Python groupby函数图文详解
一、分组原理
核心:
1、不论分组键是数组、列表、字典、Series、函数,只要其与待分组变量的轴长度一致都可以传入groupby进行分组。
2、默认axis=0按行分组,可指定axis=1对列分组。
groupby()语法格式
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, group_keys=True, squeeze=False, observed=False, **kwargs)
groupby原理
groupby就是按XX分组,比如将一个数据集按A进行分组,效果如下
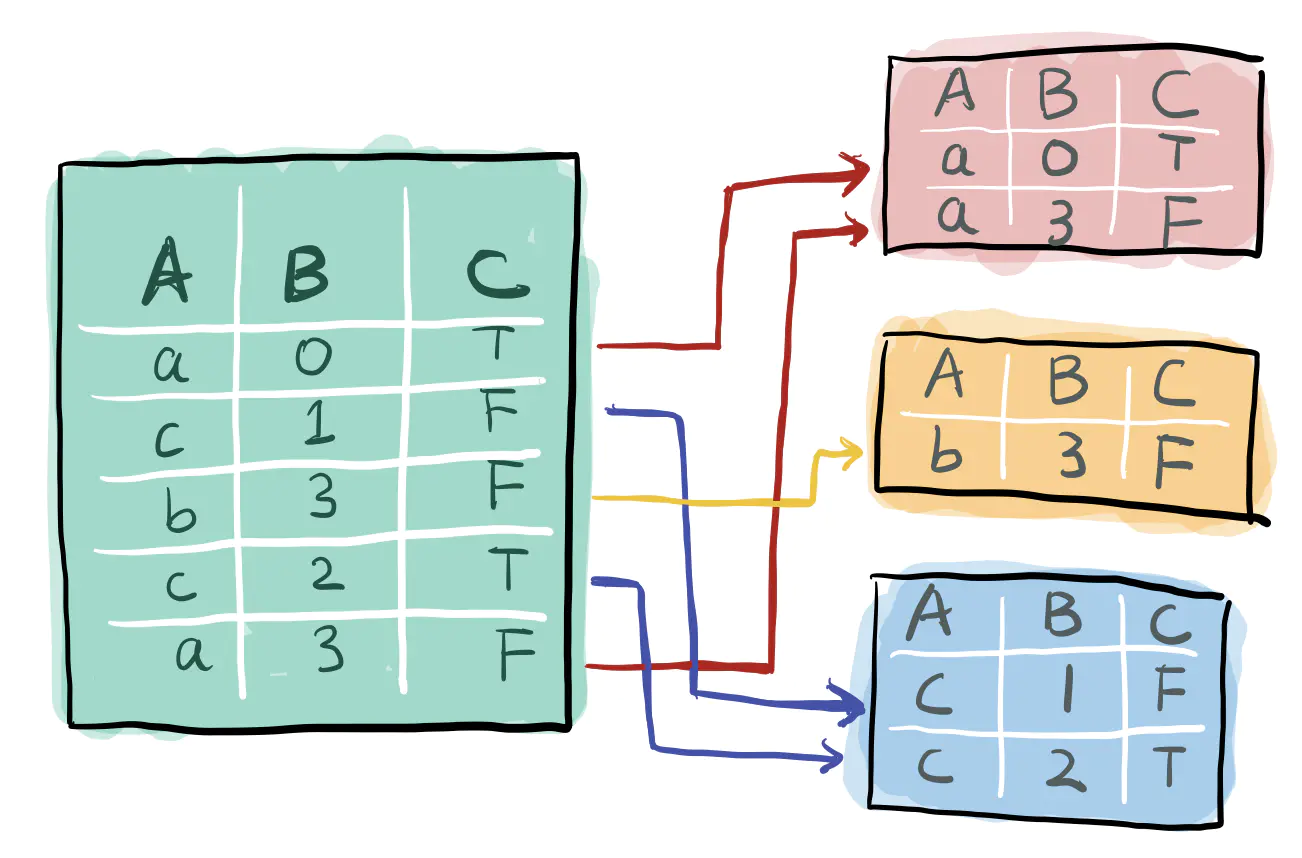
使用groupby实现功能
import numpy as np
import pandas as pd
data = pd.DataFrame({
'name': ['Tom', 'Kaggle', 'Litter', 'Sam', 'Sam', 'Sam'],
'race': ['B', 'C', 'D', 'E', 'B', 'C'],
'age': [37.0, 61.0, 56.0, 87.0, 58.0, 34.0],
'signs_of_mental_illness': [True, True, False, False, False, False]
})
data.groupby('race')

返回结果如上 得到一个叫DataFrameGroupBy的东西,pandas不能直接显示出来 可以调用list显示出来

groupby()的配合函数 函数 适用场景备注.mean()均值.count()计数.min()最小值.mean().unstack()求均值,聚合表的层次索引不堆叠.size()计算分组大小GroupBy的size方法,将返回一个含有分组大小的Series.apply().agg()
这里演示.mean()和.count()
# mean()
data.groupby('name')['age'].mean()
# count()
data.groupby('name')['age'].count()
data.groupby('age').count()
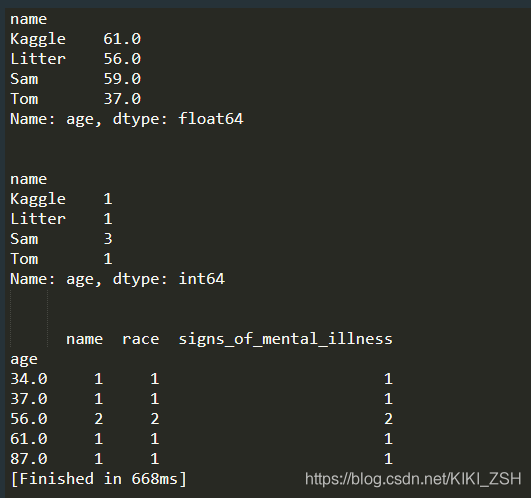
也可以根据单键多列进行聚合
# 单键多列聚合
data.groupby('name')[['race','age',]].count()

.agg操作 可以取多个函数进行选择 有时候我们既需要平均值,有需要计数(也可是取一个)
agg为列表
print(data.groupby('name')['age'].agg(['mean']))
print(data.groupby('name')['age'].agg(['mean','count']))

也可以传入字典,对组内不同列采取不同的操作
print(data.groupby('race').agg({'age': np.median, 'signs_of_mental_illness': np.mean}))
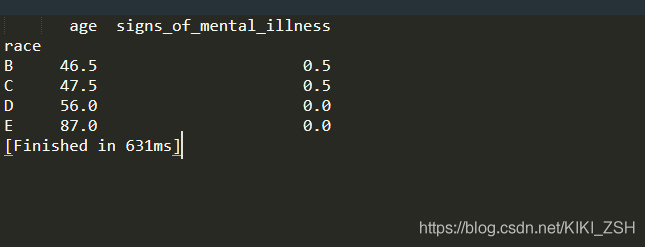
.apply()
可以使用我们自己所创建的函数
print('apply之前')
grouped = data.groupby('name')
for name, group in grouped:
print(name)
print(group)
print('\n')
print('apply之后')
