详解Java高并发编程之AtomicReference
目录
- 一、AtomicReference 基本使用
- 1.1、使用 synchronized 保证线程安全性
- 二、了解 AtomicReference
- 2.1、使用 AtomicReference 保证线程安全性
- 2.2、AtomicReference 源码解析
- 2.2.1、get and set
- 2.2.2、lazySet 方法
- 2.2.3、getAndSet 方法
- 2.2.4、compareAndSet 方法
- 2.2.5、weakCompareAndSet 方法
一、AtomicReference 基本使用
我们这里再聊起老生常谈的账户问题,通过个人银行账户问题,来逐渐引入 AtomicReference 的使用,我们首先来看一下基本的个人账户类
public class BankCard {
private final String accountName;
private final int money;
// 构造函数初始化 accountName 和 money
public BankCard(String accountName,int money){
this.accountName = accountName;
this.money = money;
}
// 不提供任何修改个人账户的 set 方法,只提供 get 方法
public String getAccountName() {
return accountName;
}
public int getMoney() {
return money;
}
// 重写 toString() 方法, 方便打印 BankCard
@Override
public String toString() {
return "BankCard{" +
"accountName='" + accountName + '\'' +
", money='" + money + '\'' +
'}';
}
}
个人账户类只包含两个字段:accountName 和 money,这两个字段代表账户名和账户金额,账户名和账户金额一旦设置后就不能再被修改。
现在假设有多个人分别向这个账户打款,每次存入一定数量的金额,那么理想状态下每个人在每次打款后,该账户的金额都是在不断增加的,下面我们就来验证一下这个过程。
public class BankCardTest {
private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(),card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
}).start();
}
}
}
在上面的代码中,我们首先声明了一个全局变量 BankCard,这个 BankCard 由 volatile进行修饰,目的就是在对其引用进行变化后对其他线程可见,在每个打款人都存入一定数量的款项后,输出账户的金额变化,我们可以观察一下这个输出结果。
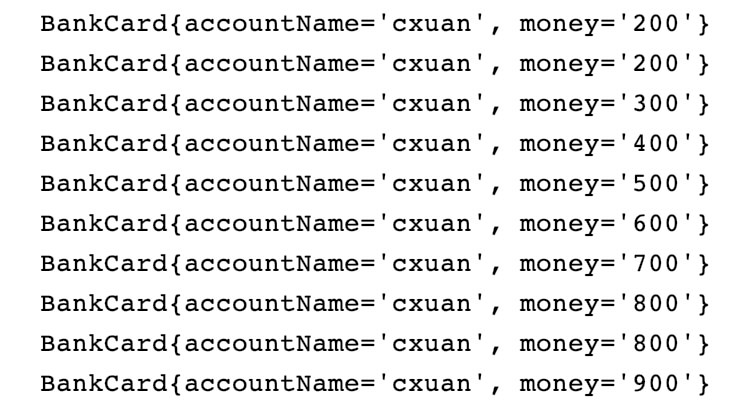
可以看到,我们预想最后的结果应该是 1100 元,但是最后却只存入了 900 元,那 200 元去哪了呢?我们可以断定上面的代码不是一个线程安全的操作。
问题出现在哪里?
