python数据可视化绘制世界人口地图
目录
- 前言
- 获取两个字母的国别码
- 制作世界地图
- 绘制完整的世界人口地图
- 根据人口数量将国家分组
- 根据Pygal设置世界地图的样式
前言
数据来源:population_data.json,
先看一下数据长啥样
[
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1960",
"Value": "96388069"
},
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1961",
"Value": "98882541.4"
},
省略。。。。
]
'''这个文件实际上就是一个很长的Python列表,其中每个元素都是一个包含四个键的字典:
国家名、国别码、年份以及表示人口数量的值。
我们只关心每个国家2010年的人口数量,因此我们首先编写一个打印这些信息的程序:'''
import json
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
#打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population =int(float(pop_dic['Value']) )#population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
print(country_name + ":" + str(population))
rab World:357868000
Caribbean small states:6880000
East Asia & Pacific (all income levels):2201536674
East Asia & Pacific (developing only):1961558757
Euro area:331766000
Europe & Central Asia (all income levels):890424544
Europe & Central Asia (developing only):405204000
获取两个字母的国别码
'''制作地图前,还需要解决数据存在的最后一个问题。Pygal中的地图制作工具要求数据为特定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常需要用到几个标准化国别码集。
population_data.json中包含的是三个字母的国别码,但Pygal使用两个字母的国别码。我们需要想办法根据国家名获取两个字母的国别码。
Pygal使用的国别码存储在模块i18n(internationalization的缩写)中。
字典COUNTRIES包含的键和值分别为两个字母的国别码和国家名。
要查看这些国别码,可从模块i18n中导入这个字典,并打印其键和值:'''
from pygal_maps_world.i18n import COUNTRIES
for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])
ad Andorra
ae United Arab Emirates
af Afghanistan
al Albania
为获取国别码,我们将编写一个函数,它在COUNTRIES中查找并返回国别码。
我们将这个函数放在一个名为country_codes的模块中,以便能够在可视化程序中导入它:
from pygal_maps_world.i18n import COUNTRIES
def get_country_code(country_name):
#根据指定的国家,返回Pygal使用的两个字母的国别码
for code,name in COUNTRIES.items():
if name == country_name :
return code
# 如果没有找到指定的国家,就返回None
return None
#打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population =int(float(pop_dic['Value']) )#population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
code = get_country_code(country_name)
if code :
print(code + ":" + str(population))
