Python3 io文本及原始流I/O工具用法详解
io模块在解释器的内置open()之上实现了一些类来完成基于文件的输入和输出操作。这些类得到了适当的分解,从而可以针对不同的用途重新组合——例如,支持向一个网络套接字写Unicode数据。
1.1 内存中的流
StringIO提供了一种很便利的方式,可以使用文件API(如read()、write()等)处理内存中的文本。有些情况下,与其他一些字符串连接技术相比,使用StringIO构造大字符串可以提供更好的性能。内存中的流缓冲区对测试也很有用,写入磁盘上真正的文件并不会减慢测试套件的速度。
下面是使用StringIO缓冲区的一些标准例子。
import io
# Writing to a buffer
output = io.StringIO()
output.write('This goes into the buffer. ')
print('And so does this.', file=output)
# Retrieve the value written
print(output.getvalue())
output.close() # discard buffer memory
# Initialize a read buffer
input = io.StringIO('Inital value for read buffer')
# Read from the buffer
print(input.read())
这个例子使用了read(),不过也可以用readline()和readlines()方法。StringIO类还提供了一个seek()方法,读取文本时可以在缓冲区中跳转,如果使用一种前向解析算法,则这个方法对于回转很有用。
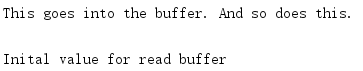
要处理原始字节而不是Unicode文本,可以使用BytesIO。
import io
# Writing to a buffer
output = io.BytesIO()
output.write('This goes into the buffer. '.encode('utf-8'))
output.write('ÁÇÊ'.encode('utf-8'))
# Retrieve the value written
print(output.getvalue())
output.close() # discard buffer memory
# Initialize a read buffer
input = io.BytesIO(b'Inital value for read buffer')
# Read from the buffer
print(input.read())
写入BytesIO实例的值一定是bytes而不是str。

1.2 为文本数据包装字节流
原始字节流(如套接字)可以被包装为一个层来处理串编码和解码,从而可以更容易地用于处理文本数据。TextIOWrapper类支持读写。write_through参数会禁用缓冲,并且立即将写至包装器的所有数据刷新输出到底层缓冲区。
import io
# Writing to a buffer
output = io.BytesIO()
wrapper = io.TextIOWrapper(
output,
encoding='utf-8',
write_through=True,
)
wrapper.write('This goes into the buffer. ')
wrapper.write('ÁÇÊ')
# Retrieve the value written
print(output.getvalue())
output.close() # discard buffer memory
# Initialize a read buffer
input = io.BytesIO(
b'Inital value for read buffer with unicode characters ' +
'ÁÇÊ'.encode('utf-8')
)
wrapper = io.TextIOWrapper(input, encoding='utf-8')
# Read from the buffer
print(wrapper.read())
这个例子使用了一个BytesIO实例作为流。对应bz2、http,server和subprocess的例子展示了如何对其他类型的类似文件的对象使用TextIOWrapper。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
赞 (0)