的手写体数字识别数据集。它由手写体数字的图片和相对应的标签组成,如:

MNIST数据集分为训练图像和测试图像。训练图像60000张,测试图像10000张,每一个图片代表0-9中的一个数字,且图片大小均为28*28的矩阵。
- train-images-idx3-ubyte.gz: training set images (9912422 bytes) 训练图片
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes) 训练标签
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) 测试图片
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) 测试标签
1.3 数据预处理
数据预处理阶段对图像进行归一化处理,我们将图片中的这些值缩小到 0 到 1 之间,然后将其馈送到神经网络模型。为此,将图像组件的数据类型从整数转换为浮点数,然后除以 255。这样更容易训练,以下是预处理图像的函数:务必要以相同的方式对训练集和测试集进行预处理:
之后对标签进行one-hot编码处理:将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点;机器学习算法中,特征之间距离的计算或相似度的常用计算方法都是基于欧式空间的;将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理
2.实验核心代码
(1)MLP感知器
# Build MLP
model = Sequential()
model.add(Dense(units=256,
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dense(units=128,
kernel_initializer='normal',
activation='relu'))
model.add(Dense(units=64,
kernel_initializer='normal',
activation='relu'))
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
model.summary()
(2)CNN卷积神经网络
# Build LeNet-5 model = Sequential() model.add(Conv2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(28, 28, 1), activation='relu')) # C1 model.add(MaxPooling2D(pool_size=(2, 2))) # S2 model.add(Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation='relu')) # C3 model.add(MaxPooling2D(pool_size=(2, 2))) # S4 model.add(Flatten()) model.add(Dense(120, activation='tanh')) # C5 model.add(Dense(84, activation='tanh')) # F6 model.add(Dense(10, activation='softmax')) # output model.summary()
模型解释
模型训练过程中,我们用到LENET-5的卷积神经网络结构。

第一层,卷积层
这一层的输入是原始的图像像素,LeNet-5 模型接受的输入层大小是28x28x1。第一卷积层的过滤器的尺寸是5x5,深度(卷积核种类)为6,不使用全0填充,步长为1。因为没有使用全0填充,所以这一层的输出的尺寸为32-5+1=28,深度为6。这一层卷积层参数个数是5x5x1x6+6=156个参数(可训练参数),其中6个为偏置项参数。因为下一层的节点矩阵有有28x28x6=4704个节点(神经元数量),每个节点和5x5=25个当前层节点相连,所以本层卷积层总共有28x28x6x(5x5+1)个连接。
第二层,池化层
这一层的输入是第一层的输出,是一个28x28x6=4704的节点矩阵。本层采用的过滤器为2x2的大小,长和宽的步长均为2,所以本层的输出矩阵大小为14x14x6。原始的LeNet-5 模型中使用的过滤器和这里将用到的过滤器有些许的差别,这里不过多介绍。
第三层,卷积层
本层的输入矩阵大小为14x14x6,使用的过滤器大小为5x5,深度为16。本层不使用全0填充,步长为1。本层的输出矩阵大小为10x10x16。按照标准卷积层本层应该有5x5x6x16+16=2416个参数(可训练参数),10x10x16x(5x5+1)=41600个连接。
第四层,池化层
本层的输入矩阵大小是10x10x16,采用的过滤器大小是2x2,步长为2,本层的输出矩阵大小为5x5x16。
第五层,全连接层
本层的输入矩阵大小为5x5x16。如果将此矩阵中的节点拉成一个向量,那么这就和全连接层的输入一样了。本层的输出节点个数为120,总共有5x5x16x120+120=48120个参数。
第六层,全连接层
本层的输入节点个数为120个,输出节点个数为84个,总共参数为120x84+84=10164个。
第七层,全连接层
LeNet-5 模型中最后一层输出层的结构和全连接层的结构有区别,但这里我们用全连接层近似的表示。本层的输入节点为84个,输出节点个数为10个,总共有参数84x10+10=850个。
模型过程
初始参数设定好之后开始训练,每次训练需要微调参数以得到更好的训练结果,经过多次尝试,最终设定参数为:
- 优化器:adam优化器
- 训练轮数:10
- 每次输入的数据量:500
LENET-5的卷积神经网络对MNIST数据集进行训练,并采用上述的模型参数,进行10轮训练,在训练集上达到了95%的准确率

3.结果分析机器总结
3.1 模型测试以及结果分析
为了验证模型的鲁棒性,在上述最优参数下保存在验证集上性能最好的模型,在测试集上进行最终的测试,得到最终的准确率为:95.13%.
为了更好的分析我们的结果,这里用混淆矩阵来评估我们的模型性能。在模型评估之前,先学习一些指标。
TP(True Positive):将正类预测为正类数,真实为0,预测也为0FN(False Negative):将正类预测为负类数,真实为0,预测为1FP(False Positive):将负类预测为正类数, 真实为1,预测为0。TN(True Negative):将负类预测为负类数,真实为1,预测也为1混淆矩阵定义及表示含义:
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值,下面以本次案例为例,看下矩阵表现形式,如下:


3.2 结果对比
并与四层全连接层模型进行对比,全连接层的模型结构如下:

其结果如下:

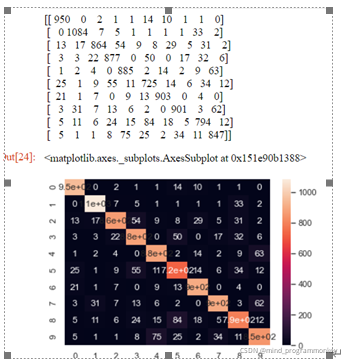
总之,从结果上来看,最后经过不断地参数调优最终训练出了一个分类正确率在95%左右的模型,并且通过实验证明了模型具有很强的鲁棒性。
3.3 模型的预测
对单张图像进行预测:

4 总结
本文通过对卷积神经网络的研究流程分析,提出了一套完整的卷积神经网络MNIST手写体识别流程并也将本文的数据集分类正确率提高到95%的水平;其次,本文构建的模型是具有普适性的,可以稍加改进就应用于不同的数据集进行特征提取及分类。再次,本文在构建模型的过程中综合考虑了计算资源和时间成本,构建的卷积神经网络模型在普通的个人笔记本上即可进行训练,此外还增加了MLP感知器作为对比,从结果中看出卷积神经网络效果更好。综合以上几点来看,本文的研究具有现实可应用性,具有可推广性,因而具有较高的实用价值!