print(data.groupby('name').apply(lambda x: x.head(2)))

简单操作基本介绍完成
有时候需要将聚合的另一列放到一起 并且取消键的重复值 这个时候可以这样做
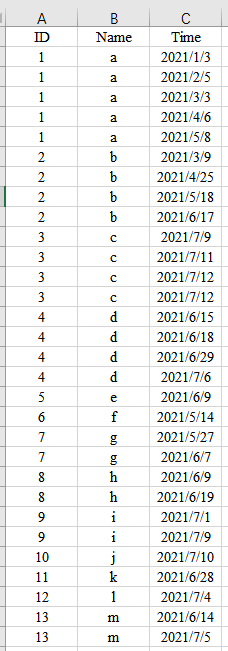
上面是构建的数据,需要对订购时间进行处理,这里我们是将月份+天数/30,然后对ID列进行去重,并将后面Time列计算的结果放到一起
import numpy as np
import pandas as pd
data = pd.read_excel('订购时间预测2.xlsx')
def cut_m_d(x):
return round(x.month + x.day / 30, 2)
data['m_d'] = data['Time'].apply(cut_m_d)
grouped = data.groupby('ID')
# 这一步是去重(ID),不去重会出现错误
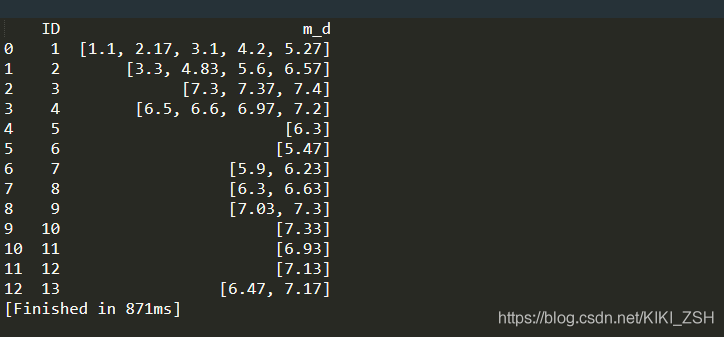
result = grouped['m_d'].unique()
result2 = result.reset_index()
print(result2)
总结
到此这篇关于Python groupby函数详解的文章就介绍到这了,更多相关groupby函数详解内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Python中的分组函数groupby和itertools)
具体代码如下所示: from operator import itemgetter #itemgetter用来去dict中的key,省去了使用lambda函数 from itertools import groupby #itertool还包含有其他很多函数,比如将多个list联合起来.. d1={'name':'zhangsan','age':20,'country':'China'} d2={'name':'wangwu','age':19,'country':'USA'} d3={'nam
-
python中分组函数groupby和分组运算函数agg的使用
目录 groupby: agg: 今天来介绍pandas中一个很有用的函数groupby,其实和hive中的groupby的效果是一样的,区别在于两种语言的写法问题.groupby在Python中的分组统计中很有用~ groupby: 首先创建数据: import pandas as pd import numpy as np df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'], 'B': [2, 7, 1, 3, 3
-
Python DataFrame.groupby()聚合函数,分组级运算
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个键(可以是函数.数组或DataFrame列名)拆分pandas对象.计算分组摘要统计,如计数.平均值.标准差,或用户自定义函数.对DataFrame的列应用各种各样的函数.应用组内转换或其他运算,如规格化.线性回归.排名或选取子集等.计算透视表或交叉表.执行分位数分析以及其他分组分析. groupby分组函数: 返回值:返回重构格式的DataFrame,特别注意,grou
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
-
python groupby 函数 as_index详解