虽然每次 volatile 都能保证每个账户的金额都是最新的,但是由于上面的步骤中出现了组合操作,即获取账户引用和更改账户引用,每个单独的操作虽然都是原子性的,但是组合在一起就不是原子性的了。所以最后的结果会出现偏差。
我们可以用如下线程切换图来表示一下这个过程的变化。
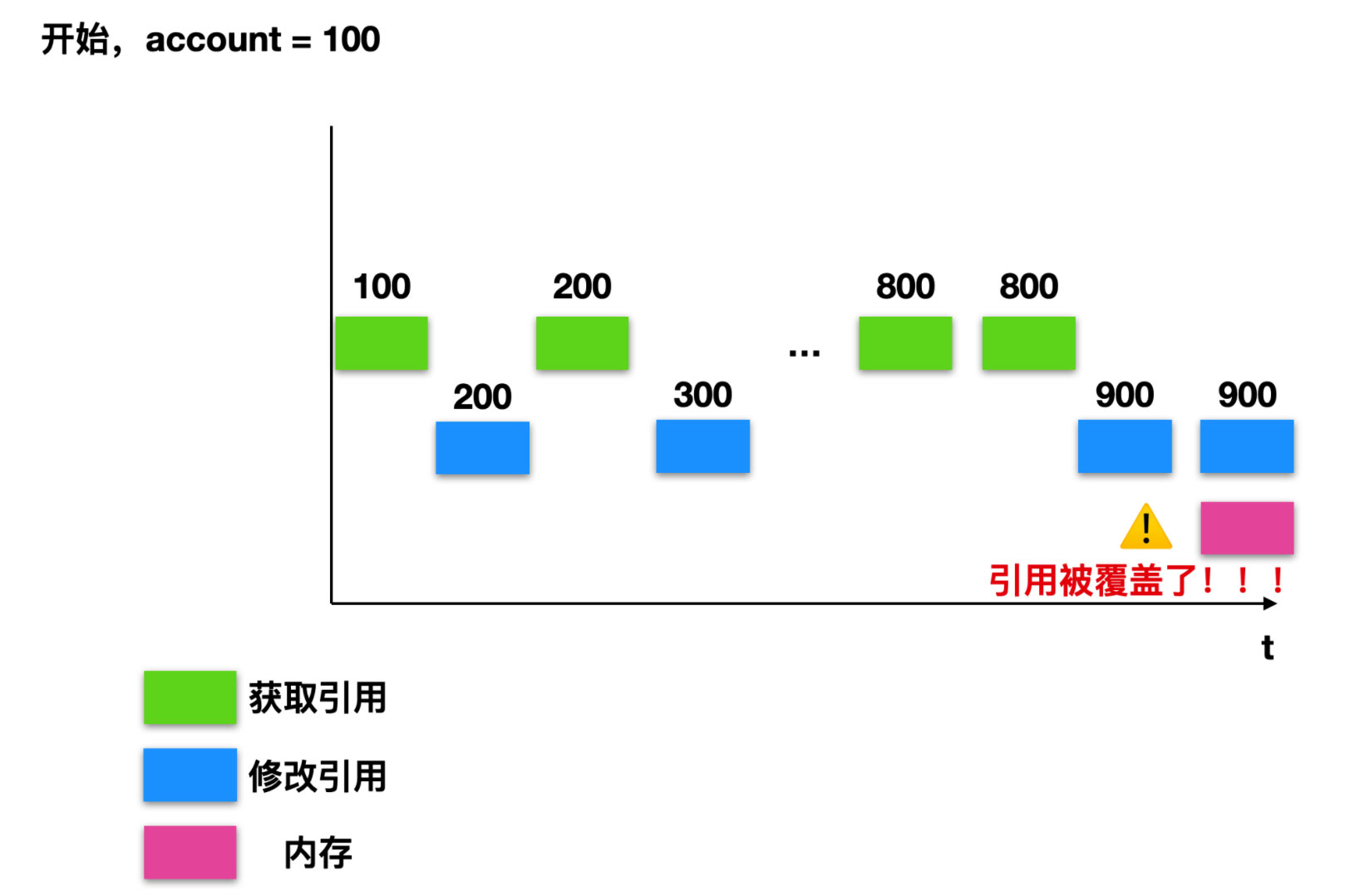
可以看到,最后的结果可能是因为在线程 t1 获取最新账户变化后,线程切换到 t2,t2 也获取了最新账户情况,然后再切换到 t1,t1 修改引用,线程切换到 t2,t2 修改引用,所以账户引用的值被修改了两次。
那么该如何确保获取引用和修改引用之间的线程安全性呢?
