端午节将至,用Python爬取粽子数据并可视化,看看网友喜欢哪种粽子吧!
一、前言
本文就从数据爬取、数据清洗、数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用。
整个思路如下:
- 爬取网页:https://www.jd.com/
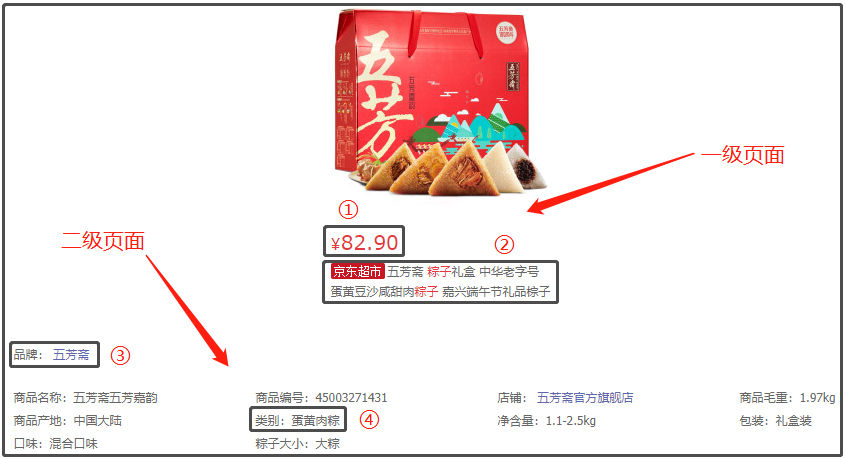
- 爬取说明: 基于京东网站,我们搜索网站“粽子”数据,大概有100页。我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息;
- 爬取思路: 先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作;
- 爬取字段: 分别是粽子的名称(标题)、价格、品牌(店铺)、类别(口味);
- 使用工具: requests+lxml+pandas+time+re+pyecharts
- 网站解析方式: xpath
最终的效果如下:

二、数据爬取
京东网站,一般是动态加载的,也就是说,采用一般方式只能爬取到某个页面的前30个数据(一个页面一共60个数据)。
基于本文,我仅用最基本的方法,爬取了每个页面的前30条数据(如果大家有兴趣,可以自行下去爬取所有的数据)。
那么,本文究竟爬取了哪些字段呢?我给大家做一个展示,大家有兴趣,可以爬取更多的字段,做更为详细的分析。
下面为大家展示爬虫代码:
import pandas as pd
import requests
from lxml import etree
import chardet
import time
import re
def get_CI(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
rqg = requests.get(url,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 价格
p_price = html.xpath('//div/div[@class="p-price"]/strong/i/text()')
# 名称
p_name = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/em')
p_name = [str(p_name[i].xpath('string(.)')) for i in range(len(p_name))]
# 深层url
deep_ur1 = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/@href')
deep_url = ["http:" + i for i in deep_ur1]
# 从这里开始,我们获取“二级页面”的信息
brands_list = []
kinds_list = []
for i in deep_url:
rqg = requests.get(i,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 品牌
brands = html.xpath('//div/div[@class="ETab"]//ul[@id="parameter-brand"]/li/@title')
brands_list.append(brands)
# 类别
kinds = re.findall('>类别:(.*?)</li>',rqg.text)
kinds_list.append(kinds)
data = pd.DataFrame({'名称':p_name,'价格':p_price,'品牌':brands_list,'类别':kinds_list})
return(data)
x = "https://search.jd.com/Search?keyword=%E7%B2%BD%E5%AD%90&qrst=1&wq=%E7%B2%BD%E5%AD%90&stock=1&page="
url_list = [x + str(i) for i in range(1,200,2)]
res = pd.DataFrame(columns=['名称','价格','品牌','类别'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
最终爬取到的数据:

三、数据清洗
从上图可以看到,整个数据算是很整齐的,不是特别乱,我们只做一些简单的操作即可。
先使用pandas库,来读取数据。
import pandas as pd
df = pd.read_excel("粽子.xlsx",index_col=False)
df.head()
结果如下:

我们分别针对 “品牌”、“类别” 两个字段,去掉中括号。
df["品牌"] = df["品牌"].apply(lambda x: x[1:-1]) df["类别"] = df["类别"].apply(lambda x: x[1:-1]) df.head()
结果如下:

① 粽子品牌排名前10的店铺
df["品牌"].value_counts()[:10]
结果如下:

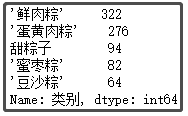
② 粽子口味排名前5的味道
def func1(x):
if x.find("甜") > 0:
return "甜粽子"
else:
return x
df["类别"] = df["类别"].apply(func1)
df["类别"].value_counts()[1:6]
结果如下:
③ 粽子售卖价格区间划分
def price_range(x): # 按照我的购物习惯,划分价格 if x <= 50: return '<50元' elif x <= 100: return '50-100元' elif x <= 300: return '100-300元' elif x <= 500: return '300-500元' elif x <= 1000: return '500-1000元' else: return '>1000元' df["价格区间"] = df["价格"].apply(price_range) df["价格区间"].value_counts()
结果如下:

由于数据不是很多,没有很多字段,也就没有很多乱数据。因此,这里也没有做数据去重、缺失值填充等操作。所以,大家可以下去获取更多字段,更多数据,用于数据分析。
四、数据可视化
俗话说:字不如表,表不如图。通过可视化分析,我们可以将数据背后 “隐藏” 的信息,给展现出来。
拓展: 当然,这里只是 “抛砖引玉”,我并没有获取太多的数据,也没有获取太多的字段。这里给学习的朋友当一个作业题,自己下去用更多的数据、更多的字段,做更透彻的分析。
在这里,我们基于以下几个问题,做一个可视化展示,分别是:
- ① 粽子销售店铺Top10柱形图;
- ② 粽子口味排名Top5柱形图;
- ③ 粽子销售价格区间划分饼图;
- ④ 粽子商品名称词云图;
① 粽子销售店铺Top10柱形图
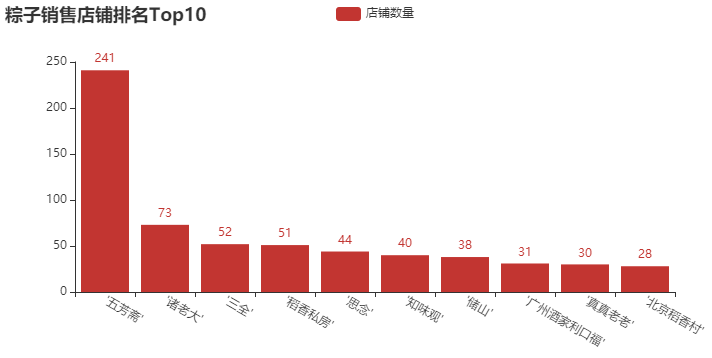
结论分析:去年,我们分析了一些月饼的数据,“五芳斋”、“北京稻香村” 这几个牌子记忆犹新,可谓是做月饼、粽子的老店。像 “三全” 和 “思念”,在我印象中一直以为它们只做水饺和汤圆,粽子是否值得一试呢?当然,这里还有一些新的牌子,像 “诸老大”、“稻香私房” 等一些牌子,大家都可以下去搜索一下。买东西,就是要精挑细选,品牌也重要。
② 粽子口味排名Top5柱形图
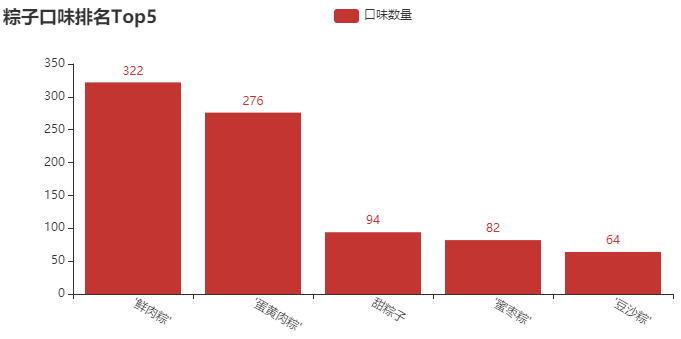
结论分析:在我印象中,小时候一直吃的最多的就是 “甜粽子”,直到我上了初中才知道,粽子还可以有肉?当然,从图中可以看出,卖 “鲜肉粽” 的店铺还是居多,毕竟这个送人,还是显得高端、大气一些。这里还有一些口味,像 “蜜枣粽”、“豆沙粽”,我基本没吃过。如果你送人,你会送什么口味的呢?
③ 粽子销售价格区间划分饼图

