Python异步爬虫多线程与线程池示例详解
目录
- 背景
- 异步爬虫方式
- 多线程,多进程(不建议)
- 线程池,进程池(适当使用)
- 单线程+异步协程(推荐)
- 多线程
- 线程池
背景
当对多个url发送请求时,只有请求完第一个url才会接着请求第二个url(requests是一个阻塞的操作),存在等待的时间,这样效率是很低的。那我们能不能在发送请求等待的时候,为其单独开启进程或者线程,继续请求下一个url,执行并行请求
异步爬虫方式
多线程,多进程(不建议)
好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步会执行
弊端:不能无限制开启多线程或者多进程(需要频繁的创建或者销毁进程,线程)
线程池,进程池(适当使用)
好处:可以降低系统对进程或线程创建和销毁的频率,从而很好的而降低系统的开销
弊端:线程或进程池中的数量是有上限的
单线程+异步协程(推荐)
多线程
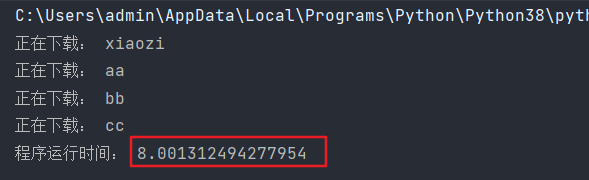
正常运行如下的代码,需要花费8秒钟的时间,因为sleep是一个阻塞的操作,在等待的时候不会执行别的操作,极大地降低了效率
from time import sleep
import time
start = time.time()
def xx(str):
print('正在下载:', str)
sleep(2)
str = ['xiaozi', 'aa', 'bb', 'cc']
for i in str:
xx(i)
end = time.time()
print('程序运行时间:',end-start)
使用多线程后
from threading import Thread
from time import sleep
import time
start = time.time()
def xx(str):
print('正在下载:',str)
sleep(2)
str = ['xiaozi','aa','bb','cc']
def main():
for s in str:
#开启线程,target=函数名,args=(xx,) ,xx为向函数传递的参数,必须为元组类型,所以后面需要加,
t = Thread(target=xx,args=(s,))
t.start()
if __name__ == '__main__':
main()
end = time.time()
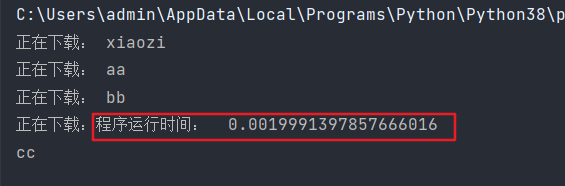
print('程序运行时间:',end-start)
但是我们发现下面的运行顺序貌似有点乱的
线程池
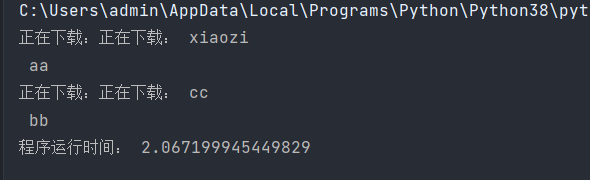
对上面的改为线程池后运行
#倒入线程池模块对应的类
from multiprocessing.dummy import Pool
from time import sleep
import time
start = time.time()
def xx(str):
print('正在下载:',str)
sleep(2)
str = ['xiaozi','aa','bb','cc']
#实例化一个线程池对象,线程池中开辟四个线程对象,并行4个线程处理四个阻塞操作
pool = Pool(4)
#将列表中的每一个列表元素(可迭代对象)传递给xx函数(发生阻塞的操作)进行处理
#map方法会有一个返回值为函数的返回值(一个列表),但是这里没有返回值所以不考虑
#调用map方法
pool.map(xx,str)
end = time.time()
print('程序运行时间:',end-start)
以上就是Python异步爬虫多线程与线程池示例详解的详细内容,更多关于Python异步多线程与线程池的资料请关注我们其它相关文章!