最简单粗暴的方式就是直接使用 synchronized 关键字进行加锁了。
1.1、使用 synchronized 保证线程安全性
使用 synchronized 可以保证共享数据的安全性,代码如下
public class BankCardSyncTest {
private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
synchronized (BankCardSyncTest.class) {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
相较于 BankCardTest ,BankCardSyncTest 增加了 synchronized 锁,运行 BankCardSyncTest 后我们发现能够得到正确的结果。
修改 BankCardSyncTest.class 为 bankCard 对象,我们发现同样能够确保线程安全性,这是因为在这段程序中,只有 bankCard 会进行变化,不会再有其他共享数据。
如果有其他共享数据的话,我们需要使用 BankCardSyncTest.clas 确保线程安全性。
除此之外,java.util.concurrent.atomic 包下的 AtomicReference 也可以保证线程安全性。
我们先来认识一下 AtomicReference ,然后再使用 AtomicReference 改写上面的代码。
二、了解 AtomicReference
2.1、使用 AtomicReference 保证线程安全性
下面我们改写一下上面的那个示例
public class BankCardARTest {
private static AtomicReference<BankCard> bankCardRef = new AtomicReference<>(new BankCard("cxuan",100));
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
while (true){
// 使用 AtomicReference.get 获取
final BankCard card = bankCardRef.get();
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
// 使用 CAS 乐观锁进行非阻塞更新
if(bankCardRef.compareAndSet(card,newCard)){
System.out.println(newCard);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
