详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例。
编程工具:pycharm
app抓包工具:mitmproxy
app自动化工具:appium
运行环境:windows10
思路:
假设已经配置好我们所需要的工具
1、使用mitmproxy对手机app抓包获取我们想要的内容
2、利用appium自动化测试工具,驱动app模拟人的动作(滑动、点击等)
3、将1和2相结合达到自动化爬虫的效果
一、mitmproxy/mitmdump抓包
确保已经安装好了mitmproxy,并且手机和PC处于同一个局域网下,同时也配置好了mitmproxy的CA证书,网上有很多相关的配置教程,这里我就略过了。
因为mitmproxy不支持windows系统,所以这里用的是它的组件之一mitmdump,它是mitmproxy的命令行接口,可以利用它对接我们的Python脚本,用Python实现监听后的处理。
在配置好mitmproxy之后,在控制台上输入mitmdump并在手机上打开抖音app,mitmdump会呈现手机上的所有请求,如下图

可以在抖音app一直往下滑,看mitmdump所展示的请求,会发现前缀分别为
http://v1-dy.ixigua.com/;http://v3-dy.ixigua.com/;http://v9-dy.ixigua.com/
这3个类型前缀的url正是我们的目标抖音视频url。
那接下来就要编写python脚本将视频下载下来,需要使用 mitmdump -s scripts.py(此处为python文件名)来执行脚本。
import requests # 文件路径 path = 'D:/video/' num = 1788 def response(flow): global num # 经测试发现视频url前缀主要是3个 target_urls = ['http://v1-dy.ixigua.com/', 'http://v9-dy.ixigua.com/','http://v3-dy.ixigua.com/'] for