else:
print('error - ' + ":" + str(population))
error - :357868000
error - :6880000
error - :2201536674
error - :1961558757
error - :331766000
导致显示错误消息的原因有两个。首先,并非所有人口数量对应的都是国家,有些人口数量对应的是地区(阿拉伯世界)和经济类群(所有收入水平)。
其次,有些统计数据使用了不同的完整国家名(如Yemen, Rep.,而不是Yemen)。当前,我们将忽略导致错误的数据,看看根据成功恢复了的数据制作出的地图是什么样的。
制作世界地图
import pygal_maps_world.maps#创建了一个Worldmap实例,并设置了该地图的的title属性
wm = pygal_maps_world.maps.World()
wm.title = 'North, Central, and South America'
'''
了方法add(),它接受一个标签和一个列表,其中后者包含我们要突出的国家的国别码。每次调用add()都将为指定的国家
选择一种新颜色,并在图表左边显示该颜色和指定的标签。我们要以同一种颜色显示整个北美地区,因此第一次调用add()
时,在传递给它的列表中包含'ca'、'mx'和'us',以同时突出加拿大、墨西哥和美国。接下来,对中美和南美国家做同样
的处理。
'''
wm.add('North America', ['ca', 'mx', 'us'])
wm.add('Central America', ['bz', 'cr', 'gt', 'hn', 'ni', 'pa', 'sv'])
wm.add('South America', ['ar', 'bo', 'br', 'cl', 'co', 'ec', 'gf',
'gy', 'pe', 'py', 'sr', 'uy', 've'])
'''
方法render_to_file()创建一个包含该图表的.svg文件,你可以在浏览器中打开它。输出是一幅以不同颜色突出北美、
中美和南美的地图
'''
wm.render_to_file('americas.svg')

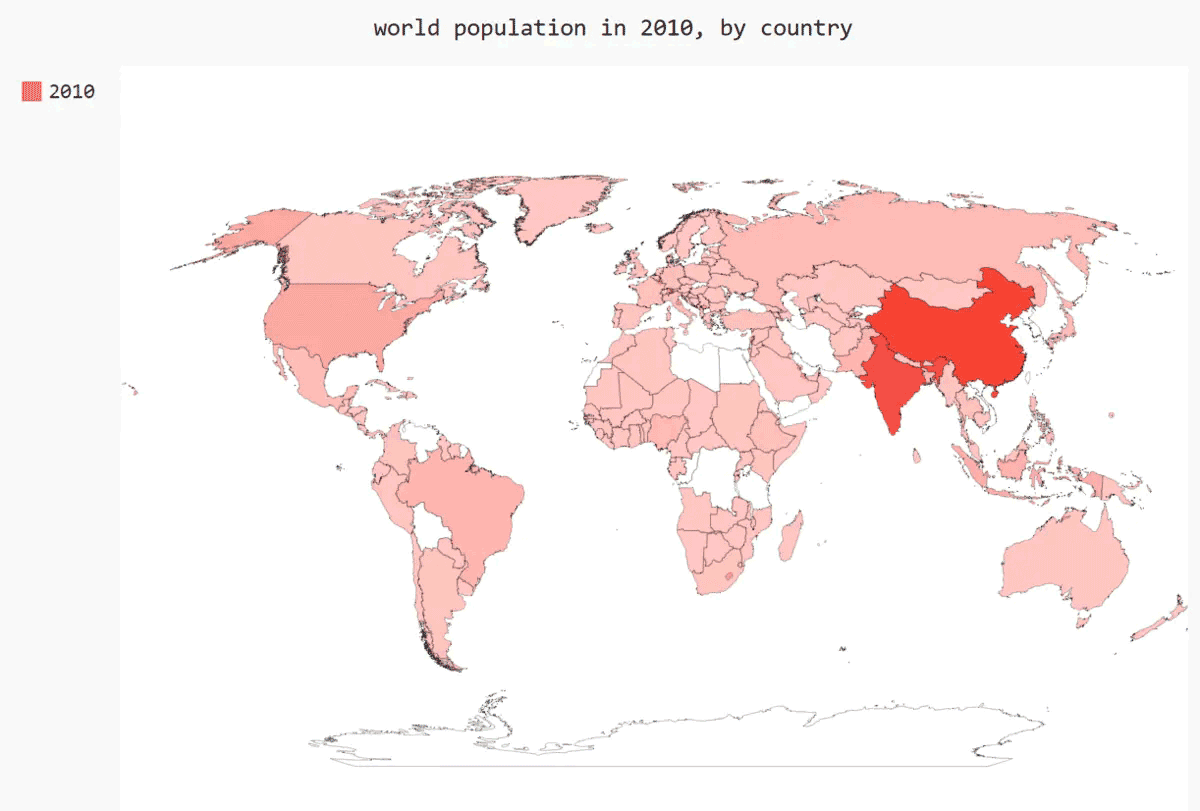
绘制完整的世界人口地图
'''要呈现其他国家的人口数量,需要将前面处理的数据转换为Pygal要求的字典格式:键为两个字母的国别码,值为人口数量。
为此,在world_population.py中添加如下代码:
import json
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
def get_country_code(country_name):
#根据指定的国家,返回Pygal使用的两个字母的国别码
for code,name in COUNTRIES.items():
if name == country_name :
return code
# 如果没有找到指定的国家,就返回None
return None
#创建一个包含人口数量是字典
cc_populations = {}
#打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population =int(float(pop_dic['Value']) )#population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
code = get_country_code(country_name)
if code :
cc_populations[code] = population
import pygal_maps_world.maps#创建了一个Worldmap实例,并设置了该地图的的title属性
wm = pygal_maps_world.maps.World()
wm.title = 'world population in 2010, by country'
wm.add('2010', cc_populations)
wm.render_to_file('world_population.svg')
根据人口数量将国家分组
import json
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
def get_country_code(country_name):
#根据指定的国家,返回Pygal使用的两个字母的国别码
