python归并排序算法过程实例讲解
关于python的算法一直都是让我们又爱又恨,但是如果可以灵活运用起来,对我们的编写代码过程,可以大大提高效率,针对算法之一“归并排序”的灵活掌握,一起来看下吧~
归并算法——小试牛刀
实例内容:
有 1 个无序列表如下:
list = [23,35,12,34,54,78,76,99]
要求:使其按从小到大排序
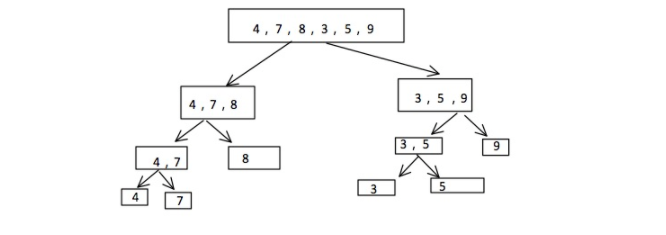
图示思路

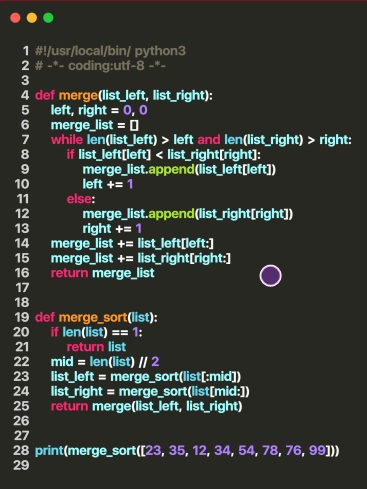
Python 代码
归并排序理解:
1.通过二分法把一个数组按照递归拆分为左右两组(至到独立元素为止)
2.按照从底层往高层的方法左右数组对比,同时对两个数组的第一个位置进行比大小,将小的放入一个空数组,然后被放入空数组的那个位置的指针往后移一个,然后继续和另外一个数组的上一个位置进行比较,以此类推。到最后任何一个数组先出栈完,就将另外i一个数组里的所有元素追加到新数组后面。
示例:
def merge(a, b): c = [] h = j = 0 while j < len(a) and h < len(b): if a[j] < b[h]: c.append(a[j]) j += 1 else: c.append(b[h]) h += 1 if j == len(a): for i in b[h:]: c.append(i) else: for i in a[j:]: c.append(i) return c def merge_sort(lists): if len(lists) <= 1: return lists middle = len(lists)/2 left = merge_sort(lists[:middle]) right = merge_sort(lists[middle:]) return merge(left, right) if __name__ == '__main__': = [4, 7, 8, 3, 5, 9] print merge_sort(a)
到此这篇关于python归并排序算法过程实例讲解的文章就介绍到这了,更多相关python归并排序算法过程图示详解内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现的插入排序,冒泡排序,快速排序,选择排序算法示例
本文实例讲述了Python实现的插入排序,冒泡排序,快速排序,选择排序算法.分享给大家供大家参考,具体如下: #!/usr/bin/python # coding:utf-8 #直接插入排序 def insert_sort(list): for i in range(len(list)): Key = list [i] #待插入元素 j = i - 1 while(Key < list[j] and j >= 0): list[j+1] = list[j] #后移元素 list[j] = Ke
-
python 常见的排序算法实现汇总
排序分为两类,比较类排序和非比较类排序,比较类排序通过比较来决定元素间的相对次序,其时间复杂度不能突破O(nlogn):非比较类排序可以突破基于比较排序的时间下界,缺点就是一般只能用于整型相关的数据类型,需要辅助的额外空间. 要求能够手写时间复杂度位O(nlogn)的排序算法:快速排序.归并排序.堆排序 1.冒泡排序 思想:相邻的两个数字进行比较,大的向下沉,最后一个元素是最大的.列表右边先有序. 时间复杂度$O(n^2)$,原地排序,稳定的 def bubble_sort(li:list):
-
10个python3常用排序算法详细说明与实例(快速排序,冒泡排序,桶排序,基数排序,堆排序,希尔排序,归并排序,计数排序)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法. Python3常用排序算法 1.Python3冒泡排序--交换类排序 冒泡排序(Bubble Sort)也是一种简单直观的排序算法. 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来. 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 作为最简单的排序算法
-

利用python实现冒泡排序算法实例代码
冒泡排序 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 冒泡排序算法的运作如下: 1.比较相邻的元素.如果第一个比第二个大(升序),就交换他们两个. 2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.这步做完后,最后的元素会是最大的数.