结论分析:这里,我故意把价格区间细分。这个饼图也很符合实际,毕竟每年就过一次端午节,还是以薄利多销为主,接近80%的粽子,售价都在100元以下。当然,还有一些中档的粽子,价格在100-300元。大于300元,我觉得也没有吃的必要,反正我是不会花这么多钱去买粽子。
④ 粽子商品名称词云图

结论分析:从图中,可以大致看出商家的卖点了。毕竟是节日,“送礼”、“礼品” 体现了节日氛围。“猪肉”、“豆沙” 体现了粽子口味。当然,它是否是 “早餐” 好选择呢?购买的话,还支持 “团购” 哦。这些字眼,多多少少都会各自吸引一部分人的眼球。
⑤ 图形组合为大屏
到此这篇关于端午节将至,用Python将粽子数据可视化,看看网友喜欢哪种吧!的文章就介绍到这了,更多相关Python数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum
-

Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
python如何爬取网站数据并进行数据可视化
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥和扩展包括各种分析和不同的存储方式等..... 一.爬取和分析相关依赖包 Python版本: Python3.6 requests: 下载网页 math: 向上取整 time: 暂停进程 pandas:数据分析并保存为csv文件 matplotlib:
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
端午节将至,用Python爬取粽子数据并可视化,看看网友喜欢哪种粽子吧!
一.前言 本文就从数据爬取.数据清洗.数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用. 整个思路如下: 爬取网页:https://www.jd.com/ 爬取说明: 基于京东网站,我们搜索网站"粽子"数据,大概有100页.我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息: 爬取思路: 先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作: 爬取字段: 分别是粽子的名称(标题).价格.品牌(店
-
Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
python 爬取疫情数据的源码
疫情数据 程序源码 // An highlighted block import requests import json class epidemic_data(): def __init__(self, province): self.url = url self.header = header self.text = {} self.province = province # self.r=None def down_page(self): r = requests.get(url=url
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b
-
使用Python爬取Json数据的示例代码
一年一度的双十一即将来临,临时接到了一个任务:统计某品牌数据银行中自己品牌分别在2017和2018的10月20日至10月31日之间不同时间段的AIPL("认知"(Aware)."兴趣"(Interest)."购买"(Purchase)."忠诚"(Loyalty))流转率. 使用Fiddler获取到目标地址为: https://databank.yushanfang.com/api/ecapi?path=/databank/cr
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
Python爬虫爬取疫情数据并可视化展示
目录 知识点 开发环境 爬虫完整代码 导入模块 分析网站 发送请求 获取数据 解析数据 保存数据 数据可视化 导入模块 读取数据 死亡率与治愈率 各地区确诊人数与死亡人数情况 知识点 爬虫基本流程 json requests 爬虫当中 发送网络请求 pandas 表格处理 / 保存数据 pyecharts 可视化 开发环境 python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性 pycharm 专业代码编辑器 按照年份与月
-
python爬取网页数据到保存到csv
目录 任务需求: 爬取网址: 网址页面: 代码实现结果: 代码实现: 完整代码: 总结 任务需求: 爬取一个网址,将网址的数据保存到csv中. 爬取网址: https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title 网址页面: 代码实现结果: 代码实现: 导入包: import requests import parsel import csv 设置csv文件格
-
Python实现爬取天气数据并可视化分析
目录 核心功能设计 实现步骤 爬取数据 风向风级雷达图 温湿度相关性分析 24小时内每小时时段降水 24小时累计降雨量 今天我们分享一个小案例,获取天气数据,进行可视化分析,带你直观了解天气情况! 核心功能设计 总体来说,我们需要先对中国天气网中的天气数据进行爬取,保存为csv文件,并将这些数据进行可视化分析展示. 拆解需求,大致可以整理出我们需要分为以下几步完成: 1.通过爬虫获取中国天气网7.20-7.21的降雨数据,包括城市,风力方向,风级,降水量,相对湿度,空气质量. 2.对获取的天气数