for code,name in COUNTRIES.items():
if name == country_name :
return code
# 如果没有找到指定的国家,就返回None
return None
#创建一个包含人口数量是字典
cc_populations = {}
#打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population =int(float(pop_dic['Value']) )#population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
code = get_country_code(country_name)
if code :
cc_populations[code] = population
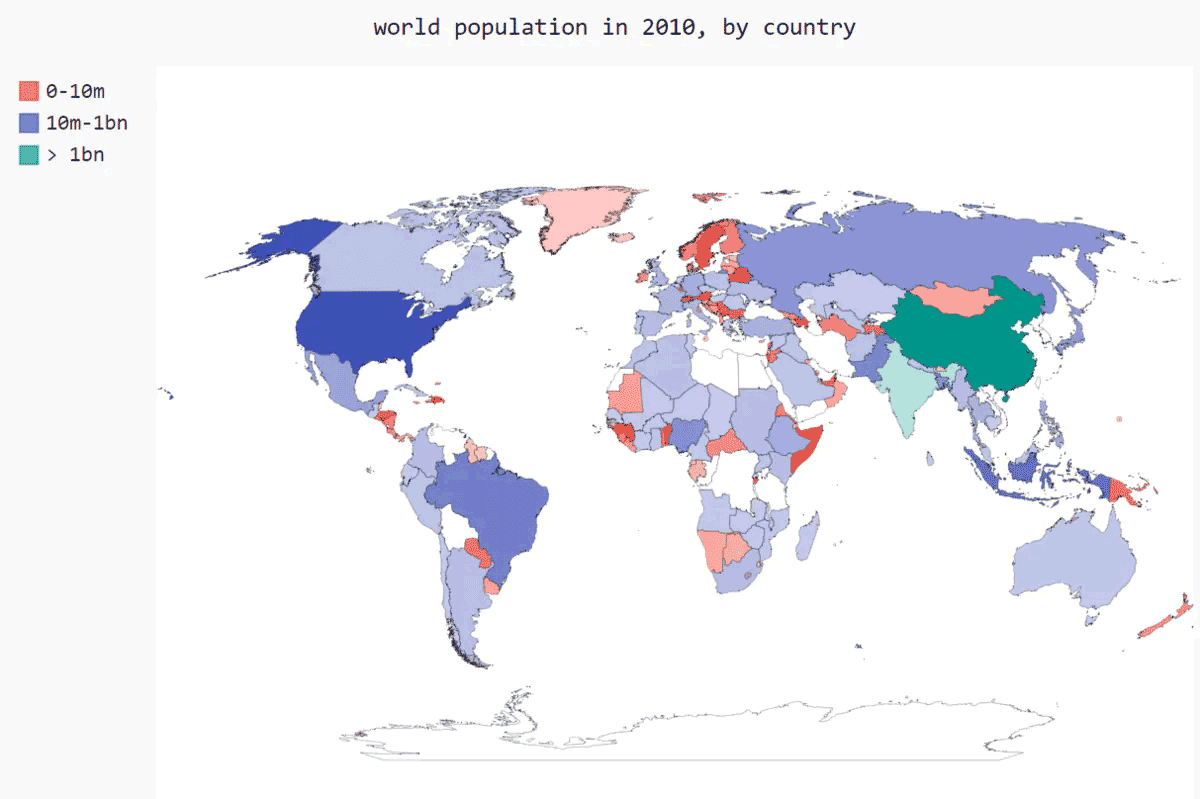
###根据人口数量将国家分3组
cc_pop_1,cc_pop_2,cc_pop_3 = {},{},{}
for cc,pop in cc_populations.items():
if pop < 10000000:
cc_pop_1[cc] = pop
elif pop < 1000000000:
cc_pop_2[cc] = pop
else:
cc_pop_3[cc] = pop
import pygal_maps_world.maps#创建了一个Worldmap实例,并设置了该地图的的title属性
wm = pygal_maps_world.maps.World()
wm.title = 'world population in 2010, by country'
wm.add('0-10m', cc_pop_1)
wm.add('10m-1bn', cc_pop_2)
wm.add('> 1bn', cc_pop_3)
wm.render_to_file('world_population.svg')
根据Pygal设置世界地图的样式
在这个地图中,根据人口将国家分组虽然很有效,但默认的颜色设置很难看。例如,在这里,Pygal选择了鲜艳的粉色和绿色基色。
下面使用Pygal样式设置指令来调整颜色。我们也让Pygal使用一种基色,但将指定该基色,并让三个分组的颜色差别更大
###根据Pygal设置世界地图的样式
'''
在这个地图中,根据人口将国家分组虽然很有效,但默认的颜色设置很难看。例如,在这里,Pygal选择了鲜艳的粉色
和绿色基色。下面使用Pygal样式设置指令来调整颜色。我们也让Pygal使用一种基色,但将指定该基色,并让三个分组
的颜色差别更大
'''
###根据人口数量将国家分组
import json
#将数据加载到一个列表中
filename= 'population_data.json'
with open(filename) as f :
pop_data = json.load(f)
def get_country_code(country_name):
#根据指定的国家,返回Pygal使用的两个字母的国别码
for code,name in COUNTRIES.items():
if name == country_name :
return code
# 如果没有找到指定的国家,就返回None
return None
#创建一个包含人口数量是字典
cc_populations = {}
#打印每个国家2010年的人口数量
for pop_dic in pop_data :
if pop_dic["Year"] == '2010' :
country_name= pop_dic['Country Name']
population =int(float(pop_dic['Value']) )#population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int():
code = get_country_code(country_name)
if code :
cc_populations[code] = population
###根据人口数量将国家分3组
cc_pop_1,cc_pop_2,cc_pop_3 = {},{},{}
for cc,pop in cc_populations.items():
if pop < 10000000:
cc_pop_1[cc] = pop
elif pop < 1000000000:
cc_pop_2[cc] = pop
else:
cc_pop_3[cc] = pop
import pygal_maps_world.maps#创建了一个Worldmap实例,并设置了该地图的的title属性
from pygal.style import RotateStyle
from pygal.style import LightColorizedStyle#加亮颜色主题
wm_style = RotateStyle('#336699', base_style= LightColorizedStyle)
wm = pygal_maps_world.maps.World(style = wm_style)
wm.title = 'world population in 2010, by country'
wm.add('2010', cc_populations)
wm.add('0-10m', cc_pop_1)
wm.add('10m-1bn', cc_pop_2)
wm.add('> 1bn', cc_pop_3)
wm.render_to_file('world_population.svg')

以上就是python数据可视化绘制世界人口地图的详细内容,更多关于python绘制世界人口地图的资料请关注我们其它相关文章!
相关推荐
-

python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
python数据可视化JupyterLab实用扩展程序Mito
目录 遇见 Mito 如何启动 Mito 数据透视表 Mito 令人印象深刻的功能 可视化数据 自动代码生成 Mito 安装 JupyterLab 是 Jupyter 主打的最新数据科学生产工具,某种意义上,它的出现是为了取代Jupyter Notebook. 它作为一种基于 web 的集成开发环境,你可以使用它编写notebook.操作终端.编辑markdown文本.打开交互模式.查看csv文件及图片等功能. JupyterLab 最棒的体验就是有丰富的扩展插件,我记得过去我们不得不依赖 nu
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
python数据可视化matplotlib绘制折线图示例
目录 plt.plot()函数各参数解析 各参数具体含义为: x,y color linestyle linewidth marker 关于marker的参数 plt.plot()函数各参数解析 plt.plot()函数的作用是绘制折线图,它的参数有很多,常用的函数参数如下: plt.plot(x,y,color,linestyle,linewidth,marker,markersize,markerfacecolor,markeredgewidth,markeredgecolor) 各参数具体
-
python+opencv实现堆叠图片
本文实例为大家分享了python+opencv实现堆叠图片的具体代码,供大家参考,具体内容如下 # import cv2 # import numpy as np # # img = cv2.imread('../images/full.jpg') # # img_hor = np.hstack((img,img)) # img_ver = np.vstack((img,img)) # # cv2.imshow('Horizontal',img_hor) # cv2.imshow('Vertic
-
python数据可视化绘制世界人口地图
目录 前言 获取两个字母的国别码 制作世界地图 绘制完整的世界人口地图 根据人口数量将国家分组 根据Pygal设置世界地图的样式 前言 数据来源:population_data.json, 先看一下数据长啥样 [ { "Country Name": "Arab World", "Country Code": "ARB", "Year": "1960", "Value"
-
python数据可视化绘制火山图示例
目录 导入模块 1.读取测试数据 2.查看数据 3.筛选差异基因 4.查看数据,发现多了type这一列 5.统计个数 6.绘火山图 7.保存图片 导入模块 import numpy as np import pandas as pd 1.读取测试数据 data=pd.read_csv(r'E:\ZYH\R.project\rna-seq\lianxi1\exon_level\df.csv') 2.查看数据 data.head() 3.筛选差异基因 # 3.尝试写循环筛选上下调基因分类赋值给 "u
-