-
python常用排序算法的实现代码
这篇文章主要介绍了python常用排序算法的实现代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升. 1.插入排序 插入排序默认当前被插入的序列是有序的,新元素插入到应该插入的位置,使得新序列仍然有序. def insertion_sort(old_list): n=len(old_list) k=0 for i in range(1,n): temp=old_lis
-
python归并排序算法过程实例讲解
关于python的算法一直都是让我们又爱又恨,但是如果可以灵活运用起来,对我们的编写代码过程,可以大大提高效率,针对算法之一"归并排序"的灵活掌握,一起来看下吧~ 归并算法--小试牛刀 实例内容: 有 1 个无序列表如下: list = [23,35,12,34,54,78,76,99] 要求:使其按从小到大排序 图示思路 Python 代码 归并排序理解: 1.通过二分法把一个数组按照递归拆分为左右两组(至到独立元素为止) 2.按照从底层往高层的方法左右数组对比,同时对两个数组的第一
-
对python数据切割归并算法的实例讲解
当一个 .txt 文件的数据过于庞大,此时想要对数据进行排序就需要先将数据进行切割,然后通过归并排序,最终实现对整体数据的排序.要实现这个过程我们需要进行以下几步:获取总数据行数:根据行数按照自己的需要对数据进行切割:对每组数据进行排序 最后对所有数据进行归并排序. 下面我们就来实现这整个过程: 一:获取总数据的行 def get_file_lines(file_path): # 目标文件的路径 file_path = str(file_path) with open(file_path, 'r
-
python初学之用户登录的实现过程(实例讲解)
要求编写登录接口: 1. 输入用户名和密码 2.认证成功后显示欢迎信息 3.用户名输错,提示用户不存在,重新输入(5次错误,提示尝试次数过多,退出程序) 4.用户名正确,密码错误,提示密码错误,重新输入.(密码错误3次,锁定用户名并提示,退出程序) readme 应用知识点: 一.文件的操作 基本操作 f = open('lyrics','r',) #打开文件 first_line = f.readline() print('first line:',first_line) #读一行 data
-
python实现堆排序的实例讲解
堆排序 堆是一种完全二叉树(是除了最后一层,其它每一层都被完全填充,保持所有节点都向左对齐),首先需要知道概念:最大堆问题,最大堆就是根节点比子节点值都大,并且所有根节点都满足,那么称它为最大堆.反之最小堆. 当已有最大堆,如下图,首先将7提出,然后将堆中最后一个元素放到顶点上,此时这个堆不满足最大堆了,那么我们要给它构建成最大堆,需要找到此时堆中对打元素然后交换,此时最大值为6,符合最大堆后,我们将6提取出来,然后将堆中最后一个元素放到堆的顶部...以此类推.最后提取的数值7,6,5,4,3,
-
python搜索算法原理及实例讲解
一般我们在解决问题时候,经常能碰到好几种解决方式,总归是有最优,还有最不推荐的选择的,针对搜索算法也一样,因为能实现的方式也有很多个,因此,不知道大家在什么场景里使用这些算法,反正小编都把这些算法整理出来了,供大家选择,另外针对个人理解,大家也可以参考哪个更好使用哦~ 搜索算法 线性搜索 按一定的顺序检查数组中每一个元素,直到找到所要寻找的特定值为止.是最简单的一种搜索算法. 二分搜索算法 这种搜索算法每一次比较都使搜索范围缩小一半. 插值搜索算法 是根据要查找的关键字key与顺序表中最大.最小
-
用sleep间隔进行python反爬虫的实例讲解
在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到.有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容.我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦. 步骤 要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反爬虫机制. 获取网页内容,保存在一个字符串content中. 构造正则表达式,
-
python防止栈溢出的实例讲解
1.说明 使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出. 解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,所以,把循环看成是一种特殊的尾递归函数也是可以的. 2.实例 def fact(n): return fact_iter(n, 1) def fact_iter(num, product): if num == 1: return product return fact_iter(num - 1, num * product) # fact(5)
-
python之tensorflow手把手实例讲解斑马线识别实现
一,斑马线的数据集 数据集的构成: test train zebra corssing:56 zebra corssing:168 other:54 other:164 二,代码部分 1.导包 import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt import ker
-
Python 模拟购物车的实例讲解
1.功能简介 此程序模拟用户登陆商城后购买商品操作.可实现用户登陆.商品购买.历史消费记查询.余额和消费信息更新等功能.首次登陆输入初始账户资金,后续登陆则从文件获取上次消费后的余额,每次购买商品后会扣除相应金额并更新余额信息,退出时也会将余额和消费记录更新到文件以备后续查询. 2.实现方法 架构: 本程序采用python语言编写,将各项任务进行分解并定义对应的函数来处理,从而使程序结构清晰明了.主要编写了六个函数: (1)login(name,password) 用户登陆函数,实现用户名和密码
-
Python文件和流(实例讲解)
1.文件写入 #打开文件,路径不对会报错 f = open(r"C:\Users\jm\Desktop\pyfile.txt","w") f.write("Hello,world!\n") f.close() 2.文件读取 #读取 f = open(r"C:\Users\jm\Desktop\pyfile.txt","r") print(f.read()) f.close() 输出: Hello,world