相关推荐
-

python爬虫之线程池和进程池功能与用法详解
本文实例讲述了python爬虫之线程池和进程池功能与用法.分享给大家供大家参考,具体如下: 一.需求 最近准备爬取某电商网站的数据,先不考虑代理.分布式,先说效率问题(当然你要是请求的太快就会被封掉,亲测,400个请求过去,服务器直接拒绝连接,心碎),步入正题.一般情况下小白的我们第一个想到的是for循环,这个可是单线程啊.那我们考虑for循环直接开他个5个线程,问题来了,如果有一个url请求还没有回来,后面的就干等,这么用多线程等于没用,到处贴创可贴. 二.性能考虑 确定要用多线程或者多进程了
-
python多进程和多线程究竟谁更快(详解)
python3.6 threading和multiprocessing 四核+三星250G-850-SSD 自从用多进程和多线程进行编程,一致没搞懂到底谁更快.网上很多都说python多进程更快,因为GIL(全局解释器锁).但是我在写代码的时候,测试时间却是多线程更快,所以这到底是怎么回事?最近再做分词工作,原来的代码速度太慢,想提速,所以来探求一下有效方法(文末有代码和效果图) 这里先来一张程序的结果图,说明线程和进程谁更快 一些定义 并行是指两个或者多个事件在同一时刻发生.并发是指两个或多个
-
Python多线程、异步+多进程爬虫实现代码
安装Tornado 省事点可以直接用grequests库,下面用的是tornado的异步client. 异步用到了tornado,根据官方文档的例子修改得到一个简单的异步爬虫类.可以参考下最新的文档学习下. pip install tornado 异步爬虫 #!/usr/bin/env python # -*- coding:utf-8 -*- import time from datetime import timedelta from tornado import httpclient, g
-
Python异步爬虫实现原理与知识总结
一.背景 默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢.因为需要一个url请求的完成,才能让下一个url继续访问.一种很自然的想法就是用异步机制来提高爬虫速度.通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时). import time #串形 def getPage(url): print("开始爬取网站",url) time.sleep(2)#阻塞 print("爬取完成
-
Python异步爬虫多线程与线程池示例详解
目录 背景 异步爬虫方式 多线程,多进程(不建议) 线程池,进程池(适当使用) 单线程+异步协程(推荐) 多线程 线程池 背景 当对多个url发送请求时,只有请求完第一个url才会接着请求第二个url(requests是一个阻塞的操作),存在等待的时间,这样效率是很低的.那我们能不能在发送请求等待的时候,为其单独开启进程或者线程,继续请求下一个url,执行并行请求 异步爬虫方式 多线程,多进程(不建议) 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步会执行 弊端:不能无限制开
-
java中常见的6种线程池示例详解
之前我们介绍了线程池的四种拒绝策略,了解了线程池参数的含义,那么今天我们来聊聊Java 中常见的几种线程池,以及在jdk7 加入的 ForkJoin 新型线程池 首先我们列出Java 中的六种线程池如下 线程池名称 描述 FixedThreadPool 核心线程数与最大线程数相同 SingleThreadExecutor 一个线程的线程池 CachedThreadPool 核心线程为0,最大线程数为Integer. MAX_VALUE ScheduledThreadPool 指定核心线程数的定时
-
Python 异步之非阻塞流使用示例详解
目录 1. 异步流 2. 如何打开连接 3. 如何启动服务器 4. 如何使用 StreamWriter 写入数据 5. 如何使用 StreamReader 读取数据 6. 如何关闭连接 1. 异步流 asyncio 的一个主要好处是能够使用非阻塞流. Asyncio 提供非阻塞 I/O 套接字编程.这是通过流提供的. 可以打开提供对流写入器和流写入器的访问的套接字.然后可以使用协同程序从流中写入和读取数据,并在适当的时候暂停.完成后,可以关闭套接字. 异步流功能是低级的,这意味着必须手动实现所需
-
java简单实现多线程及线程池实例详解
本文为大家分享了java多线程的简单实现及线程池实例,供大家参考,具体内容如下 一.多线程的两种实现方式 1.继承Thread类的多线程 /** * 继承Thread类的多线程简单实现 */ public class extThread extends Thread { public void run(){ for(int i=0;i<100;i++){ System.out.println(getName()+"-"+i); } } public static void mai
-
C#多线程之线程池ThreadPool详解
一.ThreadPool概述 提供一个线程池,该线程池可用于执行任务.发送工作项.处理异步 I/O.代表其他线程等待以及处理计时器. 创建线程需要时间.如果有不同的小任务要完成,就可以事先创建许多线程/在应完成这些任务时发出请求.不需要自己创建这样一个列表.该列表由ThreadPool类托管. 这个类会在需要时增减池中线程的线程数,直到最大的线程数.池中的最大线程数是可配置的.在双核CPU中,默认设置为1023 个工作线程和1000个I/O线程.也可以指定在创建线程池时应立即启动的最小线程数,以
-
Spring Boot之@Async异步线程池示例详解
目录 前言 一. Spring异步线程池的接口类 :TaskExecutor 二.简单使用说明 三.定义通用线程池 1.定义线程池 2.异步方法使用线程池 3.通过xml配置定义线程池 四.异常处理 五.问题 前言 很多业务场景需要使用异步去完成,比如:发送短信通知.要完成异步操作一般有两种: 1.消息队列MQ 2.线程池处理. 我们来看看Spring框架中如何去使用线程池来完成异步操作,以及分析背后的原理. 一. Spring异步线程池的接口类 :TaskExecutor 在Spring4中,
-
Python 使用threading+Queue实现线程池示例
一.线程池 1.为什么需要使用线程池 1.1 创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处理效率. 记创建线程消耗时间T1,执行任务消耗时间T2,销毁线程消耗时间T3,如果T1+T3>T2,那说明开启一个线程来执行这个任务太不划算了!在线程池缓存线程可用已有的闲置线程来执行新任务,避免了创建/销毁带来的系统开销. 1.2 线程并发数量过多,抢占系统资源从而导致阻塞. 线程能共享系统资源,如果同时执行的线程过多,就有可能导致系统资源不足而产生阻塞的情况. 1.3 对线
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-
Python定时器线程池原理详解
这篇文章主要介绍了Python定时器线程池原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 定时器执行循环任务: 知识储备 Timer(interval, function, args=None, kwargs=None) interval ===> 时间间隔 单位为s function ===> 定制执行的函数 使用threading的 Timer 类 start() 为通用的开始执行方法 cancel ()为取消执行的方法 普通单次