url in target_urls: # 过滤掉不需要的url if flow.request.url.startswith(url): # 设置视频名 filename = path + str(num) + '.mp4' # 使用request获取视频url的内容 # stream=True作用是推迟下载响应体直到访问Response.content属性 res = requests.get(flow.request.url, stream=True) # 将视频写入文件夹 with open(filename, 'ab') as f: f.write(res.content) f.flush() print(filename + '下载完成') num += 1
代码写得比较粗糙,不过基本的逻辑还是比较清晰的,这样我们就可以把抖音的视频下载下来,不过这个方法有个缺陷,就是获取视频需要人来不断地滑动抖音的下一个视频,这时候我们可以用一个强大的appium自动化测试工具来解决。
二、Appium对手机进行模拟操作
确保已经配置好appium所依赖的环境Android和SDK,网上也有许多教程,这里我就不说了。
appium的用法很简单,首先我们先打开appium,启动界面如下

点击Start Server按钮即可启动appium服务

将Android手机通过数据线与PC相连,同时打开USE调试功能,可以输入adb命令(具体可以去网上查找)测试连接情况,若出现以下结果,则说明连接成功

model是设备名,后面配置需要用到。之后点击下图箭头所指的按钮就会出现一个配置页面
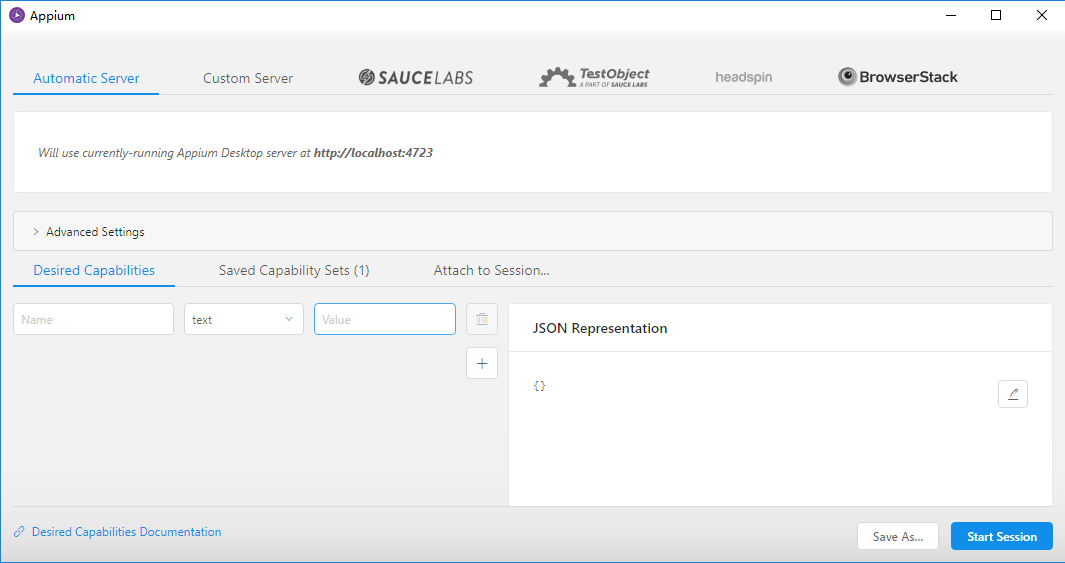
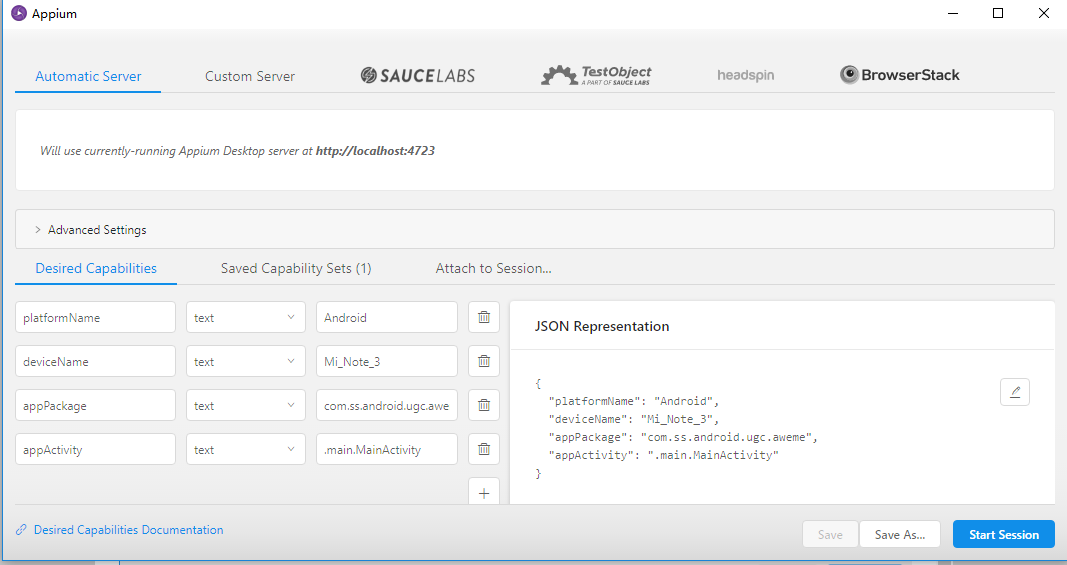
在右下角的JSON Representation配置启动app的Desired Capabilities参数,分别是paltformName、deviceName、appPackage、appActivity。
platformName:平台名称,一般是Android或iOS.