在上面的示例代码中,我们使用了 AtomicReference 封装了 BankCard 的引用,然后使用 get() 方法获得原子性的引用,接着使用 CAS 乐观锁进行非阻塞更新,更新的标准是如果使用 bankCardRef.get() 获取的值等于内存值的话,就会把银行卡账户的资金 + 100,我们观察一下输出结果。
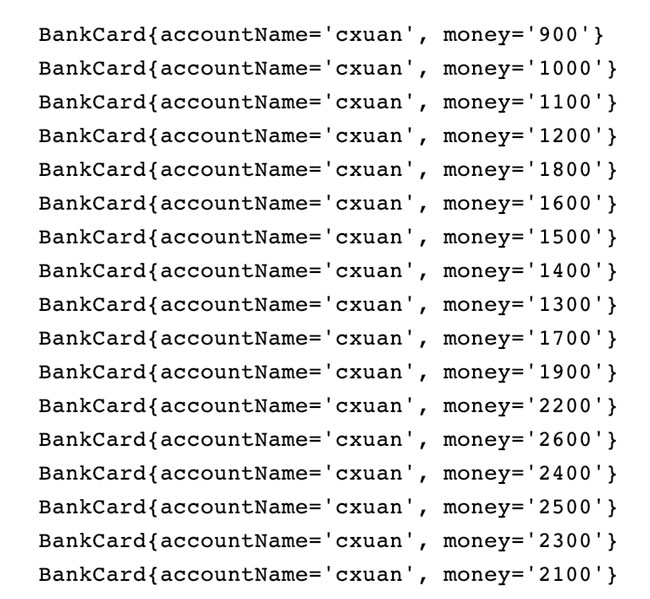
可以看到,有一些输出是乱序执行的,出现这个原因很简单,有可能在输出结果之前,进行线程切换,然后打印了后面线程的值,然后线程切换回来再进行输出,但是可以看到,没有出现银行卡金额相同的情况。
2.2、AtomicReference 源码解析
在了解上面这个例子之后,我们来看一下 AtomicReference 的使用方法
AtomicReference 和 AtomicInteger 非常相似,它们内部都是用了下面三个属性

Unsafe 是 sun.misc 包下面的类,AtomicReference 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的原子性。
Unsafe 的 objectFieldOffset 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。这个偏移量也就是 valueOffset ,说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作。
value 就是 AtomicReference 中的实际值,因为有 volatile ,这个值实际上就是内存值。
不同之处就在于 AtomicInteger 是对整数的封装,而 AtomicReference 则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性。
2.2.1、get and set
我们首先来看一下最简单的 get 、set 方法:
get() : 获取当前 AtomicReference 的值
set() : 设置当前 AtomicReference 的值
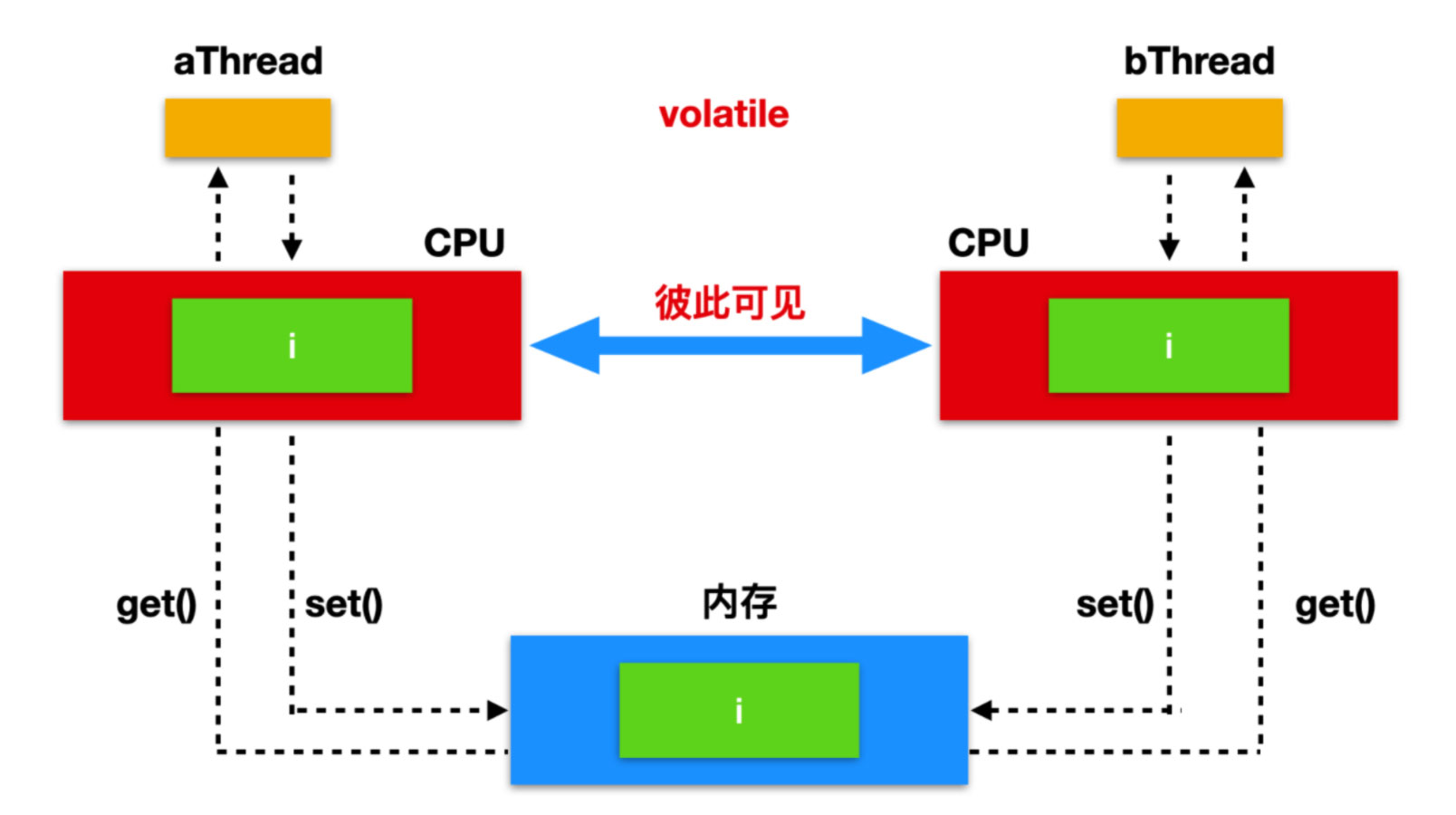
get() 可以原子性的读取 AtomicReference 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 volatile 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示
2.2.2、lazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
内存屏障,也称内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:懒得设置屏障了
