postgresql运维之远程迁移操作
背景:高可用架构版本。
主备分别部署在机器A和B上,现在要将其分别迁移到机器C和D上。
思路:
1、首先根据源实例的备份(云盘上可用snapshot),创建一个mirror实例,mirror包含两个节点,分别部署在C和D上。
2、在源实例主节点hba.conf中增加mirror主节点的ip的设置,允许源实例主节点接受来自mirror主节点的连接。
3、mirror实例主节点,创建recovery.conf文件,设置primary_conninfo指向源主节点。启动mirror主节点,建立源实例主到mirror实例主节点的复制关系。
4、在mirror实例主节点hba.conf中增加mirror备节点的ip。允许mirror主节点接受来自mirror备节点的连接。
5、mirror实例备节点,创建recovery.conf文件,设置primary_conn指向mirror实例主节点。启动备节点,建立mirror实例主节点到mirror实例备节点的复制关系。
6、提升mirror实例主节点为cluster master。
postgresql 备提升为主的方式:
pg_ctl方法:在备库主机执行pg_ctl promote shell脚本
触发器文件方式:备库配置recover.conf文件的trigger_file参数,之后在备库主机上创建触发器文件。
补充:Postgresql迁移数据文件存放位置
1. POSTGRESQL的安装
centos7 里面默认的pgsql的版本是 9.2.4 如果想用更高的版本需要执行以下如下的命令
rpm -ivh https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-centos11-11-2.noarch.rpm
安装成功后进行安装
yum install postgresql11 yum install postgresql11-server
然后启动并且设置为开机启动
systemctl enable postgresql-11 systemctl start postgresql-11
启动之后进行数据库初始化
11 以上的系统 还是比较简单的 直接执行
postgresql-setup initdb 就可以初始化数据库
设置密码等工作
su - postgres
登录数据库
psql -U postgres
修改密码
ALTER USER postgres WITH PASSWORD 'Test6530' 设置密码
\q退出数据库
2. 修改数据库使之能够被远程链接
数据库的配置文件默认为:
查看服务状态可得
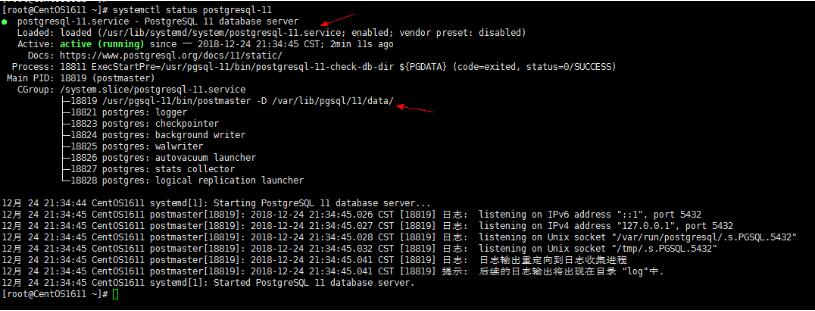
进入 data目录
/var/lib/pgsql/11/data/ /usr/lib/systemd/system/postgresql-11.service cd /var/lib/pgsql/11/data/
修改pg_hba.conf 即可
3. 创建新的数据目录
mkdir /home/pgdata
4.关闭pgsql
systemctl stop postgresql-11
5. 复制原来的文件
cp -R /var/lib/pgsql/11/data/* /home/pgdata
6.修改权限
chown -R postgres:postgres /home/pgdata chmod 750 /home/pgdata -R
7. 修改systemd 里面的配置文件
vim /usr/lib/systemd/system/postgresql-11.service
修改PGDATA的指向
8.执行命令重启
systemctl daemon-reload systemctl start postgresql-11
9. 删除原始PGDATA 里面的内容 重启虚拟机验证。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
postgreSQL数据库默认用户postgres常用命令分享
1.修改用户postgres的密码 #alter user postgres with password 'xxxx';(其中xxxx是修改的密码). 2.查看下当前schema的所有者: // 查看当前schema的所有者,相当于\du元命令 SELECT n.nspname AS "Name", pg_catalog.pg_get_userbyid(n.nspowner) AS "Owner" FROM pg_catalog.pg_namespace n WHE
-

解决postgresql无法远程访问的情况
今天刚入手这个数据库玩玩,发现无法通过IP去访问数据库,后面查询原因为,该数据库默认只能通过本地连接,也就是回环地址(127.0.0.1) 解决方案: 1.修改安装目录下的data\pg_hba.conf,在配置文件最后有IPV4和IPV6的配置,新增一行(这里我用的IPV4,开放所有IP) host all all 0.0.0.0/0 md5 说明: 该配置为允许所有IP访问,下面有对应的一些配置示例提供参考 32 -> 192.168.1.1/32 表示必须是来自这个IP地址的访问才合法:
-
PostgreSQL 启动失败的解决方案
环境 Red Hat CloudForms 4.x 问题 postgresql 启动失败,并导致evmserverd崩溃. [----] I, [2016-11-29T03:12:31.816753 #1201:e4f994] INFO -- : MIQ(PostgresAdmin.runcmd_with_logging) Running command... service rh-postgresql94-postgresql start [----] E, [2016-11-29T03:12
-
postgreSQL自动生成随机数值的实例
1. 随机生成身份证 新建一个函数,用来生成身份证号码,需要输入两个日期参数 create or replace function gen_id( a date, b date ) returns text as $$ select lpad((random()*99)::int::text, 2, '0') || lpad((random()*99)::int::text, 2, '0') || lpad((random()*99)::int::text, 2, '0') || to_char
-
关于PostgreSQL 行排序的实例解析
在查询生成输出表之后,也就是在处理完选择列表之后,你还可以对输出表进行排序. 如果没有排序,那么行将以不可预测的顺序返回(实际顺序将取决于扫描和连接规划类型和在磁盘上的顺序, 但是肯定不能依赖这些东西).确定的顺序只能在明确地使用了排序步骤之后才能保证. ORDER BY子句用于声明排序顺序: SELECT _select_list_ FROM _table_expression_ ORDER BY _sort_expression1_ [ASC | DESC] [NULLS { FIRST |
-
使用postgresql 模拟批量数据插入的案例
创建表: CREATE TABLE t_test( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL ); 模拟批量插入: insert into t_test SELECT generate_series(1,5000000) as key,repeat( chr(int4(random()*26)+65),4), (random()*(6^2))::
-
PostgreSQL的中文拼音排序案例
前一段时间开发人员咨询,说postgresql里面想根据一个字段做中文的拼音排序,但是不得其解 环境: OS:CentOS 6.3 DB:PostgreSQL 9.2.4 TABLE: tbl_kenyon 场景: postgres=# \d tbl_kenyon Table "public.tbl_kenyon" Column | Type | Modifiers --------+------+--------------- vname | text | --使用排序后的结果,不是
-
PostgreSQL中的template0和template1库使用实战
postgresql中默认会有三个数据库:postgres.template0.template1. postgres=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- postgres | postgres
-
postgresql运维之远程迁移操作
背景:高可用架构版本. 主备分别部署在机器A和B上,现在要将其分别迁移到机器C和D上. 思路: 1.首先根据源实例的备份(云盘上可用snapshot),创建一个mirror实例,mirror包含两个节点,分别部署在C和D上. 2.在源实例主节点hba.conf中增加mirror主节点的ip的设置,允许源实例主节点接受来自mirror主节点的连接. 3.mirror实例主节点,创建recovery.conf文件,设置primary_conninfo指向源主节点.启动mirror主节点,建立源实例主
-
Python自动化运维之Ansible定义主机与组规则操作详解
本文实例讲述了Python自动化运维之Ansible定义主机与组规则操作.分享给大家供大家参考,具体如下: 一 点睛 Ansible通过定义好的主机与组规则(Inventory)对匹配的目标主机进行远程操作,配置规则文件默认是/etc/ansible/hosts. 二 定义主机与组 所有定义的主机与组规则都在/etc/Ansible/hosts文件中,为ini文件格式,主机可以用域名.IP.别名进行标识,其中webservers.dbservers 为组名,紧跟着的主机为其成员.格式如下: ma
-
Python运维自动化之nginx配置文件对比操作示例