deviceName:设备名称,手机的具体类型
appPackage:App程序包名
appActivity:入口Activity名,通常以.开头
platformName和deviceName比较容易获得,而appPackage和appActivity这两个可以通过以下方法获取到。
在控制台上输入 adb logcat>D:\log.log 命令,并且在手机打开抖音app,然后在D盘中打开log.log文件,查找Displayed关键字
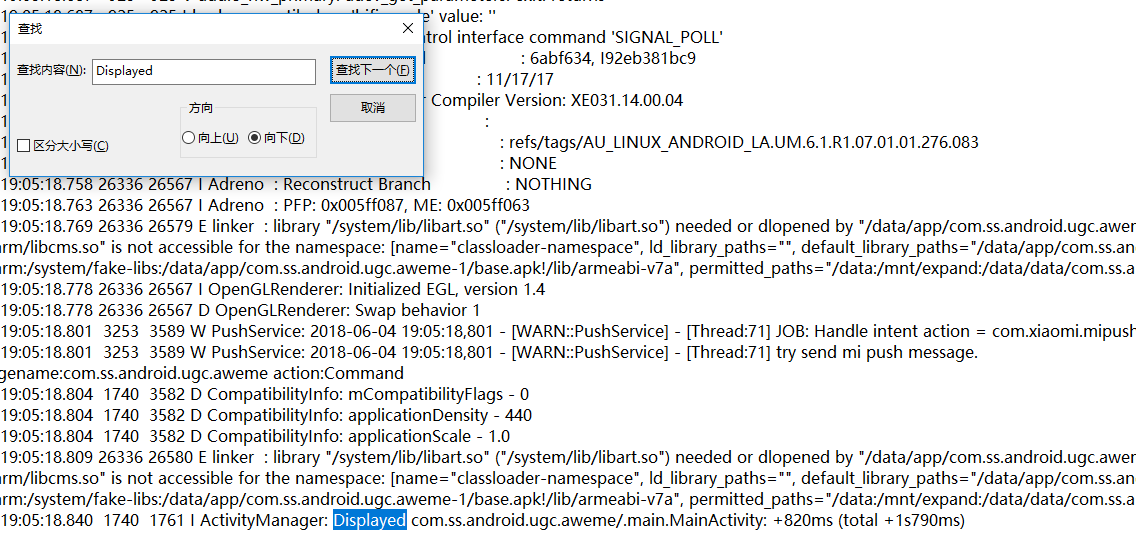
由上图可以知道Displayed后面的 com.ss.android.ugc.aweme对应的是appPackage,.main.MainActivity对应的是appActivity,最后我们的配置结果如下:
{
"platformName": "Android",
"deviceName": "Mi_Note_3",
"appPackage": "com.ss.android.ugc.aweme",
"appActivity": ".main.MainActivity"
}
再点击Start Session即可启动Android手机上的抖音app并进入到启动页面,同时PC上会弹出一个调试窗口,从这个窗口可以预览当前手机页面,还可以对手机模拟各种操作,在本文不是重点,所以略过。
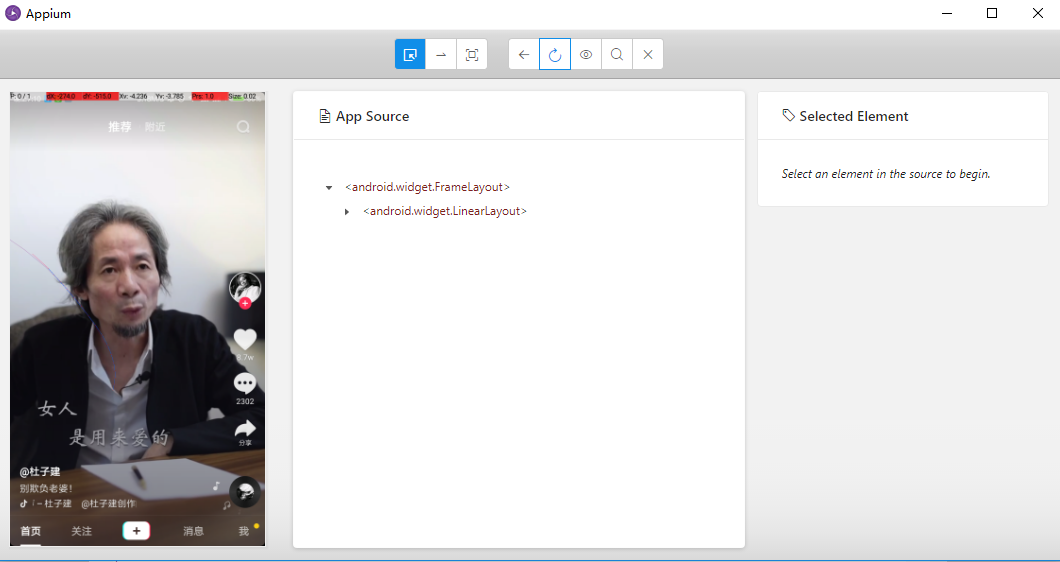
在下面我们将使用python脚本来驱动app,直接在pycharm运行即可
from appium import webdriver
from time import sleep
class Action():
def __init__(self):
# 初始化配置,设置Desired Capabilities参数
self.desired_caps = {
"platformName": "Android",
"deviceName": "Mi_Note_3",
"appPackage": "com.ss.android.ugc.aweme",
"appActivity": ".main.MainActivity"
}