2.2.3、getAndSet 方法
以原子方式设置为给定值并返回旧值。它的源码如下

它会调用 unsafe 中的 getAndSetObject 方法,源码如下

可以看到这个 getAndSet 方法涉及两个 cpp 实现的方法,一个是 getObjectVolatile ,一个是 compareAndSwapObject 方法,他们用在 do...while 循环中,也就是说,每次都会先获取最新对象引用的值,如果使用 CAS 成功交换两个对象的话,就会直接返回 var5 的值,var5 此时应该就是更新前的内存值,也就是旧值。
2.2.4、compareAndSet 方法
这就是 AtomicReference 非常关键的 CAS 方法了,与 AtomicInteger 不同的是,AtomicReference 是调用的 compareAndSwapObject ,而 AtomicInteger 调用的是 compareAndSwapInt 方法。这两个方法的实现如下

路径在 hotspot/src/share/vm/prims/unsafe.cpp 中。
我们之前解析过 AtomicInteger 的源码,所以我们接下来解析一下 AtomicReference 源码。
因为对象存在于堆中,所以方法 index_oop_from_field_offset_long 应该是获取对象的内存地址,然后使用 atomic_compare_exchange_oop 方法进行对象的 CAS 交换。
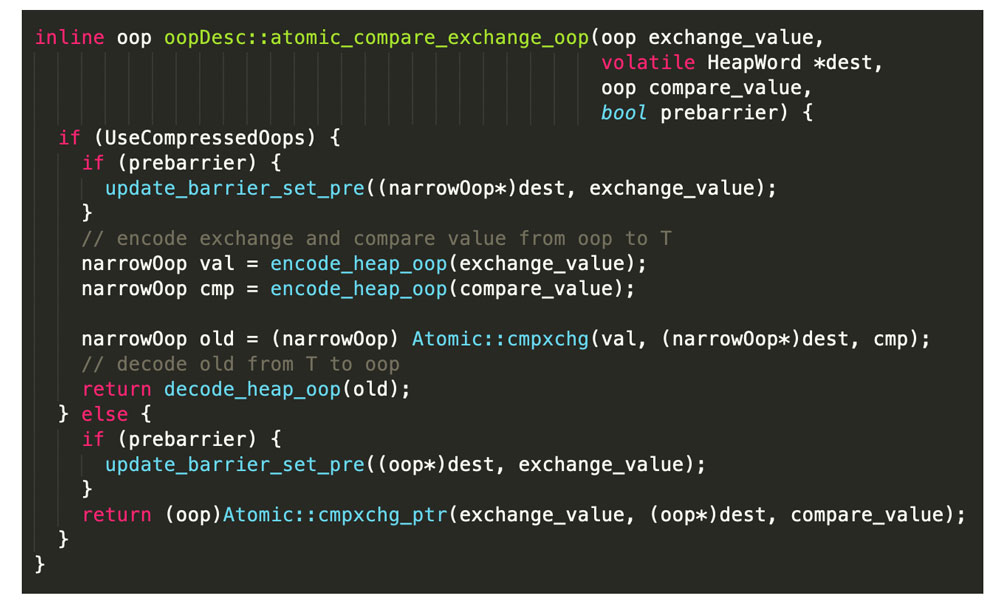
这段代码会首先判断是否使用了 UseCompressedOops,也就是指针压缩。
这里简单解释一下指针压缩的概念:JVM 最初的时候是 32 位的,但是随着 64 位 JVM 的兴起,也带来一个问题,内存占用空间更大了 ,但是 JVM 内存最好不要超过 32 G,为了节省空间,在 JDK 1.6 的版本后,我们在 64位中的 JVM 中可以开启指针压缩(UseCompressedOops)来压缩我们对象指针的大小,来帮助我们节省内存空间,在 JDK 8来说,这个指令是默认开启的。
如果不开启指针压缩的话,64 位 JVM 会采用 8 字节(64位)存储真实内存地址,比之前采用4字节(32位)压缩存储地址带来的问题:
- 增加了 GC 开销:64 位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,从而加快了 GC 的发生,更频繁的进行 GC。
- 降低 CPU 缓存命中率:64 位对象引用增大了,CPU 能缓存的 oop 将会更少,从而降低了 CPU 缓存的效率。
由于 64 位存储内存地址会带来这么多问题,程序员发明了指针压缩技术,可以让我们既能够使用之前 4 字节存储指针地址,又能够扩大内存存储。
