python内存泄漏排查技巧总结
目录
- 思路一:研究新旧源码及二方库依赖差异
- 思路二:监测新旧版本内存变化差异
- 问题所在
- 进阶思路
- 1.使用objgraph工具
- 2.使用pympler工具
首先搞清楚了本次问题的现象:
- 1. 服务在13号上线过一次,而从23号开始,出现内存不断攀升问题,达到预警值重启实例后,攀升速度反而更快。
- 2. 服务分别部署在了A、B 2种芯片上,但除模型推理外,几乎所有的预处理、后处理共享一套代码。而B芯片出现内存泄漏警告,A芯片未出现任何异常。
思路一:研究新旧源码及二方库依赖差异
根据以上两个条件,首先想到的是13号的更新引入的问题,而更新可能来自两个方面:
- 自研代码
- 二方依赖代码
从上述两个角度出发:
- 一方面,分别用
Git历史信息和BeyondCompare工具对比了两个版本的源码,并重点走读了下A、B两款芯片代码单独处理的部分,均未发现任何异常。 - 另一方面,通过pip list命令对比两个镜像包中的二方包,发现仅有pytz时区工具依赖的版本有变化。
经过研究分析,认为此包导致的内存泄漏的可能性不大,因此暂且放下

至此,通过研究新旧版本源码变化找出内存泄漏问题这条路,似乎有点走不下去了。
思路二:监测新旧版本内存变化差异
目前python常用的内存检测工具有pympler、objgraph、tracemalloc 等。
首先,通过objgraph工具,对新旧服务中的TOP50变量类型进行了观察统计
objraph常用命令如下:
# 全局类型数量 objgraph.show_most_common_types(limit=50) # 增量变化 objgraph.show_growth(limit=30)
这里为了更好的观测变化曲线,我简单做了个封装,使数据直接输出到了csv文件以便观察。
stats = objgraph.most_common_types(limit=50)
stats_path = "./types_stats.csv"
tmp_dict = dict(stats)
req_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
tmp_dict['req_time'] = req_time
df = pd.DataFrame.from_dict(tmp_dict, orient='index').T
if os.path.exists(stats_path):
df.to_csv(stats_path, mode='a', header=True, index=False)
else:
df.to_csv(stats_path, index=False)
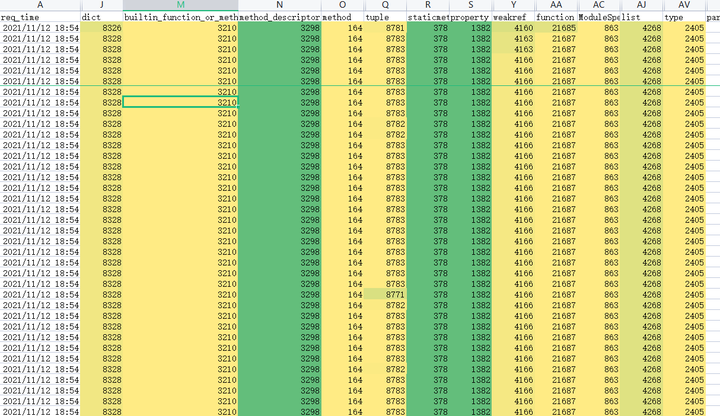
如下图所示,用一批图片在新旧两个版本上跑了1个小时,一切稳如老狗,各类型的数量没有一丝波澜。
此时,想到自己一般在转测或上线前都会将一批异常格式的图片拿来做个边界验证。
虽然这些异常,测试同学上线前肯定都已经验证过了,但死马当成活马医就顺手拿来测了一下。
平静数据就此被打破了,如下图红框所示:dict、function、method、tuple、traceback等重要类型的数量开始不断攀升。
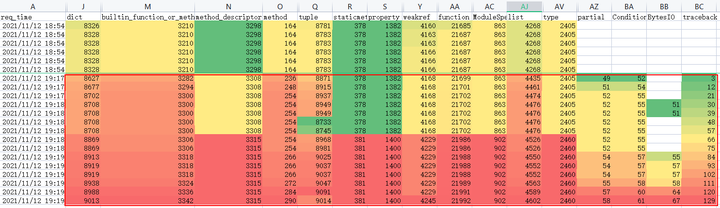
而此时镜像内存亦不断增加且毫无收敛迹象。

由此,虽无法确认是否为线上问题,但至少定位出了一个bug。而此时回头检查日志,发现了一个奇怪的现象:
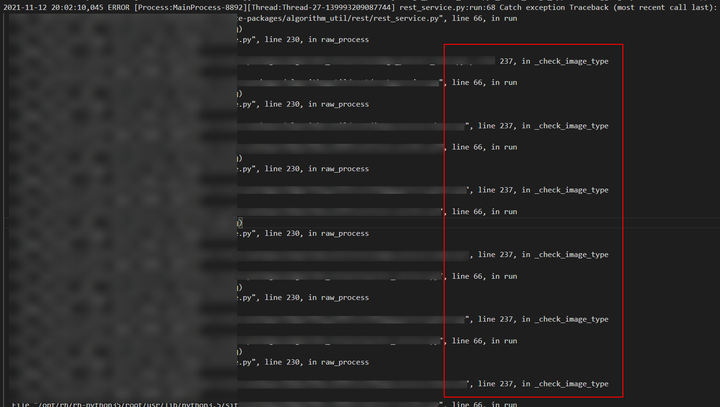
