Python Pandas读取Excel日期数据的异常处理方法
目录
- 异常描述
- 出现原因
- 解决方案:修改自定义格式
- pandas直接解析Excel数值为日期
- 总结
异常描述
有时我们的Excel有一个调整过自定义格式的日期字段:

当我们用pandas读取时却是这样的效果:

不管如何指定参数都无效。
出现原因
没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值。
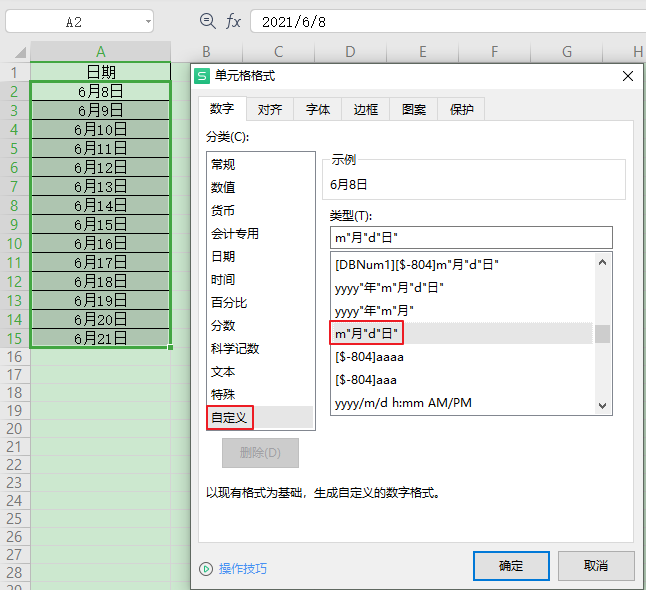
解决方案:修改自定义格式
可以修改为系统内置的自定义格式:

或者在自定义格式上补充负数的定义:
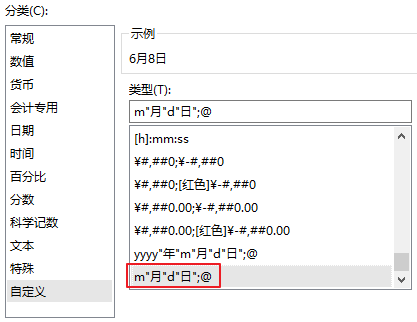
增加;@即可
pandas直接解析Excel数值为日期
有时这种Excel很多,我们需要通过pandas批量读取,挨个人工修改Excel的自定义格式费时费力,下面我演示如何使用pandas直接解析这些数值成为日期格式。
excel中常规格式和日期格式的转换规则如下:
1900/1/1为起始日期,转换的数字是1,往后的每一天增加1
1900/1/2转换为数字是 2
1900/1/3转换为数字是 3
1900/1/4转换为数字是 4
以此类推
excel中时间转换规则如下:
在时间中的规则是把1天转换为数字是 1
每1小时就是 1/24
每1分钟就是 1/(24×60)=1/1440
每1秒钟就是 1/(24×60×60)=1/86400
根据Excel的日期存储规则,我们只需要以1900/1/1为基准日期,根据数值n偏移n-1天即可得到实际日期。不过还有个问题,Excel多存储了1900年2月29日这一天,而正常的日历是没有这一天的,而我们的日期又都是大于1900年的,所以应该偏移n-2天,干脆使用1899年12月30日作为基准,这样不需要作减法操作。
解析代码如下:
import pandas as pd
from pandas.tseries.offsets import Day
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.apply(lambda x: f"{x.month}月{x.day}日")
df.head()
| 日期 | |
|---|---|
| 0 | 6月8日 |
| 1 | 6月9日 |
| 2 | 6月10日 |
| 3 | 6月11日 |
| 4 | 6月12日 |
如果需要调用time的strftime方法,由于包含中文则需要设置locale:
import pandas as pd
from pandas.tseries.offsets import Day
import locale
locale.setlocale(locale.LC_CTYPE, 'chinese')
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.dt.strftime('%Y年%m月%d日')
df.head()
| 日期 | |
|---|---|
| 0 | 2021年06月08日 |
| 1 | 2021年06月09日 |
| 2 | 2021年06月10日 |
| 3 | 2021年06月11日 |
| 4 | 2021年06月12日 |
总结
到此这篇关于Python Pandas读取Excel日期数据的异常处理的文章就介绍到这了,更多相关Pandas读取Excel日期数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用Pandas读写Excel实例解析
这篇文章主要介绍了Python使用Pandas读写Excel实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pandas是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. Pandas提供了大量能使我们快速便捷地处理数据的函数和方法. Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/ Pandas中文文档:https:/
-
python pandas写入excel文件的方法示例
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
Pandas读取并修改excel的示例代码
一.前言 最近总是和excel打交道,由于数据量较大,人工来修改某些数据可能会有点浪费时间,这时候就使用到了Python数据处理的神器-–Pandas库,话不多说,直接上Pandas. 二.安装 这次使用的python版本是python2.7,安装python可以去python的官网进行下载,这里不多说了. 安装完成后使用Python自带的包管理工具pip可以很快的安装pandas. pip install pandas 如果使用的是Anaconda安装的Python,会自带pandas. 三.
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python pandas如何向excel添加数据
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');
-