可以看到,atomic_compare_exchange_oop 方法底层也是使用了 Atomic:cmpxchg 方法进行 CAS 交换,然后把旧值进行 decode 返回 (我这局限的 C++ 知识,只能解析到这里了,如果大家懂这段代码一定告诉我,让我请教一波)
2.2.5、weakCompareAndSet 方法
weakCompareAndSet: 非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。
但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

以上就是详解Java高并发编程之AtomicReference的详细内容,更多关于Java高并发编程 AtomicReference的资料请关注我们其它相关文章!
相关推荐
-
Java concurrency之AtomicReference原子类_动力节点Java学院整理
AtomicReference介绍和函数列表 AtomicReference是作用是对"对象"进行原子操作. AtomicReference函数列表 // 使用 null 初始值创建新的 AtomicReference. AtomicReference() // 使用给定的初始值创建新的 AtomicReference. AtomicReference(V initialValue) // 如果当前值 == 预期值,则以原子方式将该值设置为给定的更新值. boolean compare
-
深入了解Java atomic原子类的使用方法和原理
在讲atomic原子类之前先看一个小例子: public class UseAtomic { public static void main(String[] args) { AtomicInteger atomicInteger=new AtomicInteger(); for(int i=0;i<10;i++){ Thread t=new Thread(new AtomicTest(atomicInteger)); t.start(); try { t.join(0); } catch (I
-
Java多线程Atomic包操作原子变量与原子类详解
在阅读这篇文章之前,大家可以先看下<Java多线程atomic包介绍及使用方法>,了解atomic包的相关内容. 一.何谓Atomic? Atomic一词跟原子有点关系,后者曾被人认为是最小物质的单位.计算机中的Atomic是指不能分割成若干部分的意思.如果一段代码被认为是Atomic,则表示这段代码在执行过程中,是不能被中断的.通常来说,原子指令由硬件提供,供软件来实现原子方法(某个线程进入该方法后,就不会被中断,直到其执行完成) 在x86平台上,CPU提供了在指令执行期间对总线加锁的手段.
