java词法分析器DDL递归应用详解
目录
- 前言
- intellij plugin
- 词法解析
- 状态迁移
- DDL 解析
- 递归解析
- 总结
前言
最近大部分时间都在撸Python,其中也会涉及到将数据库表转换为Python中ORM框架的Model,但我们并没有找到一个合适的工具来做这个意义不大的”体力活“,所以每次新建表后大家都是根据自己的表结构手写一遍Model。
一两张表还好,一旦 10 几张表都要写一遍时那痛苦只有自己知道;这时程序员的 slogan 再次印证:一切毫无意义的体力劳动终将被计算机取代。
intellij plugin
既然没有现成的工具那就自己写一个吧,演示效果如下:

考虑到我们主要是用PyCharm开发,正好jetbrains也提供了SDK用于开发插件,所以UI层面可以不用额外考虑了。
使用流程很简单,只需要导入DDL语句就可以生成Python所需要的Model代码。
例如导入以下 DDL:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
便会生成对应的 Python 代码:
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
userName = db.Column(db.String) # 用户名
password = db.Column(db.String) # 密码
roleId = db.Column(db.Integer) # 角色ID
词法解析
仔细对比源文件及目标代码会很容易找出规律,无非就是解析出表名、字段、及字段的属性(是否为主键、类型、长度),最后再转换为Python所需要的模板即可。
在我动手之前我认为是非常简单的,无非就是解析字符串,但实际上手后发现不是那么回事;主要是有以下几个问题:
- 如何识别出表名称?
- 同样的如何识别出字段名称,同时还得关联上该字段的类型、长度、注释。
- 如何识别出主键?
总结一句话,如何通过一系列规则识别出一段字符串中的关键信息,这同样也是 MySQL Server 所做的事情。
在开始真正解析 DDL 之前,先来看下一段简单的脚本如何解析:
x = 20
按照我们平时开发的经验,这条语句分为以下几部分:
x表示变量=表示赋值符号20表示赋值结果
所以我们对这段脚本的解析结果应当为:
VAR x
GE =
VAL 100
这个解析过程在编译原理中称为”词法解析“,可能大家听到编译原理这几个字就头大(我也是);对于刚才那段脚本我们可以编写一个非常简单的词法解析器生成这样的结果。
状态迁移
再开始之前先捋一下思路,可以看到上文的结果中通过VAR表示变量、GE表示赋值符号 ”=“、VAL表示赋值结果,现在需要重点记住这三个状态。
在依次读取字符解析时,程序就是在这几个状态中来回切换,如下图:

