python使用BeautifulSoup与正则表达式爬取时光网不同地区top100电影并对比
前言
还有一年多就要毕业了,不准备考研的我要着手准备找实习及工作了,所以一直没有更新。
因为Python是自学不久,发现很久不用的话以前学过的很多方法就忘了,今天打算使用简单的BeautifulSoup和一点正则表达式的方法来爬一下top100电影,当然,我们并不仅是使用爬虫爬取数据,这样的话,数据中存在很多的对人有用的信息则被忽略了。所以,爬取数据只是开头,对这些数据根据意愿进行分析,或许能有额外的收获。
注:本人还是Python菜鸟,若有错误欢迎指正
本次我们爬取时光网(http://www.mtime.com/top/movie/top100/)上的电影排名,该网站网页结构较简单,爬取方便。
步骤:
1.爬取时光网top100电影,华语top100电影,日本top100电影,韩国top100电影的排名情况,电影名字,电影简介,评分及评价人数
2. 将爬取数据保存为csv格式后,取出并使用matplotlib绘图库分析对比评论人数一项
3.将结果图像保存
步骤一:爬取

由上图可知电影信息在 li 节点内,而且发现第一页与后面网页地址不同,需要进行判断。
第一页地址为:http://www.mtime.com/top/movie/top100/
第二页地址为:http://www.mtime.com/top/movie/top100/index-2.html
第三页及后面地址均与第二页相似,仅网址的数字相应增加,所以更改数字即可爬取
import requests
from bs4 import BeautifulSoup
import re
import csv
#定义爬取函数
def get_infos(htmls, csvname):
#信息头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
#flag在写入文件时判断是否为首行
flag = True
#判断第一页网址,第二页及其后的网址
for i in range(10):
if i == 0:
html = htmls
else:
html = htmls + 'index-{}.html'.format(str(i+1))
res = requests.get(html, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
alls = soup.select('#asyncRatingRegion > li') #选取网页的li节点的内容
#对节点内容进行循环遍历
for one in alls:
paiming = one.div.em.string #排名
names = str(one.select('div.mov_pic > a')) #电影名称并将列表字符串化
name = re.findall('.*?title="(.*?)">.*?', names, re.S)[0] #使用正则表达式提取内容
content = str(one.select('div.mov_con > p.mt3')) #评论
realcontent = re.findall('.*?mt3">(.*?)</p>', content, re.S)[0] #同上
p1 = one.find(name='span', attrs={'class': 'total'}, text=re.compile('\d')) #评分在两个节点,
p2 = one.find(name='span', attrs={'class': 'total2'}, text=re.compile('.\d'))
#判断评分是否为空
if p1 and p2 != None:
p1 = p1.string
p2 = p2.string
else:
p1 = 'no'
p2 = ' point'
point = p1 + p2 + '分'
numbers = one.find(text=re.compile('评分')) #评分数量
# 保存为csv
csvnames = 'C:\\Users\lenovo\Desktop\\' + csvname + '.csv'
with open(csvnames, 'a+', encoding='utf-8') as f:
writer = csv.writer(f)
if flag:
writer.writerow(('paiming', 'name', 'realcontent', 'point', 'numbers'))
writer.writerow((paiming, name, realcontent, point, numbers))
flag = False
#调用函数
Japan_html = 'http://www.mtime.com/top/movie/top100_japan/'
csvname1 = 'Japan_top'
get_infos(Japan_html, csvname1)
Korea_html = 'http://www.mtime.com/top/movie/top100_south_korea/'
csvname2 = 'Korea_top'
get_infos(Korea_html, csvname2)
这里要注意的是要有些电影没有评分,为了预防出现这种情况,所以要进行判断
注:上述没有添加华语电影top100及所有电影top100的代码,可自行添加。
爬取结果部分内容如下:

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
步骤二和三:导入数据并使用matplotlib分析,保存分析图片
import csv
from matplotlib import pyplot as plt
#中文乱码处理
