Pytorch之如何dropout避免过拟合
一.做数据


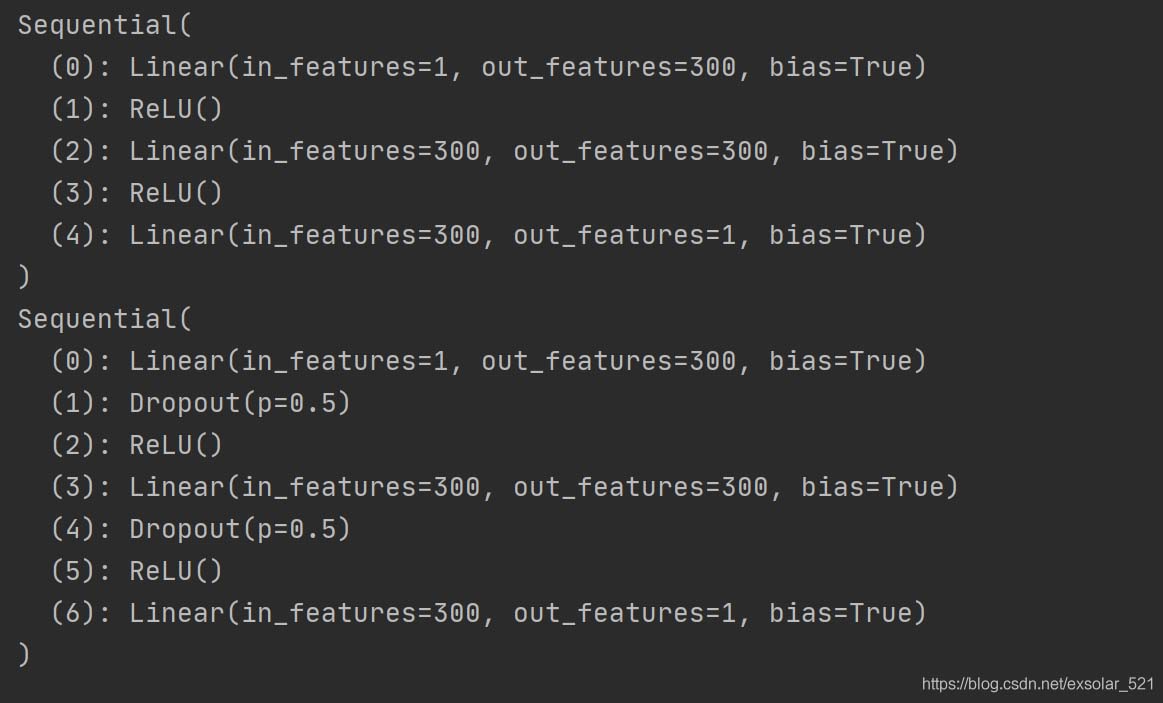
二.搭建神经网络

三.训练

四.对比测试结果
注意:测试过程中,一定要注意模式切换

Pytorch的学习——过拟合
过拟合
过拟合是当数据量较小时或者输出结果过于依赖某些特定的神经元,训练神经网络训练会发生一种现象。出现这种现象的神经网络预测的结果并不具有普遍意义,其预测结果极不准确。
解决方法
1.增加数据量
2.L1,L2,L3…正规化,即在计算误差值的时候加上要学习的参数值,当参数改变过大时,误差也会变大,通过这种惩罚机制来控制过拟合现象
3.dropout正规化,在训练过程中通过随机屏蔽部分神经网络连接,使神经网络不完整,这样就可以使神经网络的预测结果不会过分依赖某些特定的神经元
例子
这里小编通过dropout正规化的列子来更加形象的了解神经网络的过拟合现象
import torch
import matplotlib.pyplot as plt
N_SAMPLES = 20
N_HIDDEN = 300
# train数据
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# test数据
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# 可视化
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
# 网络一,未使用dropout正规化
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
# 网络二,使用dropout正规化
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5), # 随机屏蔽50%的网络连接
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5), # 随机屏蔽50%的网络连接
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
# 选择优化器
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
# 选择计算误差的工具
loss_func = torch.nn.MSELoss()
plt.ion()
for t in range(500):
# 神经网络训练数据的固定过程
pred_ofit = net_overfitting(x)
pred_drop = net_dropped(x)
loss_ofit = loss_func(pred_ofit, y)
loss_drop = loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()
if t % 10 == 0:
# 脱离训练模式,这里便于展示神经网络的变化过程
net_overfitting.eval()
net_dropped.eval()
# 可视化
plt.cla()
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data.numpy(),
fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data.numpy(),
fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
# 重新进入训练模式,并继续上次训练
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()
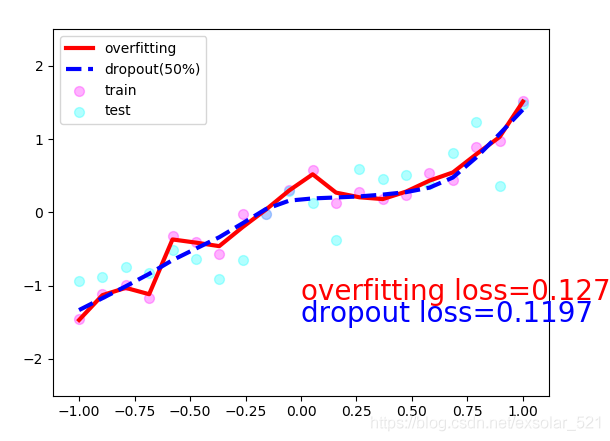
效果
可以看到红色的线虽然更加拟合train数据,但是通过test数据发现它的误差反而比较大