正常情况下特殊图片导致的异常,日志应该输出如下信息,即check_image_type方法在异常栈中只会打印一次。

但现状是check_image_type方法循环重复打印了多次,且重复次数随着测试次数在一起变多。
重新研究了这块儿的异常处理代码。
异常声明如下:

抛异常代码如下:

问题所在
思考后大概想清楚了问题根源:
这里每个异常实例相当于被定义成了一个全局变量,而在抛异常的时候,抛出的也正是这个全局变量。当此全局变量被压入异常栈处理完成之后,也并不会被回收。
因此随着错误格式图片调用的不断增多,异常栈中的信息也会不断增多。而且由于异常中还包含着请求图片信息,因此内存会呈MB级别的增加。
但这部分代码上线已久,线上如果真的也是这里导致的问题,为何之前没有任何问题,而且为何在A芯片上也没有出现任何问题?
带着以上两个疑问,我们做了两个验证:
首先,确认了之前的版本以及A芯片上同样会出现此问题。
其次,我们查看了线上的调用记录,发现最近刚好新接入了一个客户,而且出现了大量使用类似问题的图片调用某局点(该局点大部分为B芯片)服务的现象。我们找了些线上实例,从日志中也观测到了同样的现象。
由此,以上疑问基本得到了解释,修复此bug后,内存溢出问题不再出现。
进阶思路
讲道理,问题解决到这个地步似乎可以收工了。但我问了自己一个问题,如果当初没有打印这一行日志,或者开发人员偷懒没有把异常栈全部打出来,那应该如何去定位?
带着这样的问题我继续研究了下objgraph、pympler 工具。
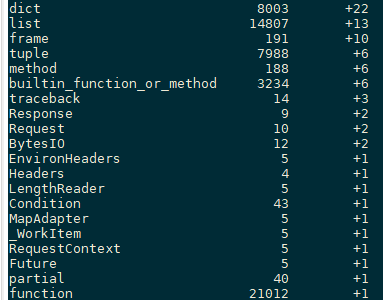
前文已经定位到了在异常图片情况下会出现内存泄漏,因此重点来看下此时有哪些异样情况:
通过如下命令,我们可以看到每次异常出现时,内存中都增加了哪些变量以及增加的内存情况。
1.使用objgraph工具
objgraph.show_growth(limit=20)
2.使用pympler工具
from pympler import tracker tr = tracker.SummaryTracker() tr.print_diff()
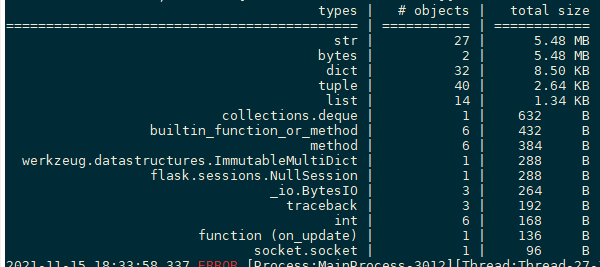
通过如下代码,可以打印出这些新增变量来自哪些引用,以便进一步分析。
gth = objgraph.growth(limit=20)
for gt in gth:
logger.info("growth type:%s, count:%s, growth:%s" % (gt[0], gt[1], gt[2]))
if gt[2] > 100 or gt[1] > 300:
continue
objgraph.show_backrefs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_backrefs.dot" % gt[0])
objgraph.show_refs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_refs.dot" % gt[0])
objgraph.show_chain(
objgraph.find_backref_chain(objgraph.by_type(gt[0])[0], objgraph.is_proper_module),
filename="./dots/%s_chain.dot" % gt[0]
)
通过graphviz的dot工具,对上面生产的graph格式数据转换成如下图片:
dot -Tpng xxx.dot -o xxx.png
这里,由于dict、list、frame、tuple、method等基本类型数量太多,观测较难,因此这里先做了过滤。
内存新增的ImageReqWrapper的调用链
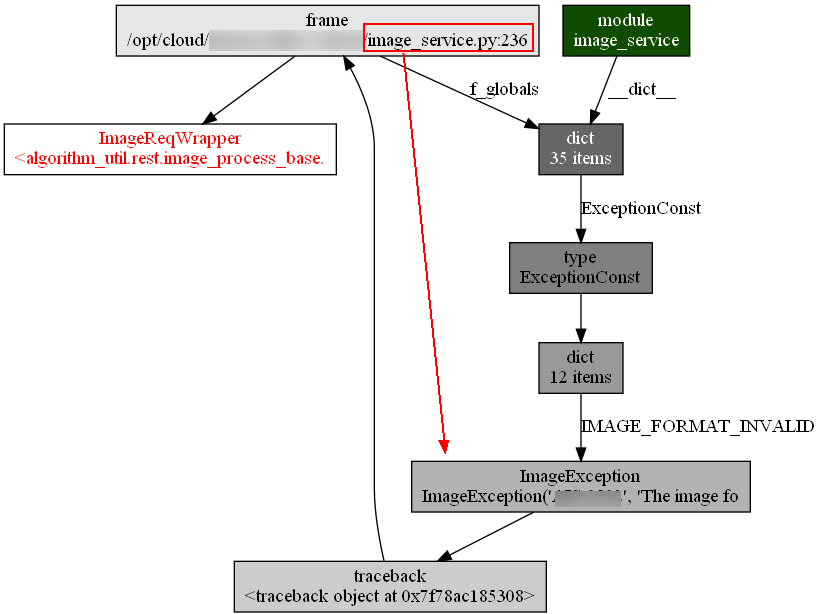
内存新增的traceback的调用链:
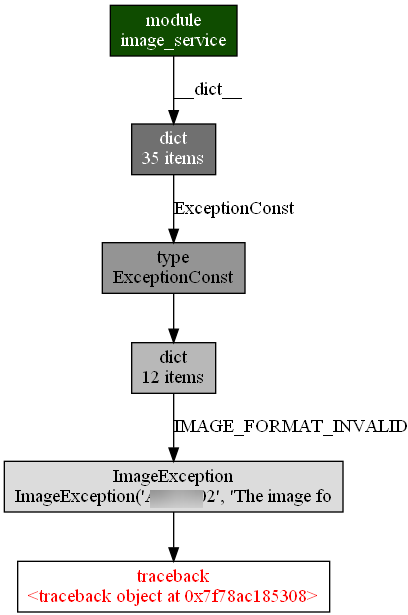
虽然带着前面的先验知识,使我们很自然的就关注到了traceback和其对应的IMAGE_FORMAT_EXCEPTION异常。
但通过思考为何上面这些本应在服务调用结束后就被回收的变量却没有被回收,尤其是所有的traceback变量在被IMAGE_FORMAT_EXCEPTION异常调用后就无法回收等这些现象;同时再做一些小实验,相信很快就能定位到问题根源。
另,关于 python3中 缓存Exception导致的内存泄漏问题,我们可以看看这篇文章:
至此,我们可以得出结论如下:
由于抛出的异常无法回收,导致对应的异常栈、请求体等变量都无法被回收,而请求体中由于包含图片信息因此每次这类请求都会导致MB级别的内存泄漏。
另外,研究过程中还发现python3自带了一个内存分析工具tracemalloc,通过如下代码就可以观察代码行与内存之间的关系,虽然可能未必精确,但也能大概提供一些线索。
import tracemalloc
tracemalloc.start(25)
snapshot = tracemalloc.take_snapshot()
global snapshot
gc.collect()
snapshot1 = tracemalloc.take_snapshot()
top_stats = snapshot1.compare_to(snapshot, 'lineno')
logger.warning("[ Top 20 differences ]")
for stat in top_stats[:20]:
if stat.size_diff < 0:
continue
logger.warning(stat)
snapshot = tracemalloc.take_snapshot()
到此这篇关于python内存泄漏排查技巧总结的文章就介绍到这了,更多相关python内存泄漏排查技巧内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
参考文章:
https://testerhome.com/articles/19870?order_by=created_at&
https://blog.51cto.com/u_3423936/3019476
https://segmentfault.com/a/1190000038277797
https://www.cnblogs.com/zzbj/p/13532156.html
https://drmingdrmer.github.io/tech/programming/2017/05/06/python-mem.html
https://zhuanlan.zhihu.com/p/38600861
相关推荐
-
总结python 三种常见的内存泄漏场景
概要 不要以为 Python 有自动垃圾回收就不会内存泄漏,本着它有"垃圾回收"我有"垃圾代码"的精神,现在总结一下三种常见的内存泄漏场景. 无穷大导致内存泄漏 如果把内存泄漏定义成只申请不释放,那么借着 Python 中整数可以无穷大的这个特点,我们一行代码就可以完成内存泄漏了. i = 1024 ** 1024 ** 1024 循环引用导致内存泄漏 引用记数器 是 Python 垃圾回收机制的基础,如果一个对象的引用数量不为 0 那么是不会被垃圾回收的,我们可以