Python Pandas读取Excel日期数据的异常处理方法
目录 异常描述 出现原因 解决方案:修改自定义格式 pandas直接解析Excel数值为日期 总结 异常描述 有时我们的Excel有一个调整过自定义格式的日期字段: 当我们用pandas读取时却是这样的效果: 不管如何指定参数都无效. 出现原因 没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值. 解决方案:修改自定义格式 可以修改为系统内置的自定义格式: 或者在自定义格式上补充负数的定义: 增加;@即可 p
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
python+pandas+时间、日期以及时间序列处理方法
先简单的了解下日期和时间数据类型及工具 python标准库包含于日期(date)和时间(time)数据的数据类型,datetime.time以及calendar模块会被经常用到. datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差. 给datetime对象加上或减去一个或多个timedelta,会产生一个新的对象 from datetime import datetime from datetime import timedel
-
python pandas实现excel转为html格式的方法
如下所示: #!/usr/bin/env Python # coding=utf-8 import pandas as pd import codecs xd = pd.ExcelFile('/Users/wangxingfan/Desktop/1.xlsx') df = xd.parse() with codecs.open('/Users/wangxingfan/Desktop/1.html','w','utf-8') as html_file: html_file.write(df.to_
-
Python xlrd读取excel日期类型的2种方法
有个excle表格需要做一些过滤然后写入数据库中,但是日期类型的cell取出来是个数字,于是查询了下解决的办法. 基本的代码结构 复制代码 代码如下: data = xlrd.open_workbook(EXCEL_PATH) table = data.sheet_by_index(0) lines = table.nrows cols = table.ncols print u'The total line is %s, cols is %s'%(lines, cols) 读取某个单元
-
python+pandas生成指定日期和重采样的方法
python 日期的范围.频率.重采样以及频率转换 pandas有一整套的标准时间序列频率以及用于重采样.频率推断.生成固定频率日期范围的工具. 生成指定日期范围的范围 pandas.date_range()用于生成指定长度的DatatimeIndex: 1)默认情况下,date_range会按着时间间隔为天的方式生成从给定开始到结束时间的时间戳数组: 2)如果只指定开始或结束时间,还需要periods标定时间长度. import pandas as pd pd.date_range('2017
-
python在CMD界面读取excel所有数据的示例
代码 import xlrd import os from prettytable import PrettyTable import pandas #创建一个Excel表类 class Excel(object): def __init__(self, path): self.path = path //路径要加上文件名 #读取Excel内全部数据 参数sname是sheet页名字 def read_all_data(self, sname): workbook = xlrd.open_wor
-
Python matplotlib读取excel数据并用for循环画多个子图subplot操作
读取excel数据需要用到xlrd模块,在命令行运行下面命令进行安装 pip install xlrd 表格内容大致如下,有若干sheet,每个sheet记录了同一所学校的所有学生成绩,分为语文.数学.英语.综合.总分 考号 姓名 班级 学校 语文 数学 英语 综合 总分 ... ... ... ... 136 136 100 57 429 ... ... ... ... 128 106 70 54 358 ... ... ... ... 110.5 62 92 44 308.5 画多张子图需要
-
利用Python第三方库xlrd读取Excel中数据实例代码
目录 1. 安装 xlrd 库 2. 使用 xlrd 库 2.1 打开 Excel 工作表对象 2.2 读取单个单元格数据 2.3 读取多个单元格数据 2.3 读取所有单元格数据 附:行.列操作 3. 总结 1. 安装 xlrd 库 Python 读取 Excel 中的数据主要用到 xlrd 第三方库.xlrd 其实就是两个单词的简化拼接,我们可以把它拆开来看,xl 代表 excel, rd 代表 read, 合并起来就是 xlrd, 意思就是读 excel 的第三方库. 这种命名风格也正是我们