- 默认为初始状态。
- 当字符为字母时进入
VAR状态。 - 当字符为 ”=“ 符号时进入
GE状态。
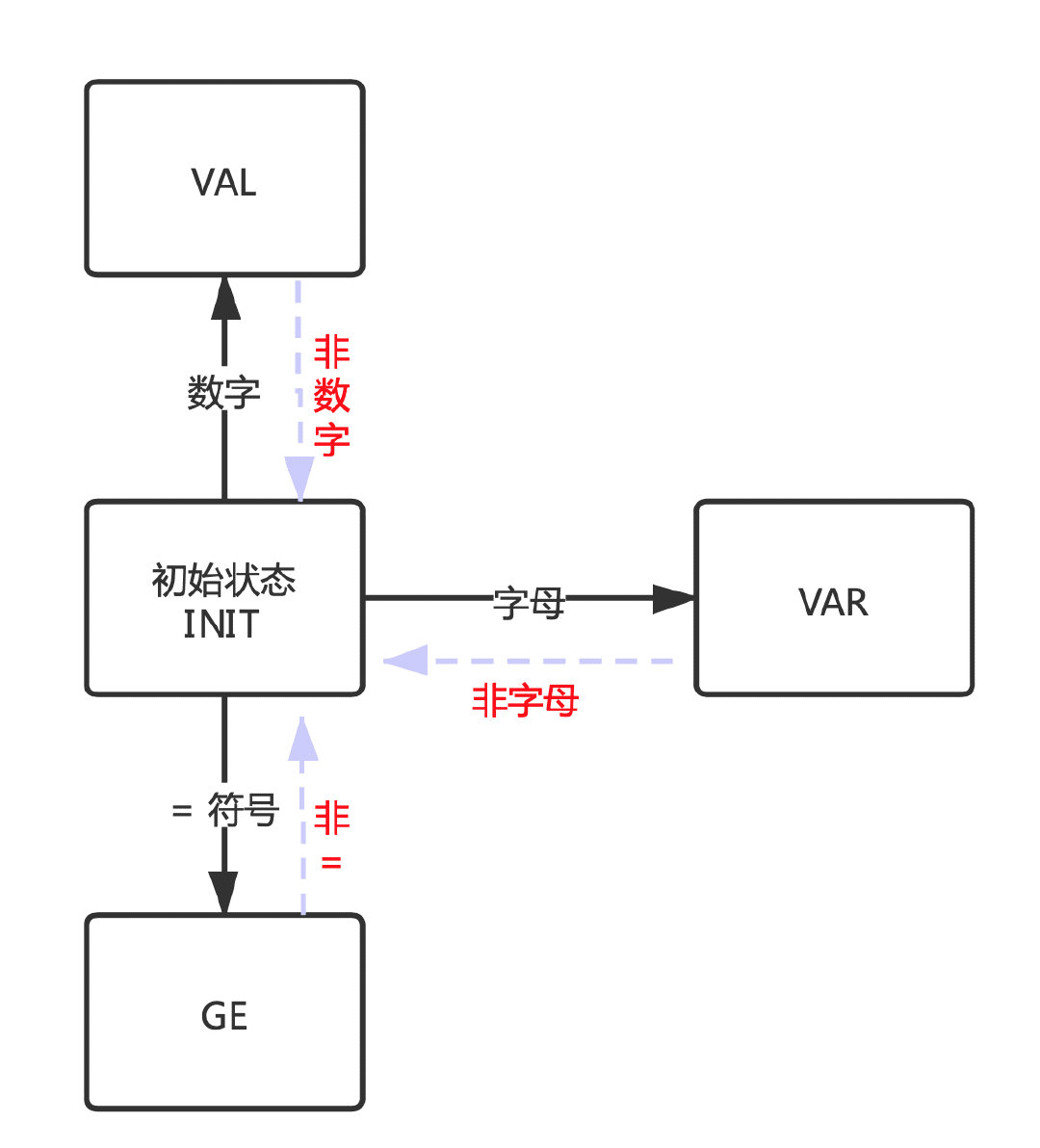
同理,当不满足这几个状态时候又会回到初始从而再次确认新的状态。
光看图有点抽象,直接来看核心代码:
public class Result{
public TokenType tokenType ;
public StringBuilder text = new StringBuilder();
}
首先定义了一个结果类,收集最终的解析结果;其中的TokenType就对应了图中的三种状态,简单的用枚举值来表示。
public enum TokenType {
INIT,
VAR,
GE,
VAL
}
首先对应到第一张图:初始化状态。
需要对当前解析的字符定义一个TokenType:

和图中描述的流程一致,判断当前字符给定一个状态即可。
接着对应到第二张图:状态之间的转换。

会根据不同的状态进入不同的case,在不同的case中判断是否应当跳转到其他状态(进入INIT状态后会重新生成状态)。
举个例子:x = 20:
首选会进入VAR状态,接着下一个字符为空格,自然在 38 行中重新进入初始状态,导致再次确定下一个字符=进入GE状态。
当脚本为ab = 30:
第一个字符为 a 也是进入VAR状态,第二个字符为 b,依然为字母,所以进入 36 行,状态不会改变,同时将 b 这个字符追加进来;后续步骤就和上一个例子一致了。
多说无益,建议大家自己跑一下单测就会明白:


DDL 解析
简单的解析完成后来看看DDL这样的脚本应当如何解析:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
原理类似,首先还是要看出规律(也就是语法):
- 表名是第一行语句,同时以
CREATE TABLE开头。 - 每一个字段的信息(名称、类型、长度、备注)都是以 “`” 符号开头 “,” 结尾。
- 主键是以 PRIMART 字符串开头的字段,以
)结尾。
根据我们需要解析的数据种类,我这里定义了这个枚举:

然后在初始化类型时进行判断赋值:

由于需要解析的数据不少,所以这里的判断条件自然也就多了。
递归解析
针对于DDL的语法规则,我们这里还有需要有特殊处理的地方;比如解析具体字段信息时如何关联起来?
举个例子:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
这里我们解析出来的数据得有一个映射关系:

所以我们只能一个字段的全部信息解析完成并且关联好之后才能解析下一个字段。
于是这里我采用了递归的方式进行解析(不一定是最好的,欢迎大家提出更优的方案)。
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}
当当前字符为 ”`“ 符号时,将状态置为 “FI”(FieldInfo),同时当解析到为 “,” 符号时便进入递归处理。

可以理解为将这一段字符串单独提取出来处理:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
接着再将这段字符递归调用当前方法再次进行解析,这时便按照字段名称、类型、长度、注释的规则解析即可。
同时既然存在递归,还需要将子递归的数据关联起来,所以我在返回结果中新增了一个pid的字段,这个也容易理解。
默认值为 0,一旦递归后便自增 +1,保证每次递归的数据都是唯一的。
用同样的方法在解析主键时也是先将整个字符串提取出来:
PRIMARY KEY (`id`)
只不过是 “P” 打头 “)” 结尾。
} else if (value == 'P' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.P_K;
result.text.append(value);
}

也是将整段字符串递归解析,再递归的过程中进行状态切换P_K ---> P_K_V最终获取到主键。

所以通过对刚才那段DDL解析得到的结果如下:
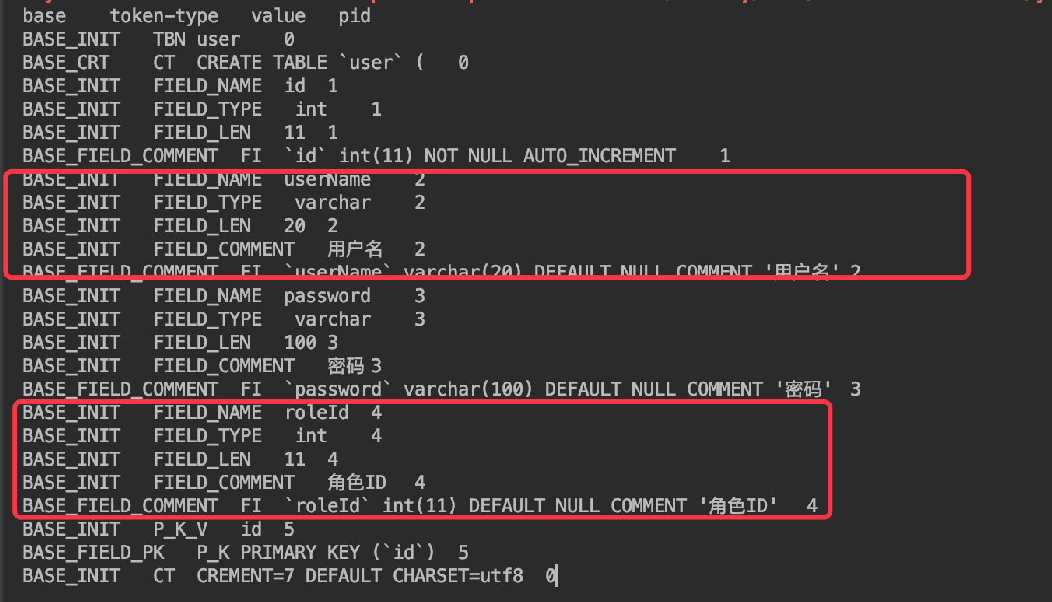
这样每个字段也通过了pid进行了区分关联。
所以现在只需要对这个词法解析器进行封装,便可以提供一个简单的API来获取表中的数据了。