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
def read_csv(csvname):
csvfile_name = 'C:\\Users\lenovo\Desktop\\' + csvname + '.csv'
#打开文件并存入列表
with open(csvfile_name,encoding='utf-8') as f:
reader = csv.reader(f)
header_row = next(reader)
name = []
for row in reader:
name.append(row)
#取列表中非空元素
real = []
for i in name:
if len(i) != 0:
real.append(i)
#去除中文并将数据转换为整形
t = 0
ss = []
for j in real:
ss.append(int(real[t][4][:-5]))
t += 1
return ss
#绘制对比图形
All_plt = read_csv('bs1') #调用函数
China_plt = read_csv('China_top')
Japan_plt = read_csv('Japan_top')
Korea_plt = read_csv('Korea_top')
shu = list(range(1,101))
fig = plt.figure(dpi=128, figsize=(10, 6)) #设置图形界面
plt.subplot(2,1,1)
plt.bar(shu ,All_plt, align='center', color='green', label='World', alpha=0.6) #绘制条图形,align指定横坐标在中心,颜色,alpha指定透明度
plt.bar(shu ,China_plt, color='indigo', label='China', alpha=0.4) #绘制图形,颜色, label属性用于后面使用legend方法时显示图例标签
plt.bar(shu ,Japan_plt, color='blue', label='Japan',alpha=0.5) #绘制图形,颜色,
plt.bar(shu ,Korea_plt, color='yellow', label='Korea',alpha=0.5) #绘制图形,颜色,
plt.ylabel('评论数', fontsize=10) #纵坐标题目,字体大小
plt.title('不同地区的电影top100对比', fontsize=10) #图形标题
plt.legend(loc='best')
plt.subplot(2,1,2)
plt.plot(shu , All_plt, linewidth=1, c='green', label='World') #绘制图形,指定线宽,颜色,label属性用于后面使用legend方法时显示图例标签
plt.plot(shu ,China_plt, linewidth=1, c='indigo', label='China', ls='-.') #绘制图形,指定线宽,颜色,
plt.plot(shu ,Japan_plt, linewidth=1, c='green', label='Japan', ls='--') #绘制图形,指定线宽,颜色,
plt.plot(shu ,Korea_plt, linewidth=1, c='red', label='Korea', ls=':') #绘制图形,指定线宽,颜色,
plt.ylabel('comments', fontsize=10) #纵坐标题目,字体大小
plt.title('The different top 100 movies\'comments comparison', fontsize=10) #图形标题
plt.legend(loc='best')
'''
plt.legend()——loc参数选择
'best' : 0, #自动选择最好位置
'upper right' : 1,
'upper left' : 2,
'lower left' : 3,
'lower right' : 4,
'right' : 5,
'center left' : 6,
'center right' : 7,
'lower center' : 8,
'upper center' : 9,
'center' : 10,
'''
plt.savefig('C:\\Users\lenovo\Desktop\\bs1.png') #保存图片
plt.show() #显示图形
这里需要注意的是读取保存的csv文件并将数据传入列表时,每一个电影数据又是一个列表(先称为有效列表),每个有效列表前后都有一个空列表,所以需要将空列表删除,才能进行下一步
评分数据为string类型且有中文,所以进行遍历将中文去除并转换为int。
最后保存的对比分析图片:
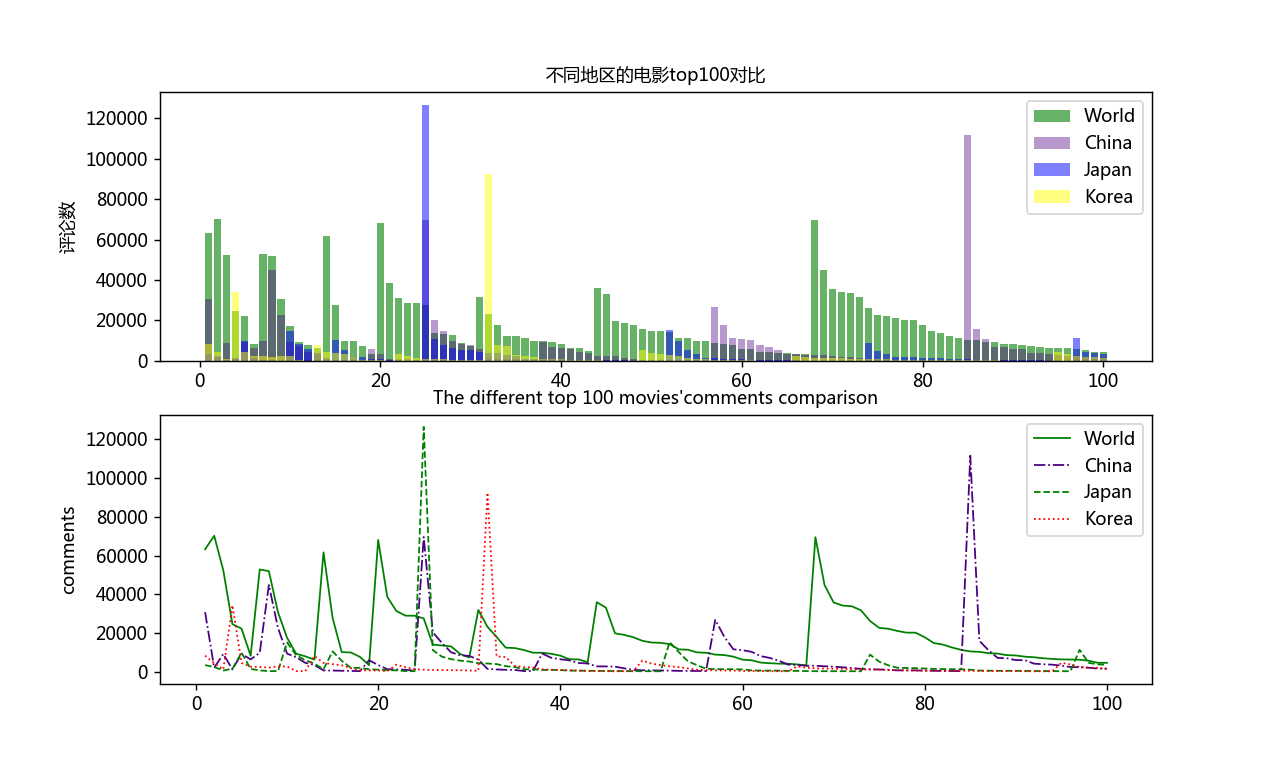
本次使用的爬取方法、爬取内容、分析内容都很容易,但我在完成过程中,发现自己还是会出现各种各样的问题,说明还有很多需要改善进步的地方。
同时欢迎大家指正。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持。
相关推荐
-
Python如何爬取实时变化的WebSocket数据的方法
一.前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据.股市实时数据或币圈实时变化的数据.如下图: Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSocket 这两种.轮询指的是客户端按照一定时间间隔(如 1 秒)访问服务端接口,从而达到 '实时' 的效果,虽然看起来数据像是实时更新的,但实际上它有一定的时间间隔,并不是真正的实时更新.轮询通常采用 拉 模式,由客户端主动从服务端拉取数据. WebSocket 采用的是 推 模式,由服务端主动将数