# 指定Appium Server
self.server = 'http://localhost:4723/wd/hub'
# 新建一个Session
self.driver = webdriver.Remote(self.server, self.desired_caps)
# 设置滑动初始坐标和滑动距离
self.start_x = 500
self.start_y = 1500
self.distance = 1300
def comments(self):
sleep(2)
# app开启之后点击一次屏幕,确保页面的展示
self.driver.tap([(500, 1200)], 500)
def scroll(self):
# 无限滑动
while True:
# 模拟滑动
self.driver.swipe(self.start_x, self.start_y, self.start_x,
self.start_y-self.distance)
# 设置延时等待
sleep(2)
def main(self):
self.comments()
self.scroll()
if __name__ == '__main__':
action = Action()
action.main()
下面是爬虫的过程。ps:偶尔会爬取到重复的视频
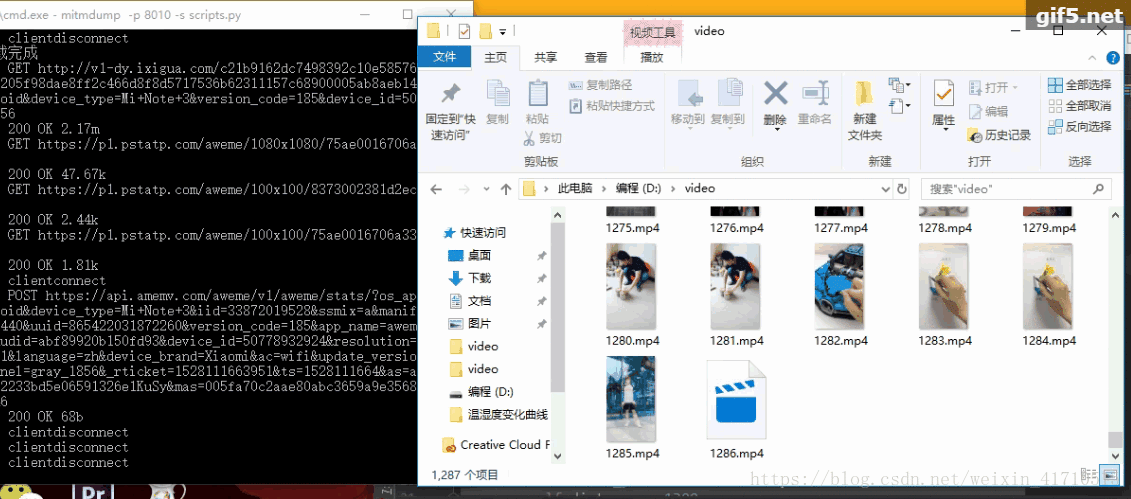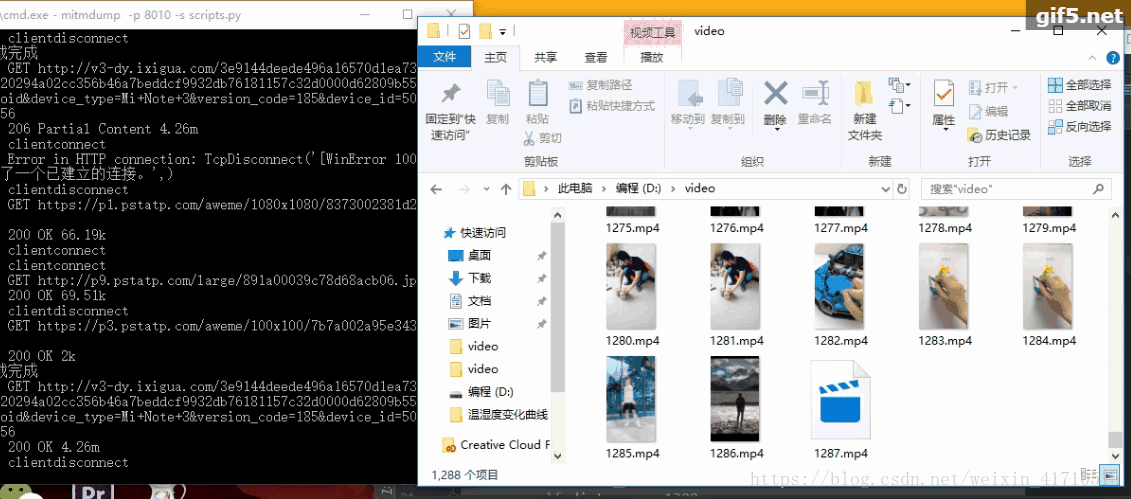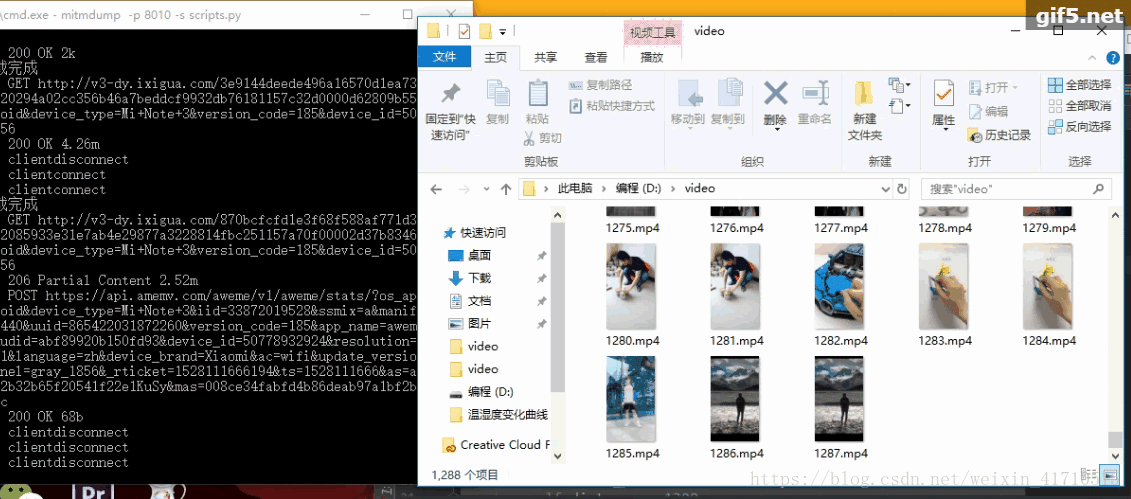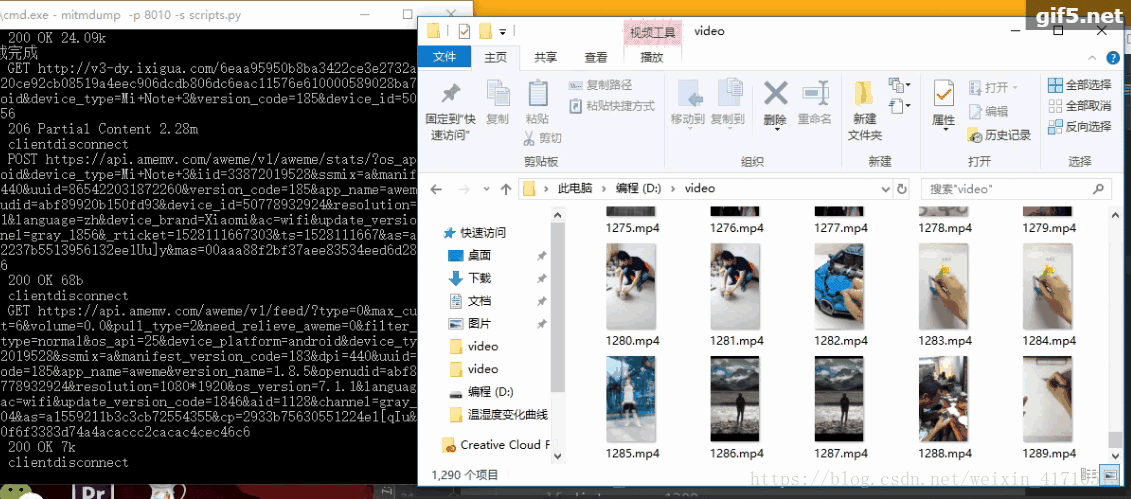
到此这篇关于详解使用python爬取抖音app视频(appium可以操控手机)的文章就介绍到这了,更多相关python爬取抖音app视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现模拟器爬取抖音评论数据的示例代码
目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记. 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 安装需要的工具: python3 下载 fiddle 安装及配置 手机模拟器下载 抖音部分: 模拟器下载好之后, 打开模拟器 在应用市场下载抖音 对抖音进行fiddle配置,配置成功后就可以当手机一样使用了 一.工具配置及抓包: 我们随便打开一个视频之后,fiddle就会刷新新的数据包 在json中