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pytorch Dropout过拟合的操作
如下所示: import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed(1) N_SAMPLES = 20 N_HIDDEN = 300 # training data x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1) y = x + 0.3 * torch.normal(torch.zeros(
-
pytorch 实现在测试的时候启用dropout
我们知道,dropout一般都在训练的时候使用,那么测试的时候如何也开启dropout呢? 在pytorch中,网络有train和eval两种模式,在train模式下,dropout和batch normalization会生效,而val模式下,dropout不生效,bn固定参数. 想要在测试的时候使用dropout,可以把dropout单独设为train模式,这里可以使用apply函数: def apply_dropout(m): if type(m) == nn.Dropout: m.tra
-
浅谈pytorch中的dropout的概率p
最近需要训练一个模型,在优化模型时用了dropout函数,为了减少过拟合. 训练的时候用dropout,测试的时候不用dropout.刚开始以为p是保留神经元的比率,训练设置0.5,测试设置1,loss根本没减小过,全设置成1也是一样的效果,后来就考虑到是不是p设置错了. 上网一搜,果然是的!!!p的含义理解错了!不是保留的,而是不保留的! 具体的代码为: x2 = F.dropout(x1, p) x1是上一层网络的输出,p是需要删除的神经元的比例. 当p=0时,保留全部神经元更新.当p=1时
-
PyTorch dropout设置训练和测试模式的实现
看代码吧~ class Net(nn.Module): - model = Net() - model.train() # 把module设成训练模式,对Dropout和BatchNorm有影响 model.eval() # 把module设置为预测模式,对Dropout和BatchNorm模块有影响 补充:Pytorch遇到的坑--训练模式和测试模式切换 由于训练的时候Dropout和BN层起作用,每个batch BN层的参数不一样,dropout在训练时随机失效点具有随机性,所以训练和测试要
-
PyTorch 实现L2正则化以及Dropout的操作
了解知道Dropout原理 如果要提高神经网络的表达或分类能力,最直接的方法就是采用更深的网络和更多的神经元,复杂的网络也意味着更加容易过拟合. 于是就有了Dropout,大部分实验表明其具有一定的防止过拟合的能力. 用代码实现Dropout Dropout的numpy实现 PyTorch中实现dropout import torch.nn.functional as F import torch.nn.init as init import torch from torch.autograd
-
pytorch 中nn.Dropout的使用说明
看代码吧~ Class USeDropout(nn.Module): def __init__(self): super(DropoutFC, self).__init__() self.fc = nn.Linear(100,20) self.dropout = nn.Dropout(p=0.5) def forward(self, input): out = self.fc(input) out = self.dropout(out) return out Net = USeDropout()
-
Pytorch之如何dropout避免过拟合
一.做数据 二.搭建神经网络 三.训练 四.对比测试结果 注意:测试过程中,一定要注意模式切换 Pytorch的学习--过拟合 过拟合 过拟合是当数据量较小时或者输出结果过于依赖某些特定的神经元,训练神经网络训练会发生一种现象.出现这种现象的神经网络预测的结果并不具有普遍意义,其预测结果极不准确. 解决方法 1.增加数据量 2.L1,L2,L3-正规化,即在计算误差值的时候加上要学习的参数值,当参数改变过大时,误差也会变大,通过这种惩罚机制来控制过拟合现象 3.dropout正规化,在训练过程中
-
tensorflow使用L2 regularization正则化修正overfitting过拟合方式
L2正则化原理: 过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差. 可见,要想减小过拟合,减小这个波动,减少w的数值就能办到. L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式如下图: (正则化是不阻碍你去拟合曲线的,并不是所有参数都会被无脑抑制,实
-
keras处理欠拟合和过拟合的实例讲解
baseline import tensorflow.keras.layers as layers baseline_model = keras.Sequential( [ layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)), layers.Dense(16, activation='relu'), layers.Dense(1, activation='sigmoid') ] ) baseline_model.compil
-
Tensorflow简单验证码识别应用
简单的Tensorflow验证码识别应用,供大家参考,具体内容如下 1.Tensorflow的安装方式简单,在此就不赘述了. 2.训练集训练集以及测试及如下(纯手工打造,所以数量不多): 3.实现代码部分(参考了网上的一些实现来完成的) main.py(主要的神经网络代码) from gen_check_code import gen_captcha_text_and_image_new,gen_captcha_text_and_image from gen_check_code import
-
python tensorflow基于cnn实现手写数字识别
一份基于cnn的手写数字自识别的代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 加载数据集 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 以交互式方式启动session # 如果不使用交互式session,则在启动s
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测