Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言
喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢?
今天带大家爬取喜马拉雅音频数据,一起期待吧!!
这个案例的视频地址在这里
https://v.douyu.com/show/a2JEMJj3e3mMNxml
项目目标
爬取喜马拉雅音频数据
受害者地址
本文知识点:
1、系统分析网页性质
2、多层数据解析
3、海量音频数据保存
环境:
1.确定数据所在的链接地址(url)
2.通过代码发送url地址的请求
3.解析数据(要的, 筛选不要的)
4.数据持久化(保存)
案例思路:
1. 在静态数据中获取音频的id值
2. 发送指定id值json数据请求(src)
3. 从json数据中解析音频所对应的URL地址 开始写代码
先导入所需的模块
import requests import parsel # 数据解析模块 import re
1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
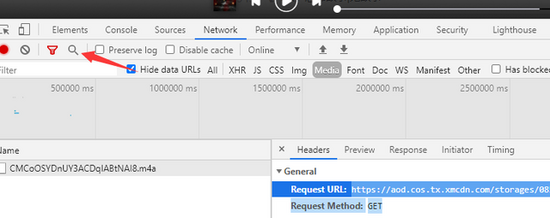
打开开发者工具,播放一个音频,在Madie里面可以找到一个数据包

复制URL,搜索
找到ID值
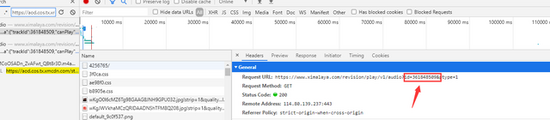
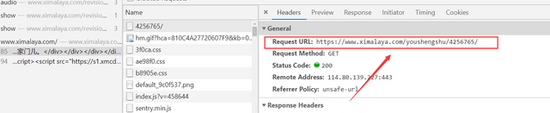
继续搜索,找到请求头参数
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers) html_data = response.text
3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后还要处理文件名非法字符
def change_title(title): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |' new_title = re.sub(pattern, "_", title) # 替换为下划线 return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
运行代码,效果如下图

到此这篇关于Python爬虫实战案例之取喜马拉雅音频数据详解的文章就介绍到这了,更多相关Python爬取喜马拉雅音频数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫请求头设置代码
一.requests设置请求头: import requests url="http://www.targetweb.com" headers={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cache-Control':'max-age=0', 'Connection':'keep-alive', 'Referer':'http://www.baidu.
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成 1)搜索要点 美团美食,地址:北京,搜索关键词:火锅 2)爬取的url https://bj.meituan.com/s/%E7%81%AB%E9%94%85/ 3)说明 url会有自动编码中文功能.所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85. 通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词. 这样我们就可以了解到当前url的构造. 2.分析页面数据来源(F12开发者工具) 开启F12开发
-
Python爬虫抓取指定网页图片代码实例
想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容 (3)设置循环列表,重复抓取和保存内容 以下介绍了两种方法实现抓取指定网页中图片 (1)方法一:使用正则表达式过滤抓到的 html 内容字符串 # 第一个简单的爬取图片的程序 import urllib.request # python自带
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-

Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬虫入门案例之爬取二手房源数据
本文重点 系统分析网页性质 结构化的数据解析 csv数据保存 环境介绍 python 3.8 pycharm 专业版 >>> 激活码 #模块使用 requests >>> pip install requests parsel >>> pip install parsel csv [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 爬虫代码实现步骤: 发送请求 >>> 获取数据 &g
-
Python爬虫入门案例之爬取去哪儿旅游景点攻略以及可视化分析
目录 知识点 第三方库 开发环境: 爬虫程序 导入模块 发送请求 获取数据(网页源代码) 解析网页(re正则表达式,css选择器,xpath,bs4/六年没更新了,json) 向详情页网站发送请求(get,post) 解析网页 保存数据 数据可视化 导入模块 导入数据 旅游胜地Top10及对应费用 出游方式分析 出游时间分析 出游玩法分析 知识点 requests 发送网络请求 parsel 解析数据 csv 保存数据 第三方库 requests >>> pip install requ
-
python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下. 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外. 首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别.思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
Python爬虫实现简单的爬取有道翻译功能示例
本文实例讲述了Python爬虫实现简单的爬取有道翻译功能.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import urllib.request import urllib.parse import json while True : content = input("请输入需要翻译的内容:(按q退出)") if content == 'q' : break url = 'http://fanyi.youdao.com/trans