-
粗略分析Python中的内存泄漏
引子 之前一直盲目的认为 Python 不会存在内存泄露, 但是眼看着上线的项目随着运行时间的增长 而越来越大的内存占用, 我意识到我写的程序在发生内存泄露, 之前 debug 过 logging 模块导致的内存泄露. 目前看来, 还有别的地方引起的内存泄露. 经过一天的奋战, 终于找到了内存泄露的地方, 目前项目 跑了很长时间, 在业务量较小的时候内存还是能回到刚启动的时候的内存占用. 什么情况下不用这么麻烦 如果你的程序只是跑一下就退出大可不必大费周章的去查找是否有内存泄露, 因为 Pyth
-
Python内存泄漏和内存溢出的解决方案
一.内存泄漏 像Java程序一样,虽然Python本身也有垃圾回收的功能,但是同样也会产生内存泄漏的问题. 对于一个用 python 实现的,长期运行的后台服务进程来说,如果内存持续增长,那么很可能是有了"内存泄露". 1.内存泄露的原因 对于 python 这种支持垃圾回收的语言来说,怎么还会有内存泄露? 概括来说,有以下三种原因: 所用到的用 C 语言开发的底层模块中出现了内存泄露. 代码中用到了全局的 list. dict 或其它容器,不停的往这些容器中插入对象,而忘记了在使用完
-
记一次python 内存泄漏问题及解决过程
最近工作中慢慢开始用python协程相关的东西,所以用到了一些相关模块,如aiohttp, aiomysql, aioredis等,用的过程中也碰到的很多问题,这里整理了一次内存泄漏的问题 通常我们写python程序的时候也很少关注内存这个问题(当然可能我的能力还有待提升),可能写c和c++的朋友会更多的考虑这个问题,但是一旦我们的python程序出现了 内存泄漏的问题,也将是一件非常麻烦的事情了,而最近的一次代码中也碰到了这个问题,不过好在最后内存溢出不是我代码的问题,而是所用到的一个包出现了
-
对python程序内存泄漏调试的记录
问题描述 调试python程序时,用下面这段代码,可以获得进程占用系统内存值.程序跑一段时间后,就能画出进程对内存的占用情况. def memory_usage_psutil(): # return the memory usage in MB import psutil,os process = psutil.Process(os.getpid()) mem = process.memory_info()[0] / float(2 ** 20) return mem 发现进程的内存占用一直再上
-

python内存泄漏排查技巧总结
目录 思路一:研究新旧源码及二方库依赖差异 思路二:监测新旧版本内存变化差异 问题所在 进阶思路 1.使用objgraph工具 2.使用pympler工具 首先搞清楚了本次问题的现象: 1. 服务在13号上线过一次,而从23号开始,出现内存不断攀升问题,达到预警值重启实例后,攀升速度反而更快. 2. 服务分别部署在了A.B 2种芯片上,但除模型推理外,几乎所有的预处理.后处理共享一套代码.而B芯片出现内存泄漏警告,A芯片未出现任何异常. 思路一:研究新旧源码及二方库依赖差异 根据以上两个条件,首
-
Android内存泄漏排查利器LeakCanary