-
Java concurrency之AtomicLongArray原子类_动力节点Java学院整理
AtomicLongArray介绍和函数列表 AtomicLongArray函数列表 // 创建给定长度的新 AtomicLongArray. AtomicLongArray(int length) // 创建与给定数组具有相同长度的新 AtomicLongArray,并从给定数组复制其所有元素. AtomicLongArray(long[] array) // 以原子方式将给定值添加到索引 i 的元素. long addAndGet(int i, long delta) // 如果当前值 =
-
Java AtomicInteger类使用方法实例讲解
1.java.util.concurrent.atomic 的包里有AtomicBoolean, AtomicInteger,AtomicLong,AtomicLongArray, AtomicReference等原子类的类,主要用于在高并发环境下的高效程序处理,来帮助我们简化同步处理. 在Java语言中,++i和i++操作并不是线程安全的,在使用的时候,不可避免的会用到synchronized关键字.而AtomicInteger则通过一种线程安全的加减操作接口. 2.AtomicInteger
-
Java多线程atomic包介绍及使用方法
引言 Java从JDK1.5开始提供了java.util.concurrent.atomic包,方便程序员在多线程环境下,无锁的进行原子操作.原子变量的底层使用了处理器提供的原子指令,但是不同的CPU架构可能提供的原子指令不一样,也有可能需要某种形式的内部锁,所以该方法不能绝对保证线程不被阻塞. Atomic包介绍 在Atomic包里一共有12个类,四种原子更新方式,分别是原子更新基本类型,原子更新数组,原子更新引用和原子更新字段.Atomic包里的类基本都是使用Unsafe实现的包装类. 原子
-
Java中对AtomicInteger和int值在多线程下递增操作的测试
Java针对多线程下的数值安全计数器设计了一些类,这些类叫做原子类,其中一部分如下: java.util.concurrent.atomic.AtomicBoolean; java.util.concurrent.atomic.AtomicInteger; java.util.concurrent.atomic.AtomicLong; java.util.concurrent.atomic.AtomicReference; 下面是一个对比 AtomicInteger 与 普通 int 值在多线
-
Java AtomicInteger类的使用方法详解
首先看两段代码,一段是Integer的,一段是AtomicInteger的,为以下: public class Sample1 { private static Integer count = 0; synchronized public static void increment() { count++; } } 以下是AtomicInteger的: public class Sample2 { private static AtomicInteger count = new AtomicIn
-

浅谈Java中的atomic包实现原理及应用
1.同步问题的提出 假设我们使用一个双核处理器执行A和B两个线程,核1执行A线程,而核2执行B线程,这两个线程现在都要对名为obj的对象的成员变量i进行加1操作,假设i的初始值为0,理论上两个线程运行后i的值应该变成2,但实际上很有可能结果为1. 我们现在来分析原因,这里为了分析的简单,我们不考虑缓存的情况,实际上有缓存会使结果为1的可能性增大.A线程将内存中的变量i读取到核1算数运算单元中,然后进行加1操作,再将这个计算结果写回到内存中,因为上述操作不是原子操作,只要B线程在A线程将i增加1的
-
详解Java高并发编程之AtomicReference
目录 一.AtomicReference 基本使用 1.1.使用 synchronized 保证线程安全性 二.了解 AtomicReference 2.1.使用 AtomicReference 保证线程安全性 2.2.AtomicReference 源码解析 2.2.1.get and set 2.2.2.lazySet 方法 2.2.3.getAndSet 方法 2.2.4.compareAndSet 方法 2.2.5.weakCompareAndSet 方法 一.AtomicReferen
-
详解Java高阶语法Volatile
背景:听说Volatile Java高阶语法亦是挺进BAT的必经之路. Volatile: volatile同步机制又涉及Java内存模型中的可见性.原子性和有序性,恶补基础一波. 可见性: 可见性简单的说是线程之间的可见性,一个线程修改的状态对另一个线程是可见对,也就是一个线程的修改结果另一个线程可以马上看到:但通常,我们无法确保执行读操作的线程能够时时的看到其他线程写入的值,So为了确保多个线程之间对内存写入操作可见性,必须使用同步机制:如用volatile修饰的变量就具有可见性,volat