Python数据可视化之绘制柱状图和条形图
一.实验目的: 1.掌握Python中柱状图.条形图绘图函数的使用 2.利用上述绘图函数实现数据可视化 二.实验内容: 1.练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 2.根据步骤一绘图函数要求,处理实验数据 3.根据步骤二得到的实验数据,绘制柱状图.条形图 4.练习如何通过调整参数使图片呈现不同效果,例如颜色.图例位置.背景网格.坐标轴刻度和标记等 三.实验过程(附结果截图): 1. 练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 (1)练习绘制条形
-
Python数据可视化之用Matplotlib绘制常用图形
一.散点图 散点图用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 特点:判断变量之间是否存在数量关联趋势,表示离群点的分布规律. 散点图绘制: plt.scatter(x,y) # 以默认的形状颜色绘制散点图 实例: 假设我们获取到了上海2020年5,10月份每天白天的最高气温(分别位于列表a.b),那么此时如何观察气温和随时间变化的某种规律. # 绘制图形所需的数据 y_5 = [11,17,16,11,12,11,12,13,10,14,8
-
Python数据可视化之基于pyecharts实现的地理图表的绘制
一.例子:百度迁徙 百度地图春节人口迁徙大数据(简称百度迁徙),是百度在2014年春运期间推出的一项技术项目.百度迁徙利用大数据,对其拥有的LBS(基于地理位置的服务)大数据进行计算分析,采用的可视化呈现方式,动态.即时.直观地展现中国春节前后人口大迁徙的轨迹与特征. 网址:https://qianxi.baidu.com/2021/ 二.基础语法介绍 语法 说明 from pyecharts.charts import Geo 导入地图库 Geo() Pyecharts地理图表绘制 .add_
-
python数据可视化Seaborn绘制山脊图
目录 1. 引言 2. 举个栗子 3.山脊图 4.扩展 5.结论 1. 引言 山脊图一般由垂直堆叠的折线图组成,这些折线图中的折线区域间彼此重叠,此外它们还共享相同的x轴. 山脊图经常以一种相对不常见且非常适合吸引大家注意力的紧凑图的形式表现.观察上图,我们给其起名叫Ridge plot是非常恰当的,因为上述图表看起来确实很像山的脊背.此外,上述图像还有另一个称呼叫做Joy Plots–这主要是因为Joy Division乐队在如下专辑封面上采用了这种可视化形式. 2. 举个栗子 在介绍完山脊图
-
Python利用matplotlib模块数据可视化绘制3D图
目录 前言 1 matplotlib绘制3D图形 2 绘制3D画面图 2.1 源码 2.2 效果图 3 绘制散点图 3.1 源码 3.2 效果图 4 绘制多边形 4.1 源码 4.2 效果图 5 三个方向有等高线的3D图 5.1 源码 5.2 效果图 6 三维柱状图 6.1 源码 6.2 效果图 7 补充图 7.1 源码 7.2 效果图 总结 前言 matplotlib实际上是一套面向对象的绘图库,它所绘制的图表中的每个绘图元素,例如线条Line2D.文字Text.刻度等在内存中都有一个对象与之
-
Python 数据可视化神器Pyecharts绘制图像练习
目录 前言: 1.Hive数据库查询sql 2.Python代码实现—柱状图 3.Python代码实现—饼状图 4.Python代码实现—箱型图 5.Python代码实现—折线图 6.Python代码实现—雷达图 7.Python代码实现—散点图 前言: Echarts 是百度开源的一款数据可视化 JS 工具,数据可视化类型十分丰富,但是得通过导入 js 库在 Java Web 项目上运行. 作为工作中常用 Python 的选手,不能不知道这款数据可视化插件的强大.那么,能否在 Python 中
-
Python数据可视化之简单折线图的绘制
目录 创建RandomWalk类 选择方向 绘制随机漫步图 模拟多次随机漫步 给点着色 突出起点和终点 增加点数 调整尺寸以适用屏幕 创建RandomWalk类 为模拟随机漫步,我们将创建一个RandomWalk类,随机选择前进方向,这个类有三个属性,一个存储随机漫步的次数,另外两个存储随机漫步的每个点的x,y坐标,每次漫步都从点(0,0)出发 from random import choice class RandomWalk(): '''一个生成随机漫步数据的类''' def __init_