总结
到此整个词法解析器的全部内容都已经完成了,虽然实现的是一个小功能,但我自己花的时间可不少,其中光复习编译原理就让人头疼。
但这还只是整个编译语言知识点的冰山一角,后续还有语法、语义、中间、目标代码等一系列内容,都是一个比一个难啃。
本文所有源码及插件地址:
https://github.com/crossoverJie/sqlalchemy-transfer
以上就是java词法分析器DDL递归应用详解的详细内容,更多关于java DDL递归词法分析器的资料请关注我们其它相关文章!
相关推荐
-

JAVA递归生成树形菜单的实现过程
递归生成一个如图的菜单,编写两个类数据模型Menu.和创建树形的MenuTree.通过以下过程实现: 1.首先从菜单数据中获取所有根节点. 2.为根节点建立次级子树并拼接上. 3.递归为子节点建立次级子树并接上,直至为末端节点拼接上空的“树”. 首先,编写数据模型Menu.每条菜单有自己的id.父节点parentId.菜单名称text.菜单还拥有次级菜单children. import java.util.List; public class Menu { private String id;
-
使用Java将一个List运用递归转成树形结构案例
在开发中,我们会遇到将不同组织架构合并成tree这种树状结构,那么如果做呢? 实际上,我们也可以理解为如何将拥有父子关系的list转成树形结构,而这其中主要的方法就是递归! 1.实体对象: @Data public class Node { private Integer id; private String city; private Integer pid; private List<Node> children; public Node(Integer id,String city,In
-
Java的递归算法详解
目录 一.介绍 1.介绍 2.案例 二.迷宫问题 三.八皇后问题 四.汉诺塔问题 1.问题 2.思想 3.代码 总结 一.介绍 1.介绍 递归:递归就是方法自己调用自己,每次调用时传入不同的变量.递归有助于编程者解决复杂的问题,同时可以让代码变得简洁. 迭代和递归区别:迭代使用的是循环结构,递归使用的选择结构.使用递归能使程序的结构更清晰.更简洁.更容易让人理解,从而减少读懂代码的时间.其时间复杂度就是递归的次数. 但大量的递归调用会建立函数的副本,会消耗大量的时间和内存,而迭代则不需要此种付出
-
Java 递归查询部门树形结构数据的实践
说明:在开发中,我们经常使用树形结构来展示菜单选项,如图: 那么我们在后端怎么去实现这样的一个功能呢? 1.数据库表:department 2.编写sql映射语句 <select id="selectDepartmentTrees" resultType="com.welb.entity.Department"> select * from department <where> <if test="updepartmentco
-
利用Java实现简单的词法分析器实例代码
首先看下我们要分析的代码段如下: 输出结果如下: 输出结果(a).PNG 输出结果(b).PNG 输出结果(c).PNG 括号里是一个二元式:(单词类别编码,单词位置编号) 代码如下: package Yue.LexicalAnalyzer; import java.io.*; /* * 主程序 */ public class Main { public static void main(String[] args) throws IOException { Lexer lexer = new
-
Java递归实现菜单树的方法详解
pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0
-
java词法分析器DDL递归应用详解
目录 前言 intellij plugin 词法解析 状态迁移 DDL 解析 递归解析 总结 前言 最近大部分时间都在撸Python,其中也会涉及到将数据库表转换为Python中ORM框架的Model,但我们并没有找到一个合适的工具来做这个意义不大的”体力活“,所以每次新建表后大家都是根据自己的表结构手写一遍Model. 一两张表还好,一旦 10 几张表都要写一遍时那痛苦只有自己知道:这时程序员的 slogan 再次印证:一切毫无意义的体力劳动终将被计算机取代. intellij plugin
-
java 实现单链表逆转详解及实例代码
java 实现单链表逆转详解 实例代码: class Node { Node next; String name; public Node(String name) { this.name = name; } /** * 打印结点 */ public void show() { Node temp = this; do { System.out.print(temp + "->"); temp = temp.next; }while(temp != null); System.o