本文实例讲述了Python运维自动化之nginx配置文件对比操作.分享给大家供大家参考,具体如下: 文件差异对比diff.py #!/usr/bin/env python # import difflib import sys try: textfile1=sys.argv[1] textfile2=sys.argv[2] except exception,e: print "Error:"+str(2) print "Usge: difflib.py file1 file2
-
Python编写运维进程文件目录操作实用脚本示例
目录 1. 执行外部程序或命令 2. 文件和目录操作(命名.删除.拷贝.移动等) 3. 创建和解包归档文件 参考 Python在很大程度上可以对shell脚本进行替代.笔者一般单行命令用shell,复杂点的多行操作就直接用Python了.这篇文章就归纳一下Python的一些实用脚本操作. 1. 执行外部程序或命令 我们有以下C语言程序cal.c(已编译为.out文件),该程序负责输入两个命令行参数并打印它们的和.该程序需要用Python去调用C语言程序并检查程序是否正常返回(正常返回会返回 0)
-
运维的85条规则
1.容量第一,优化第二--这条规则在故障发生时生效.在宕机的时候别研究什么优化,先恢复设备. 2.保留所有可以捕获的记录--以 PostgresQL 为例,包括有 WAL 文件,Slony 复制,快照技术,基于硬盘的 DB 版本(快照附带的) 3.不要因为优化引入更多问题.通常我们解决问题时做出来的东西都会转变成之后运维工作的负担.请确认为运维工作开发的那些工具已经完全交付使用.这些东西经常无法正常运行结果要返回开发组重来.更重要的,这种变更请求通常会打破团队原本安排好的工作计划. 4.保持简单
-
深入浅析Linux轻量级自动运维工具-Ansible
转自 Linux轻量级自动运维工具-Ansible浅析 - ~微风~ - 51CTO技术博客 http://weiweidefeng.blog.51cto.com/1957995/1895261 Ansible是什么? ansible架构图 ansible特性 模块化:调用特定的模块,完成特定的任务: 基于Python语言研发,由Paramiko, PyYAML和Jinja2三个核心库实现: 部署简单:agentless: 支持自定义模块,使用任意编程语言: 强大的playbook机制: 幂等性
-
很实用的Linux 系统运维常用命令及常识(超实用)
作为Linux运维,需要了解Linux操作系统的基本使用和管理知识,下面我们小编给大家介绍下Linux运维需要掌握的命令,想成为Linux运维的朋友可以来学习一下. 1 文件管理2 软件管理3 系统管理 4 服务管理5 网络管理6 磁盘管理 7 用户管理8 脚本相关9 服务配置 ================================== ---------------------------------- 1 文件管理 ---------------------------------
-
linux 自动化运维工具ansible的使用详细教程
一.ansible简介 1.ansible ansible是新出现的自动化运维工具,基于Python研发.糅合了众多老牌运维工具的优点实现了批量操作系统配置.批量程序的部署.批量运行命令等功能.仅需在管理工作站上安装ansible程序配置被管控主机的IP信息,被管控的主机无客户端.ansible应用程序存在于epel(第三方社区)源,依赖于很多python组件.主要包括: (1).连接插件connection plugins:负责和被监控端实现通信: (2).host inventory:指定操
-
浅谈python之自动化运维(Paramiko)
简介 使用开源的Paramiko,我们就可以用Python代码中通过SSH协议对远程服务器执行操作,不需要手敲ssh命令,从而实现自动化运维. ssh是一个协议,OpenSSH是其中一个开源实现,paramiko库,实现了SSHv2协议(底层使用cryptography). 项目文档:点我跳转 扩展:ssh协议,OpenSSH 上手 1.安装 pip install paramiko 2.导入模块 import paramiko 3.使用 def initSshClinet(): ''' 初始化
-
10大HBase常见运维工具整理小结
摘要:HBase自带许多运维工具,为用户提供管理.分析.修复和调试功能.本文将列举一些常用HBase工具,开发人员和运维人员可以参考本文内容,利用这些工具对HBase进行日常管理和运维. HBase组件介绍 HBase作为当前比较热门和广泛使用的NoSQL数据库,由于本身设计架构和流程上比较复杂,对大数据经验较少的运维人员门槛较高,本文对当前HBase上已有的工具做一些介绍以及总结. 写在前面的说明: 1) 由于HBase不同版本间的差异性较大(如HBase2.x上移走了hbck工具),本文使用