本文为大家分享了Android内存泄漏排查利器,供大家参考,具体内容如下 开源地址:https://github.com/square/leakcanary 在 build.gralde 里加上依赖, 然后sync 一下, 添加内容如下 dependencies { .... debugCompile 'com.squareup.leakcanary:leakcanary-android:1.5' releaseCompile 'com.squareup.leakcanary:leakcanar
-
一次NodeJS内存泄漏排查的实战记录
目录 前言 案例一 故障现象 排查过程 案例二 故障现象 排查过程 问题原因 node-v9.x 以下的版本 node-v10.x 以上的版本 修复泄露 总结 前言 性能问题(内存.CPU 飙升导致服务重启.异常)排查一直是 Node.js 服务端开发的难点,去年在经过调研后,在我们项目的 Node.js 服务上都接入了 Easy-Monitor 来帮助排查生产环境遇到的性能问题.前段时间遇到了两例内存泄漏的案例,在这里做一个排查经过的整理. 案例一 故障现象 线上的某个服务发生了重启,经过观察
-
C++之内存泄漏排查详解
目录 一 .经验排查 二 .使用Visual Leak Detector for Visual C++ 2.1 Visual Leak Detector for Visual C++简介 2.2 Visual Leak Detector源码获取编译 2.2.1 源码获取,相关git地址 2.2.2 发布版本获取 2.2.3 进行编译 2.2.4 自带gtest工程测试 2.3 如何测试自己的项目呢 2.3.1 配置工程 2.3.2 编写简单的测试用例 2.3.3 检测结果如图 三.总结 一 .经
-
手把手教你如何排查Javascript内存泄漏
目录 引言 如何判断我的应用发生了内存泄漏 Performance和Memory都可以用来定位内存问题,先用谁呢 通过Memory面板定位内存泄漏的流程通常是怎么样的呢 为什么我的内存快照记录下来之后看不懂,还出现了很多奇怪的变量 快照里有一些“Detached DOM tree”,是什么意思 Shallow size 和 Retained size,它们有什么不同 Memory里的Summary视图, Comparison视图, Dominators视图和Containment视图分别有什么不
-
浅谈VueJS SSR 后端绘制内存泄漏的相关解决经验
引言 Memory Leak 是最难排查调试的 Bug 种类之一,因为内存泄漏是个 undecidable problem,只有开发者才能明确一块内存是不是需要被回收.再加上内存泄漏也没有特定的报错信息,只能通过一定时间段的日志来判断是否存在内存泄漏.大家熟悉的常用调试工具对排查内存泄漏也没有用武之地.当然了,除了专门用于排查内存泄漏的工具(抓取Heap之类的工具)之外. 对于不同的语言,各种排查内存泄漏的方式方法也不尽相同.对于 JavaScript 来说,针对不同的平台,调试工具也是不一样的
-
Python的内存泄漏及gc模块的使用分析
一般来说在 Python 中,为了解决内存泄漏问题,采用了对象引用计数,并基于引用计数实现自动垃圾回收. 由于Python 有了自动垃圾回收功能,就造成了不少初学者误认为自己从此过上了好日子,不必再受内存泄漏的骚扰了.但如果仔细查看一下Python文档对 __del__() 函数的描述,就知道这种好日子里也是有阴云的.下面摘抄一点文档内容如下: Some common situations that may prevent the reference count of an object fro