PyTorch零基础入门之逻辑斯蒂回归
目录
- 学习总结
- 一、sigmoid函数
- 二、和Linear的区别
- 三、逻辑斯蒂回归(分类)PyTorch实现
- Reference
学习总结
(1)和上一讲的模型训练是类似的,只是在线性模型的基础上加个sigmoid,然后loss函数改为交叉熵BCE函数(当然也可以用其他函数),另外一开始的数据y_data也从数值改为类别0和1(本例为二分类,注意x_data和y_data这里也是矩阵的形式)。
一、sigmoid函数
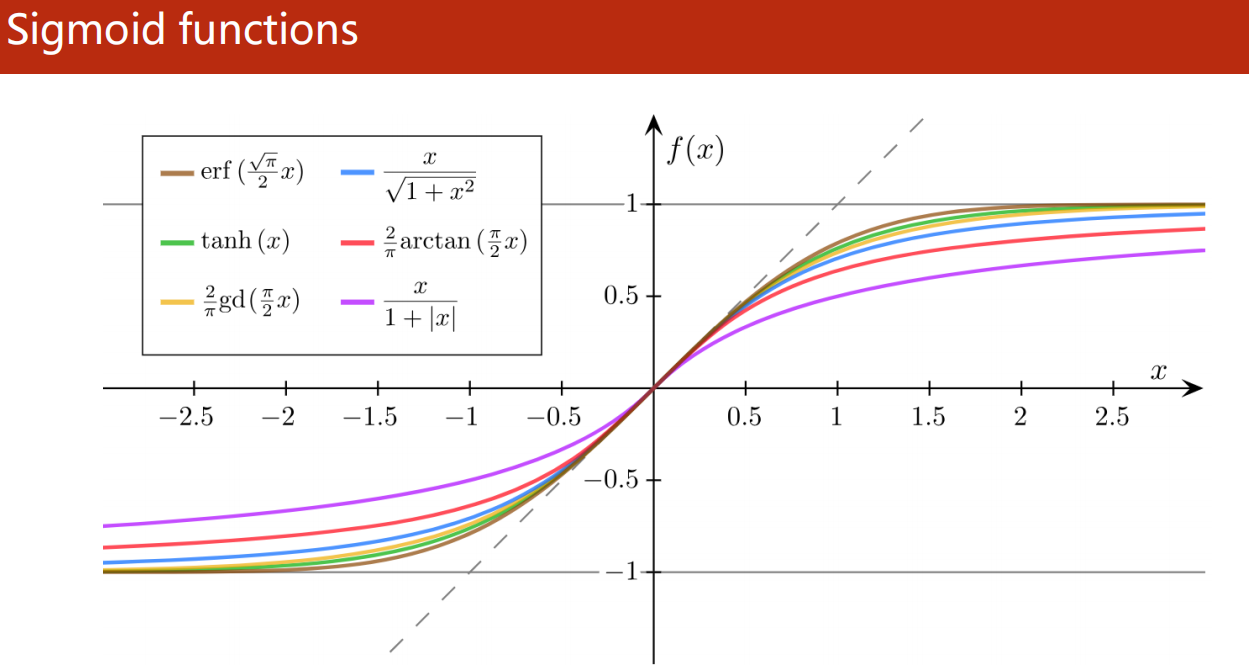
logistic function是一种sigmoid函数(还有其他sigmoid函数),但由于使用过于广泛,pytorch默认logistic function叫为sigmoid函数。还有如下的各种sigmoid函数:
二、和Linear的区别
逻辑斯蒂和线性模型的unit区别如下图:

sigmoid函数是不需要参数的,所以不用对其初始化(直接调用nn.functional.sigmoid即可)。
另外loss函数从MSE改用交叉熵BCE:尽可能和真实分类贴近。

如下图右方表格所示,当 y ^ \hat{y} y^越接近y时则BCE Loss值越小。

三、逻辑斯蒂回归(分类)PyTorch实现
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 18 08:35:00 2021
@author: 86493
"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
import numpy as np
# 准备数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
losslst = []
class LogisticRegressionModel(nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
# 和线性模型的网络的唯一区别在这句,多了F.sigmoid
y_predict = F.sigmoid(self.linear(x))
return y_predict
model = LogisticRegressionModel()
# 使用交叉熵作损失函数
criterion = torch.nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),
lr = 0.01)
# 训练
for epoch in range(1000):
y_predict = model(x_data)
loss = criterion(y_predict, y_data)
# 打印loss对象会自动调用__str__
print(epoch, loss.item())
losslst.append(loss.item())
# 梯度清零后反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 画图
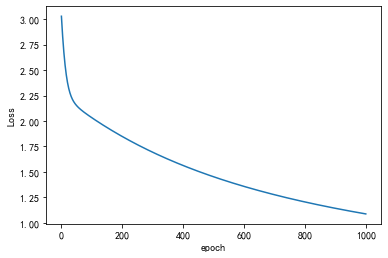
plt.plot(range(1000), losslst)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
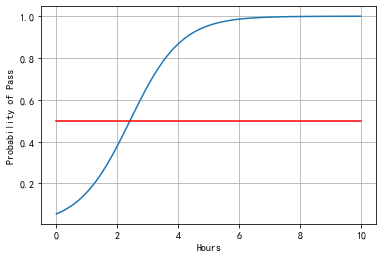
# test
# 每周学习的时间,200个点
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view((200, 1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
# 画 probability of pass = 0.5的红色横线
plt.plot([0, 10], [0.5, 0.5], c = 'r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
可以看出处于通过和不通过的分界线是Hours=2.5。
Reference
到此这篇关于PyTorch零基础入门之逻辑斯蒂回归的文章就介绍到这了,更多相关PyTorch 逻辑斯蒂回归内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python深度学习pytorch神经网络汇聚层理解