到此这篇关于Python MNIST手写体识别详解与试练的文章就介绍到这了,更多相关Python 手写体识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python MNIST手写识别数据调用API的方法
MNIST数据集比较小,一般入门机器学习都会采用这个数据集来训练 下载地址:yann.lecun.com/exdb/mnist/ 有4个有用的文件: train-images-idx3-ubyte: training set images train-labels-idx1-ubyte: training set labels t10k-images-idx3-ubyte: test set images t10k-labels-idx1-ubyte: test set labels The t
-
Python实战小项目之Mnist手写数字识别
目录 程序流程分析图: 传播过程: 代码展示: 创建环境 准备数据集 下载数据集 下载测试集 绘制图像 搭建神经网络 训练模型 测试模型 保存训练模型 运行结果展示: 程序流程分析图: 传播过程: 代码展示: 创建环境 使用<pip install+包名>来下载torch,torchvision包 准备数据集 设置一次训练所选取的样本数Batch_Sized的值为512,训练此时Epochs的值为8 BATCH_SIZE = 512 EPOCHS = 8 device = torch.devi
-
Python利用全连接神经网络求解MNIST问题详解
本文实例讲述了Python利用全连接神经网络求解MNIST问题.分享给大家供大家参考,具体如下: 1.单隐藏层神经网络 人类的神经元在树突接受刺激信息后,经过细胞体处理,判断如果达到阈值,则将信息传递给下一个神经元或输出.类似地,神经元模型在输入层输入特征值x之后,与权重w相乘求和再加上b,经过激活函数判断后传递给下一层隐藏层或输出层. 单神经元的模型只有一个求和节点(如左下图所示).全连接神经网络(Full Connected Networks)如右下图所示,中间层有多个神经元,并且每层的每个
-
Python利用逻辑回归模型解决MNIST手写数字识别问题详解
本文实例讲述了Python利用逻辑回归模型解决MNIST手写数字识别问题.分享给大家供大家参考,具体如下: 1.MNIST手写识别问题 MNIST手写数字识别问题:输入黑白的手写阿拉伯数字,通过机器学习判断输入的是几.可以通过TensorFLow下载MNIST手写数据集,通过import引入MNIST数据集并进行读取,会自动从网上下载所需文件. %matplotlib inline import tensorflow as tf import tensorflow.examples.tutori
-
python读取mnist数据集方法案例详解
mnist手写数字数据集在机器学习中非常常见,这里记录一下用python从本地读取mnist数据集的方法. 数据集格式介绍 这部分内容网络上很常见,这里还是简明介绍一下.网络上下载的mnist数据集包含4个文件: 前两个分别是测试集的image和label,包含10000个样本.后两个是训练集的,包含60000个样本..gz表示这个一个压缩包,如果进行解压的话,会得到.ubyte格式的二进制文件. 上图是训练集的label和image数据的存储格式.两个文件最开始都有magic number和n
-
Python MNIST手写体识别详解与试练
[人工智能项目]MNIST手写体识别实验及分析 1.实验内容简述 1.1 实验环境 本实验采用的软硬件实验环境如表所示: 在Windows操作系统下,采用基于Tensorflow的Keras的深度学习框架,对MNIST进行训练和测试. 采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络.短期和长期的网络以及更广泛的一般网络.使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层
-
Python实战之MNIST手写数字识别详解
目录 数据集介绍 1.数据预处理 2.网络搭建 3.网络配置 关于优化器 关于损失函数 关于指标 4.网络训练与测试 5.绘制loss和accuracy随着epochs的变化图 6.完整代码 数据集介绍 MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,且内置于keras.本文采用Tensorflow下Keras(Keras中文文档)神经网络API进行网络搭建. 开始之前,先回忆下机器学习
-
使用C++调用Python代码的方法详解
一.配置python环境问题 1.首先安装Python(版本无所谓),安装的时候选的添加python路径到环境变量中 安装之后的文件夹如下所示: 2.在VS中配置环境和库 右击项目->属性->VC++目录 1)包含目录: Python安装路径/include 2)库目录: Python安装路径/libs 右击项目->属性->连接器->输入->附加依赖库 debug下: python安装目录/libs/python37_d.lib release下: python安装目录
-
基于Python实现自动扫雷详解
目录 准备 实现思路 窗体截取 雷块分割 雷块识别 扫雷算法实现 用Python+OpenCV实现了自动扫雷,突破世界记录,我们先来看一下效果吧. 中级 - 0.74秒 3BV/S=60.81 相信许多人很早就知道有扫雷这么一款经典的游(显卡测试)戏(软件),更是有不少人曾听说过中国雷圣,也是中国扫雷第一.世界综合排名第二的郭蔚嘉的顶顶大名.扫雷作为一款在Windows9x时代就已经诞生的经典游戏,从过去到现在依然都有着它独特的魅力:快节奏高精准的鼠标操作要求.快速的反应能力.刷新纪录的快感,这
-
关于Python中的闭包详解
目录 1.闭包的概念 2.实现一个闭包 3.在闭包中外函数把临时变量绑定给内函数 4.闭包中内函数修改外函数局部变量 5.注意: 6.练习: 总结 1.闭包的概念 请大家跟我理解一下,如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数.闭包: 在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用.这样就构成了一个闭包.一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失.但
-
Python实现语音合成功能详解
目录 导语 1.直接使用 2. 获取权限 2.1 环境准备: 2.2 获取权限 3. 代码实现 3.1 获取access_token 3.2 获取转换后音频 3.3 配置接口参数 3.4 完整demo 3.5 执行 导语 今天就给大家带来个语言识别跟语言赚文字的小工具感兴趣的铁汁萌可以往下滑了 1.直接使用 在1.2官网注册后拿到APISecret和APIKey,直接复制文章2.4demo代码,保存为online_tts.py,在命令行执行 python online_tts.py -clien
-
利用Python生成随机验证码详解
目录 1.先搞环境 2.开始码代码 3. 加干扰 4. 加入更多的干扰 5. 验证码 + 随机字符 6. 验证码保存本地(选) 最近感觉被大数据定义成机器人了,随便看个网页都跳验证码. 怎么用python绕验证码是个令人头秃的事情, 我投降!那么今天手把手教大家如何写验证码,去为难别人,让他们头秃. 说错了,其实就是教大家如何通过python代码去生成验证码~~ 1.先搞环境 1.我们需要你电脑有python3.4以上的版本 2.pip安装PIL包 pip install pillow 3.默念
-
pytorch实现MNIST手写体识别
本文实例为大家分享了pytorch实现MNIST手写体识别的具体代码,供大家参考,具体内容如下 实验环境 pytorch 1.4 Windows 10 python 3.7 cuda 10.1(我笔记本上没有可以使用cuda的显卡) 实验过程 1. 确定我们要加载的库 import torch import torch.nn as nn import torchvision #这里面直接加载MNIST数据的方法 import torchvision.transforms as transform
-
python目标检测yolo2详解及预测代码复现
目录 前言 实现思路 1.yolo2的预测思路(网络构建思路) 2.先验框的生成 3.利用先验框对网络的输出进行解码 4.进行得分排序与非极大抑制筛选 实现结果 前言 ……最近在学习yolo1.yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义. 尽量配合代码观看会更容易理解. 直接下载 实现思路 1.yolo2的预测思路(网络构建思路) YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19
-
MySQL数据库设计之利用Python操作Schema方法详解
弓在箭要射出之前,低声对箭说道,"你的自由是我的".Schema如箭,弓似Python,选择Python,是Schema最大的自由.而自由应是一个能使自己变得更好的机会. Schema是什么? 不管我们做什么应用,只要和用户输入打交道,就有一个原则--永远不要相信用户的输入数据.意味着我们要对用户输入进行严格的验证,web开发时一般输入数据都以JSON形式发送到后端API,API要对输入数据做验证.一般我都是加很多判断,各种if,导致代码很丑陋,能不能有一种方式比较优雅的验证用户数据呢