在官方网站中对as_index有以下介绍: as_index : boolean, default True For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively "SQL-style" grouped output 翻译过来就是说as_index 的默认值为True, 对于
-

python DataFrame数据分组统计groupby()函数的使用
目录 groupby()函数 1. groupby基本用法 1.1 一级分类_分组求和 1.2 二级分类_分组求和 1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算) 2. 对分组数据进行迭代 2.1 对一级分类的DataFrameGroupBy对象进行遍历 2.2 对二级分类的DataFrameGroupBy对象进行遍历 3. agg()函数 3.1一般写法_对目标数据使用同一聚合函数 3.2 对不同列使用不同聚合函数 3.3 自定义函数写法 4. 通过 字典 和 Se
-
python groupby函数实现分组后选取最值
现在需要将course分组,然后选择出每一组里面的最大值和最小值,并保留下来 实现下面数据结果: 直接使用groupby函数,不能直接达到此效果,需要在groupby函数上添加apply和lambda函数 代码如下: import pandas as pd data = pd.read_excel('group_apply.xlsx') data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min())
-
Python groupby函数图文详解
一.分组原理 核心: 1.不论分组键是数组.列表.字典.Series.函数,只要其与待分组变量的轴长度一致都可以传入groupby进行分组. 2.默认axis=0按行分组,可指定axis=1对列分组. groupby()语法格式 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, group_keys=True, squeeze=False, observed=False, **kwargs) groupby原理 group
-
python isinstance函数用法详解
这篇文章主要介绍了python isinstance函数用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 isinstance() 函数来判断一个对象是否是一个已知的类型类似 type(). isinstance() 与 type() 区别: type() 不会认为子类是一种父类类型,不考虑继承关系. isinstance() 会认为子类是一种父类类型,考虑继承关系. 如果要判断两个类型是否相同推荐使用 isinstance(). 语法
-
Python ord函数()案例详解
python中ord函数 Python ord()函数 (Python ord() function) ord() function is a library function in Python, it is used to get number value from given character value, it accepts a character and returns an integer i.e. it is used to convert a character to an
-
Python的函数使用详解