目录 最大汇聚层和平均汇聚层 填充和步幅 多个通道 我们的机器学习任务通常会跟全局图像的问题有关(例如,"图像是否包含一只猫呢?"),所以我们最后一层的神经元应该对整个输入的全局敏感.通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有有时保留在中间层. 此外,当检测较底层的特征时(例如之前讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性.例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[
-
使用python画出逻辑斯蒂映射(logistic map)中的分叉图案例
逻辑斯蒂映射在混沌数学中是一个很经典的例子,它可以说明混沌可以从很简单的非线性方程中产生. 逻辑斯蒂映射公式如下: x_n表示当前人口与最大人口数量的比值,mu为参数,相当于人口增长速率. 分叉图描绘的是不同mu情况下,x收敛的值的分布图. 参考地址 python代码如下: from tqdm import tqdm import matplotlib.pyplot as plt import numpy as np def LogisticMap(): mu = np.arange(2, 4,
-
Python深度学习pytorch卷积神经网络LeNet
目录 LeNet 模型训练 在本节中,我们将介绍LeNet,它是最早发布的卷积神经网络之一.这个模型是由AT&T贝尔实验室的研究院Yann LeCun在1989年提出的(并以其命名),目的是识别手写数字.当时,LeNet取得了与支持向量机性能相媲美的成果,成为监督学习的主流方法.LeNet被广泛用于自动取款机中,帮助识别处理支票的数字. LeNet 总体来看,LeNet(LeNet-5)由两个部分组成: 卷积编码器: 由两个卷积层组成 全连接层密集快: 由三个全连接层组成 每个卷积块中的基本单元
-
Python深度学习之Pytorch初步使用
一.Tensor Tensor(张量是一个统称,其中包括很多类型): 0阶张量:标量.常数.0-D Tensor:1阶张量:向量.1-D Tensor:2阶张量:矩阵.2-D Tensor:-- 二.Pytorch如何创建张量 2.1 创建张量 import torch t = torch.Tensor([1, 2, 3]) print(t) 2.2 tensor与ndarray的关系 两者之间可以相互转化 import torch import numpy as np t1 = np.arra
-
Python深度学习pytorch实现图像分类数据集
目录 读取数据集 读取小批量 整合所有组件 目前广泛使用的图像分类数据集之一是MNIST数据集.如今,MNIST数据集更像是一个健全的检查,而不是一个基准. 为了提高难度,我们将在接下来的章节中讨论在2017年发布的性质相似但相对复杂的Fashion-MNIST数据集. import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import to
-
PyTorch零基础入门之逻辑斯蒂回归
目录 学习总结 一.sigmoid函数 二.和Linear的区别 三.逻辑斯蒂回归(分类)PyTorch实现 Reference 学习总结 (1)和上一讲的模型训练是类似的,只是在线性模型的基础上加个sigmoid,然后loss函数改为交叉熵BCE函数(当然也可以用其他函数),另外一开始的数据y_data也从数值改为类别0和1(本例为二分类,注意x_data和y_data这里也是矩阵的形式). 一.sigmoid函数 logistic function是一种sigmoid函数(还有其他sigmo
-
PyTorch零基础入门之构建模型基础
目录 一.神经网络的构造 二.神经网络中常见的层 2.1 不含模型参数的层 2.2 含模型参数的层 (1)代码栗子1 (2)代码栗子2 2.3 二维卷积层 stride 2.4 池化层 三.LeNet模型栗子 三点提醒: 四.AlexNet模型栗子 Reference 一.神经网络的构造 PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活.Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型.