-
使用python爬取抖音app视频的实例代码
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
python爬取抖音视频的实例分析
现在抖音的火爆程度,大家都是有目共睹的吧,之前小编在网络上发现好玩的事情,就是去爬取一些网站,因此,也考虑能否进行抖音上的破案去,在实际操作以后,真的实现出来了,利用自动化工具,就可以轻松实现了,后有小伙伴提出把appium去掉瘦身之后也是可以实现的,那么看下详细操作内容吧. 1.mitmproxy/mitmdump抓包 import requests path = 'D:/video/' num = 1788 def response(flow): global num target_urls
-
Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
python批量爬取下载抖音视频
本文实例为大家分享了python批量爬取下载抖音视频的具体代码,供大家参考,具体内容如下 import os import requests import re import sys import asyncio import aiohttp headers = { 'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) ' 'Ve
-
使用python爬取抖音视频列表信息
如果看到特别感兴趣的抖音vlogger的视频,想全部dump下来,如何操作呢?下面介绍介绍如何使用python导出特定用户所有视频信息 抓包分析 Chrome Deveploer Tools Chrome 浏览器开发者工具 在抖音APP端,复制vlogger主页地址, 比如: http://v.douyin.com/kGcU4y/ , 在PC端用chrome浏览器打卡,并模拟手机,这里选择iPhone, 然后把复制的主页地址,放到浏览器进行访问,页面跳转到 https://www.iesdouy