-
Springboot实现高吞吐量异步处理详解(适用于高并发场景)
技术要点 org.springframework.web.context.request.async.DeferredResult<T> 示例如下: 1. 新建Maven项目 async 2. pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaL
-
详解nginx高并发场景下的优化
在日常的运维工作中,经常会用到nginx服务,也时常会碰到nginx因高并发导致的性能瓶颈问题.今天这里简单梳理下nginx性能优化的配置(仅仅依据本人的实战经验而述,如有不妥,敬请指出~) 一.这里的优化主要是指对nginx的配置优化,一般来说nginx配置文件中对优化比较有作用的主要有以下几项: 1)nginx进程数,建议按照cpu数目来指定,一般跟cpu核数相同或为它的倍数. worker_processes 8; 2)为每个进程分配cpu,上例中将8个进程分配到8个cpu,当然可以写多个
-
详解JAVA高质量代码之数组与集合
1.性能考虑,优先选择数组 数组在项目开发当中使用的频率是越来越少,特别是在业务为主的开发当中,首先数组没有List,Set等集合提供的诸多方法,查找增加算法都要自己编写,极其繁琐麻烦,但由于List,Set等集合使用泛型支持后,存放的都为包装类,而数组是可以使用基本数据类型,而使用基本数据类型的执行运算速度要比包装类型快得多,而且集合类的底层也是通过数组进行实现. 2.若有必要,使用变长数组 在学习集合类当中,很多人喜欢将数组的定长拿来和集合类型的自变长来做比较,但其实这种比较并不合适,通过观
-
详解Java程序并发的Wait-Notify机制
Wait-Notify场景 典型的Wait-Notify场景一般与以下两个内容相关: 1. 状态变量(State Variable) 当线程需要wait的时候,总是因为一些条件得不到满足导致的.例如往队列里填充数据,当队列元素已经满时,线程就需要wait停止运行.当队列元素有空缺时,再继续自己的执行. 2. 条件断言(Condition Predicate) 当线程确定是否进入wait或者是从notify醒来的时候是否继续往下执行,大部分都要测试状态条件是否满足.例如,往队列里添加元素,队列已满
-
java并发编程之cas详解
CAS(Compare and swap)比较和替换是设计并发算法时用到的一种技术.简单来说,比较和替换是使用一个期望值和一个变量的当前值进行比较,如果当前变量的值与我们期望的值相等,就使用一个新值替换当前变量的值.这听起来可能有一点复杂但是实际上你理解之后发现很简单,接下来,让我们跟深入的了解一下这项技术. CAS的使用场景 在程序和算法中一个经常出现的模式就是"check and act"模式.先检查后操作模式发生在代码中首先检查一个变量的值,然后再基于这个值做一些操作.下面是一个
-
Java并发编程之Semaphore(信号量)详解及实例
Java并发编程之Semaphore(信号量)详解及实例 概述 通常情况下,可能有多个线程同时访问数目很少的资源,如客户端建立了若干个线程同时访问同一数据库,这势必会造成服务端资源被耗尽的地步,那么怎样能够有效的来控制不可预知的接入量呢?及在同一时刻只能获得指定数目的数据库连接,在JDK1.5 java.util.concurrent 包中引入了Semaphore(信号量),信号量是在简单上锁的基础上实现的,相当于能令线程安全执行,并初始化为可用资源个数的计数器,通常用于限制可以访问某些资源(物
-
Java并发编程之Exchanger方法详解
简介 Exchanger是一个用于线程间数据交换的工具类,它提供一个公共点,在这个公共点,两个线程可以交换彼此的数据. 当一个线程调用exchange方法后将进入等待状态,直到另外一个线程调用exchange方法,双方完成数据交换后继续执行. Exchanger的使用 方法介绍 exchange(V x):阻塞当前线程,直到另外一个线程调用exchange方法或者当前线程被中断. x : 需要交换的对象. exchange(V x, long timeout, TimeUnit unit):阻塞
-
Java并发编程之LockSupport类详解
一.LockSupport类的属性 private static final sun.misc.Unsafe UNSAFE; // 表示内存偏移地址 private static final long parkBlockerOffset; // 表示内存偏移地址 private static final long SEED; // 表示内存偏移地址 private static final long PROBE; // 表示内存偏移地址 private static final long SEC