-
python回归分析逻辑斯蒂模型之多分类任务详解
目录 逻辑斯蒂回归模型多分类任务 1.ovr策略 2.one vs one策略 3.softmax策略 逻辑斯蒂回归模型多分类案例实现 逻辑斯蒂回归模型多分类任务 上节中,我们使用逻辑斯蒂回归完成了二分类任务,针对多分类任务,我们可以采用以下措施,进行分类. 我们以三分类任务为例,类别分别为a,b,c. 1.ovr策略 我们可以训练a类别,非a类别的分类器,确认未来的样本是否为a类: 同理,可以训练b类别,非b类别的分类器,确认未来的样本是否为b类: 同理,可以训练c类别,非c类别的分类器,确认
-
Django零基础入门之运行Django版的hello world
目录 1.项目目录及文件说明: 2.项目与应用app的关系: 3.使用django框架编写hello world! 1.项目目录及文件说明: manage.py django中的一个命令行工具,管理django项目: __init__.py 空文件,告诉python这个目录是python报: settings.py 配置文件,包含数据库信息,调试标志,静态文件等: urls.py django项目的URL声明: wsgi.py 部署服务器用到: templates 存放html文件. 2.项目与
-
Bootstrap零基础入门教程(三)
什么是 Bootstrap? Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架.Bootstrap 是基于 HTML.CSS.JAVASCRIPT 的. 历史 Bootstrap 是由 Twitter 的 Mark Otto 和 Jacob Thornton 开发的.Bootstrap 是 2011 年八月在 GitHub 上发布的开源产品. 写到这里,这篇从零开始学Bootstrap(3)我想写以下几个内容: 1. 基于我对Bootstrap的理解,做一个小小的总结.
-
Bootstrap零基础入门教程(二)
什么是 Bootstrap? Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架.Bootstrap 是基于 HTML.CSS.JAVASCRIPT 的. 历史 Bootstrap 是由 Twitter 的 Mark Otto 和 Jacob Thornton 开发的.Bootstrap 是 2011 年八月在 GitHub 上发布的开源产品. 本文重点给大家介绍Bootstrap零基础入门教程(二),具体详情如下所示: 过程中会频繁查阅资料的网站: http://www.
-
C++中的STL中map用法详解(零基础入门)
目录 一.什么是 map ? 二.map的定义 2.1 头文件 2.2 定义 2.3 方法 三.实例讲解 3.1 增加数据 3.2 删除数据 3.3 修改数据 3.4 查找数据 3.5 遍历元素 3.6 其它方法 四.总结 map 在编程中是经常使用的一个容器,本文来讲解一下 STL 中的 map,赶紧来看下吧! 一.什么是 map ? map 是具有唯一键值对的容器,通常使用红黑树实现. map 中的键值对是 key value 的形式,比如:每个身份证号对应一个人名(反过来不成立哦!),其中
-
Django零基础入门之调用漂亮的HTML前端页面
引言: Django如何调用HTML前端页面呢? Django怎样去调用漂亮的HTML前端页面呢? 就直接使用render方法即可! render方法是django封装好用来调用HTML前端模板的方法! 1.模板放在哪? 在主目录下创建一个templates目录用来存放所有的html的模板文件.(如果是使用pycharm创建django项目的话,默认就会自动创建这个目录哦!但是用命令创建django项目的话是没有此目录的!) templates目录里面再新建各个以app名字命名的目录来存放
-
Django零基础入门之路由path和re_path详解
目录 urls.py文件中的path和re_path 1.path的基本规则: 2.默认支持的转换器有: 3.re_path正则匹配: Django中实战使用path和re_path 1.urls.py文件: 2.views.py视图函数文件: 3.效果: 假设现在有个需求: 需要通过URL进行参数传递,我们该怎么做呢? 其中有个方法就是本文要讲的内容--path和进阶版的re_path. urls.py文件中的path和re_path 1.path的基本规则: path('test