-
详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
详解使用Selenium爬取豆瓣电影前100的爱情片相关信息
什么是Selenium Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome.Firefox.Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器. 1.准备工作 由于Selenium的环境配置过程比较繁琐,我会尽可能详细的对其进行讲解. 1.1 安装Selenium 由于Selenium的环境配置过程比较繁琐,我会多花一些篇幅对其进行讲解.可以在cmd命令框输入以下内容安装Selenium库. pip install Selenium 1.2 浏
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
Python爬取某平台短视频的方法
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 基本开发环境 Python 3.6 Pycharm 相关模块的使用 import os import requests 安装Python并添加到环境变量,pip安装需要的相关模块即可. 一.确定需求 爬取搞笑趣味栏目的视频内容. 二.网站数据分析 首先需要明确一点,好看视频网站加载方式是懒加载的方式,需要你下滑网页才会加载出新的内容 加载出来的内容里面有音频播放地址以及标题. 内容比较简单
-
Python爬取某拍短视频
一.抓取目标 目标网址:美拍视频 二.工具使用 开发环境:win10.python3.7 开发工具:pycharm.Chrome 工具包:requests.xpath.base64 三.重点学习内容 爬虫采集数据的解析过程 js代码调试技巧 js逆向解析代码 Python代码的转换 四.项目思路解析 进入到网站的首页 挑选你感兴趣的分类 根据首页地址获取到进入详情页面的超链接的跳转地址 找到对应加密的视频播放地址数据 这个数据是静态的网页数据,通过js代码进行解码的 找到对应的解析代码 先找到视