Scrapy爬虫文件批量运行的实现
Scrapy批量运行爬虫文件的两种方法:
1、使用CrawProcess实现
https://doc.scrapy.org/en/latest/topics/practices.html
2、修改craw源码+自定义命令的方式实现
(1)我们打开scrapy.commands.crawl.py 文件可以看到:
def run(self, args, opts):
if len(args) < 1:
raise UsageError()
elif len(args) > 1:
raise UsageError("running 'scrapy crawl' with more than one spider is no longer supported")
spname = args[0]
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
这是crawl.py 文件中的run() 方法,在此可以指定运行哪个爬虫,要运行所有的爬虫,则需要更改这个方法。
run() 方法中通过crawler_process.crawl(spname, **opts.spargs) 实现了爬虫文件的运行,spname代表爬虫名。要运行多个爬虫文件,首先要获取所有的爬虫文件,可以通过crawler_process.spider_loader.list() 实现。
(2)实现过程:
a、在spider目录的同级目录下创建存放源代码的文件夹mycmd,并在该目录下创建文件mycrawl.py;
b、将crawl.py 中的代码复制到mycrawl.py 文件中,然后进行修改:
#修改后的run() 方法
def run(self, args, opts):
#获取爬虫列表
spd_loader_list = self.crawler_process.spider_loader.list()
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print("此时启动的爬虫:"+spname)
self.crawler_process.start()
同时可以修改:
def short_desc(self):
return "Run all spider"
c、在mycmd文件夹下添加一个初始化文件__init__.py,在项目配置文件(setting.py)中添加格式为“COMMANDS_MODULES='项目核心目录.自定义命令源码目录'”的配置;
例如:COMMANDS_MODULE = 'firstpjt.mycmd'
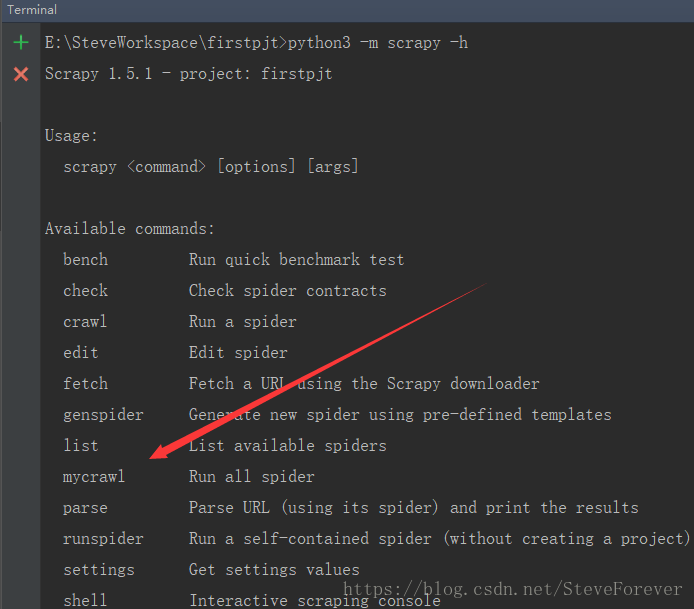
随后通过命令“scrapy -h”,可以查看到我们添加的命令mycrawl
这样,我们就可以同时启动多个爬虫文件了,使用命令:
scrapy mycrawl --nolog
到此这篇关于Scrapy爬虫文件批量运行的实现的文章就介绍到这了,更多相关Scrapy 批量运行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
Scrapy爬虫文件批量运行的实现
Scrapy批量运行爬虫文件的两种方法: 1.使用CrawProcess实现 https://doc.scrapy.org/en/latest/topics/practices.html 2.修改craw源码+自定义命令的方式实现 (1)我们打开scrapy.commands.crawl.py 文件可以看到: def run(self, args, opts): if len(args) < 1: raise UsageError() elif len(args) > 1: raise Usa
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Scrapy爬虫实例讲解_校花网
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地.Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能. Scrapy官方定义:Scrapy是用于抓取网站并提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘,信息处理或历史存档. 建立Scrapy爬虫工程 在安装好Scrapy框架后,直接使用命令行进行项目的创建: E:\ScrapyDemo>scrapy startproject xiaohuar New Scrapy projec
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
scrapy爬虫实例分享
前一篇文章介绍了很多关于scrapy的进阶知识,不过说归说,只有在实际应用中才能真正用到这些知识.所以这篇文章就来尝试利用scrapy爬取各种网站的数据. 爬取百思不得姐 首先一步一步来,我们先从爬最简单的文本开始.这里爬取的就是百思不得姐的的段子,都是文本. 首先打开段子页面,用F12工具查看元素.然后用下面的命令打开scrapyshell. scrapy shell http://www.budejie.com/text/ 稍加分析即可得到我们要获取的数据,在介绍scrapy的第一篇文章中我
-
Python3环境安装Scrapy爬虫框架过程及常见错误
Windows •安装lxml 最好的安装方式是通过wheel文件来安装,http://www.lfd.uci.edu/~gohlke/pythonlibs/,从该网站找到lxml的相关文件.假如是Python3.5版本,WIndows 64位系统,那就找到lxml‑3.7.2‑cp35‑cp35m‑win_amd64.whl 这个文件并下载,然后通过pip安装. 下载之后,运行如下命令安装: pip3 install wheel pip3 install lxml‑3.7.2‑cp35‑cp3
-
详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy,twisted,pypiwin32 一:进入你所需要的路径,这个路径存储你创建的项目 我的将放在E盘的Scrapy目录下 二:创建项目:scrapy startproject ***(这个是项目名) 这样就创建好了一个名为tencent的项目 三:进入项目新建一个爬虫:
-
python Scrapy爬虫框架的使用
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy 注意:不要使用commandlinetools自带的python进行安装,不然可能报架构错误:用brew下载的python进行安装. Scrapy实现爬虫 新建爬虫 scrapy startproject demoSpider,demoSpide