-
java 实现汉诺塔详解及实现代码
java 实现汉诺塔详解及实现代码 汉诺塔问题:有三根柱子A,B,C,其中A上面有n个圆盘,从上至下圆盘逐渐增大,每次只能移动一个圆盘,并且规定大的圆盘不能叠放在小的圆盘上面,现在想要把A上面的n个圆盘全部都移动到C上面,输出移动的总步数以及移动的过程 分析: //先求出移动的总步数 1,假设g(n)表示n个圆盘时的移动总的步数,当n=1时,g(1)=1; 2.现在可以把g(n)进行细分为三步: 1>先将n-1个圆盘从A通过C移动到B上面,相当于将n-1个圆盘从A移动到C,因此需要g(n-1)步
-
Java编程复用类代码详解
本文研究的主要是Java编程中的复用类,那么到底复用类是什么东西,又有什么用法,下面具体介绍. 看了老罗罗升阳的专访,情不自禁地佩服,很年轻,我之前以为和罗永浩一个级别的年龄,也是见过的不是初高中编程的一位大牛之一,专访之后,发现老罗也是一步一个脚印的人.别说什么难做,做不了,你根本就没去尝试,也没有去坚持. If you can't fly then run,if you can't run then walk, if you can't walk then crawl,but whateve
-
Java 中Flyway的使用详解
Flyway的使用 环境:SpringBoot 2.0.4.RELEASE 为什么要用Flyway? 开发人员在合作的时候经常遇到以下场景: 1.开发人员A在自己的本地数据库做了一些表结构的改动,并根据这些改动调整了DAO层的代码,然后将代码上传到svn或git等版本控制服务器上.此时如果开发人员B拉取了A的代码改动,在运行项目的时候很可能会报错,因为B的本地SQL数据库并没有修改. 2.在项目上线的时候,当服务器拉取的版本控制服务器的最新修改后,必须同时运行SQL数据库的修改脚本,如果忘了跑数
-
Java基础之代码死循环详解
一.前言 代码死循环这个话题,个人觉得还是挺有趣的.因为只要是开发人员,必定会踩过这个坑.如果真的没踩过,只能说明你代码写少了,或者是真正的大神. 尽管很多时候,我们在极力避免这类问题的发生,但很多时候,死循环却悄咪咪的来了,坑你于无形之中.我敢保证,如果你读完这篇文章,一定会对代码死循环有一些新的认识,学到一些非常实用的经验,少走一些弯路. 二.死循环的危害 我们先来一起了解一下,代码死循环到底有哪些危害? 程序进入假死状态, 当某个请求导致的死循环,该请求将会在很大的一段时间内,都无法获取接
-
Java源码解析之详解ReentrantLock
ReentrantLock ReentrantLock是一种可重入的互斥锁,它的行为和作用与关键字synchronized有些类似,在并发场景下可以让多个线程按照一定的顺序访问同一资源.相比synchronized,ReentrantLock多了可扩展的能力,比如我们可以创建一个名为MyReentrantLock的类继承ReentrantLock,并重写部分方法使其更加高效. 当一个线程调用ReentrantLock.lock()方法时,如果ReentrantLock没有被其他线程持有,且不存在
-
Java 逻辑结构与方法函数详解刨析
⭐前言⭐ 本文主要介绍JavaSE的逻辑结构和方法. 对一门编程语言逻辑结构和方法的理解是站在C语言之上的,建议配套C语言版本的分析一起食用 链接直达:
-
Java数据结构之线段树详解
目录 介绍 代码实现 线段树构建 区间查询 更新 总结 介绍 线段树(又名区间树)也是一种二叉树,每个节点的值等于左右孩子节点值的和,线段树示例图如下 以求和为例,根节点表示区间0-5的和,左孩子表示区间0-2的和,右孩子表示区间3-5的和,依次类推. 代码实现 /** * 使用数组实现线段树 */ public class SegmentTree<E> { private Node[] data; private int size; private Merger<E> merge
-
java 数据结构并查集详解
目录 一.概述 二.实现 2.1 Quick Find实现 2.2 Quick Union实现 三.优化 3.1基于size的优化 3.2基于rank优化 3.2.1路径压缩(Path Compression ) 3.2.2路径分裂(Path Spliting) 3.2.3路径减半(Path Halving) 一.概述 并查集:一种树型数据结构,用于解决一些不相交集合的合并及查询问题.例如:有n个村庄,查询2个村庄之间是否有连接的路,连接2个村庄 两大核心: 查找 (Find) : 查找元素所在