-

详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup爬取网页. 什么是Beautiful Soup Beautiful Soup是一款高效的Python网页解析分析工具,可以用于解析HTL和XML文件并从中提取数据. Beautiful Soup输入文件的默认编码是Unicode,输出文件的编码是UTF-8. Beautiful Soup具有将
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-
以视频爬取实例讲解Python爬虫神器Beautiful Soup用法
1.安装BeautifulSoup4 easy_install安装方式,easy_install需要提前安装 easy_install beautifulsoup4 pip安装方式,pip也需要提前安装.此外PyPi中还有一个名字是 BeautifulSoup 的包,那是 Beautiful Soup3 的发布版本.在这里不建议安装. pip install beautifulsoup4 Debain或ubuntu安装方式 apt-get install Python-bs4 你也可以通过源码安
-
Python3实现爬虫爬取赶集网列表功能【基于request和BeautifulSoup模块】
本文实例讲述了Python3实现爬虫爬取赶集网列表功能.分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站前面关于python3安装与配置相关文章. 首先需要安装request和BeautifulSoup两个模块 request是Python的HTTP网络请求模块,使用Requests可以轻而易举的完成浏览器可有的任何操作 pip insta
-
python使用BeautifulSoup与正则表达式爬取时光网不同地区top100电影并对比
前言 还有一年多就要毕业了,不准备考研的我要着手准备找实习及工作了,所以一直没有更新. 因为Python是自学不久,发现很久不用的话以前学过的很多方法就忘了,今天打算使用简单的BeautifulSoup和一点正则表达式的方法来爬一下top100电影,当然,我们并不仅是使用爬虫爬取数据,这样的话,数据中存在很多的对人有用的信息则被忽略了.所以,爬取数据只是开头,对这些数据根据意愿进行分析,或许能有额外的收获. 注:本人还是Python菜鸟,若有错误欢迎指正 本次我们爬取时光网(http://www
-
python正则表达式爬取猫眼电影top100
用正则表达式爬取猫眼电影top100,具体内容如下 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速导入此模块:鼠标先点到要导入的函数处,再Alt + Enter进行选择 from multiprocessing.pool import Pool #引入进程池 import requests import re import csv from requests.exceptions import RequestException
-
Python如何利用正则表达式爬取网页信息及图片
一.正则表达式是什么? 概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 个人理解: 简单来说就是使用正则表达式来写一个过滤器来过滤了掉杂乱的无用的信息(eg:网页源代码-)从中来获取自己想要的内容 二.实战项目 1.爬取内容 获取上海所有三甲医院的名称并保
-
python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下. 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外. 首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别.思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-
基于Python实现ComicReaper漫画自动爬取脚本过程解析
这篇文章主要介绍了基于Python实现ComicReaper漫画自动爬取脚本过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 讲真的, 手机看漫画翻页总是会手残碰到页面上的广告好吧... 要是能只需要指定一本漫画的主页URL就能给我返回整本漫画就好了... 这促使我产生了使用Python 3来实现, 做一个 ComicReaper(漫画收割者) 的想法! 本文所用漫画链接 : http://www.manhuadb.com/manhua/
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
Python3使用正则表达式爬取内涵段子示例
本文实例讲述了Python3使用正则表达式爬取内涵段子的方法.分享给大家供大家参考,具体如下: 似乎正则在爬虫中用的不是很广泛,但是也是基本功需要我们去掌握. 先将内涵段子网页爬取下来,之后利用正则进行匹配,匹配完成后将匹配的段子写入文本文档内.代码如下: # -*- coding:utf-8 -*- from urllib import request as urllib2 import re # 利用正则表达式爬取内涵段子 url = r'http://www.neihanpa.com/ar
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页