目录 前言 1 跳出循环-break 2 python函数 2.1 内置函数 2.2 自定义函数 2.3 main函数 前言 在两种python循环语句的使用中,不仅仅是循环条件达到才能跳出循环体.所以,在对python函数进行阐述之前,先对跳出循环的简单语句块进行介绍. 1 跳出循环-break python提供了一种方便快捷的跳出循环的方法-break,示例如下,计算未知数字个数的总和: if __name__ == "__main__": sum = 0 while True:
-
SQL注入报错注入函数图文详解
目录 前言 常用报错函数 用法详解 updatexml()函数 实例 extractvalue()函数 floor()函数 exp()函数 12种报错注入函数 总结 前言 报错注入的前提是当语句发生错误时,错误信息被输出到前端.其漏洞原因是由于开发人员在开发程序时使用了print_r (),mysql_error(),mysqli_connect_error()函数将mysql错误信息输出到前端,因此可以通过闭合原先的语句,去执行后面的语句. 常用报错函数 updatexml()
-
python的函数最详解
目录 一.函数入门 1.概念 2.定义函数的语法格式 函数名 形参列表 返回值 3.函数的文档(注释→help) 4.举例 二.函数的参数 1.可变对象 2.参数收集(不定个数的参数) 3.解决一个实际问题 4.参数收集(收集关键字参数) 5.逆向参数收集(炸开参数) 6.参数的内存管理 7.函数中变量的作用域 8.获取指定范围内的变量 三.局部函数(函数的嵌套) 四.函数的高级内容 1.函数作为函数的形参 2.使用函数作为返回值 3.递归 五.局部函数与lambda 1.用lambda表达式代
-
pytorch中的torch.nn.Conv2d()函数图文详解
目录 一.官方文档介绍 二.torch.nn.Conv2d()函数详解 参数dilation——扩张卷积(也叫空洞卷积) 参数groups——分组卷积 总结 一.官方文档介绍 官网 nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积 二.torch.nn.Conv2d()函数详解 参数详解 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
-
如何利用Python拟合函数曲线详解
目录 拟合多项式 函数说明 拟合任意函数 函数说明 总结 使用Python拟合函数曲线需要用到一些第三方库: numpy:科学计算的基础库(例如:矩阵) matplotlib:绘图库 scipy:科学计算库 如果没有安装过这些库,需要在命令行中输入下列代码进行安装: pip install numpy matplotlib scipy 拟合多项式 ''' Author: CloudSir Date: 2021-08-01 13:40:50 LastEditTime: 2021-08-02 09:
-
python reduce 函数使用详解
reduce() 函数在 python 2 是内置函数, 从python 3 开始移到了 functools 模块. 官方文档是这样介绍的 reduce(...) reduce(function, sequence[, initial]) -> value Apply a function of two arguments cumulatively to the items of a sequence, from left to right, so as to reduce the sequen