python之tensorflow手把手实例讲解斑马线识别实现
一,斑马线的数据集
数据集的构成:
| test | train |
|---|---|
| zebra corssing:56 | zebra corssing:168 |
| other:54 | other:164 |
二,代码部分
1.导包
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt import keras
2.数据导入
train_dir=r'C:\Users\zx\深度学习\Zebra\train'
test_dir=r'C:\Users\zx\深度学习\Zebra\test'
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=10, #旋转
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(train_dir,
(50,50),
batch_size=1,
class_mode='binary',
shuffle=False)
test_datagen = ImageDataGenerator(rescale=1/255)
test_generator = test_datagen.flow_from_directory(test_dir,
(50,50),
batch_size=1,
class_mode='binary',
shuffle=False)
3.搭建模型
模型的建立仁者见智,可自己调节寻找更好的模型。
model = tf.keras.models.Sequential([
# 第一层卷积,卷积核为,共16个,输入为150*150*1
tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same',input_shape=(50,50,3)),
tf.keras.layers.MaxPooling2D((2,2)),
# 第二层卷积,卷积核为3*3,共32个,
tf.keras.layers.Conv2D(32,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
# 第三层卷积,卷积核为3*3,共64个,
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
# 第四层卷积,卷积核为3*3,共128个
# tf.keras.layers.Conv2D(128,(3,3),activation='relu'),
# tf.keras.layers.MaxPooling2D((2,2)),
# 数据铺平
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(16,activation='relu'),
tf.keras.layers.Dense(2,activation='softmax')
])
print(model.summary())
model.compile(optimize='adam',
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['acc'])
4,模型训练
history = model.fit(train_generator,
epochs=20,
verbose=1)
model.save('./Zebra.h5')
模型训练过程:

可以看到我们的模型在20轮的训练后acc从0.63上升到了0.96左右。
5,模型评估
model.evaluate(test_generator)

#可视化
plt.plot(history.history['acc'], label='accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.7, 1])
plt.legend(loc='lower right')
plt.title('acc')
plt.show()

6,模型预测
虽然我们的模型在训练过程中acc一度达到0.96,但测试集才是检验模型的唯一标准,在model.evaluate(test_generator)中的评分只有0.91左右,说明我们的模型已经能以很高的正确率来完成”斑马线“与“非斑马线”的二分类问题了,但我们还是要查看具体是哪些数据没有被模型正确得识别。
pred=model.predict(test_generator) #获取test集的输出 filenames = test_generator.filenames #获取test数据的文件名
错误输出过程:
- 1,循环测试集长度,通过if语句先判断others还是zebra,再通过one-hot编码判断是否预测正确。
- 2,根据labels可知others': 0, 'zebra crossing': 1,以此来判断是否预测正确。
- 3,对 filenames[0]='others\\103.png',进行切片处理。
- 4,找到others的‘s'或 zebra crossing的‘g',使用find()在基础上+2为正切片的起点(样本编号前有'\'符号,故+2才能正确取出编号)。
- 5,如 :将filenames[i]的值赋给a,a[int(a.find('s')+2):]则表示为 'xx.png'。
- 6,将取出的样本编号与路径拼接,读取后作图。
- 7,break跳出循环。
for i in range(len(filenames)):
if filenames[i][:6]=='others':
if np.argmax(pred[i]) != 0:
a=filenames[i]
plt.figure()
print('预测错误的图片:'+a[int(a.find('s')+2):])
print('错误识别为"zebra crossing",正确类型是"others"')
print('预测标签为:'+str(np.argmax(pred[i]))+',真实标签为:0')
img = plt.imread('Zebra/test/others/'+a[int(a.find('s')+2):])
plt.imshow(img)
plt.title(a[int(a.find('s')+2):])
plt.grid(False)
break
if filenames[i][:6]=='zebra ':
if np.argmax(pred[i]) != 1:
b= filenames[i]
plt.figure()
print('预测错误的图片:'+b[int(b.find('g')+2):])
print('错误识别为"others",正确类型是"zebra crossing"')
print('预测标签为:'+str(np.argmax(pred[i]))+',真实标签为:1')
img = plt.imread('Zebra/test/zebra crossing/'+b[int(b.find('g')+2):])
plt.imshow(img)
plt.title(b[int(b.find('g')+2):])
plt.grid(False)
break

看到这个错误样本,我猜想可能是因为斑马线的部分只占了图像的一半左右,所以预测错误了。
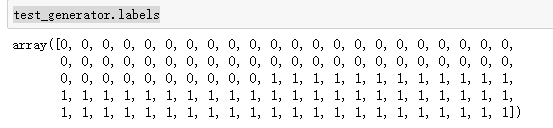
这里是我做预测判断的思路,本可以不这么复杂的可以用test_generator.labels来获取数据的标签,再做判断。
test_generator.labels
上面只输出了第一个错误的样本,所以接下来我们要看所有错误预测的样本
sum=0
for i in range(len(filenames)):
if filenames[i][:6]=='others':
if np.argmax(pred[i]) != 0:
a=filenames[i]
print('预测错误的图片:'+a[int(a.find('s')+2):]+',错误识别为"zebra crossing",正确类型是"others"')
sum=sum+1
if filenames[i][:6]=='zebra ':
if np.argmax(pred[i]) != 1:
b= filenames[i]
print('预测错误的图片:'+b[int(b.find('g')+2):]+',错误识别为"others",正确类型是"zebra crossing"')
sum=sum+1
print('错误率:'+str(sum/100)+'%')
print('正确率:'+str((10000-sum)/100)+'%')

三,分析
在构建模型时我尝试在最后一层只用一个神经元,用sigmoid激活函数,其他参数不变,在同样epochs=20的条件,也能很快收敛,达到很高的acc,测试集的评分也能在0.9左右,但是在最后输出全部错误样本的时候发现错误的样本远超过softmax,可能其中有些参数我没有根据sigmoid来调整,所以会有如此高的错误率,欢迎在评论区讨论。
到此这篇关于python之tensorflow手把手实例讲解斑马线识别实现的文章就介绍到这了,更多相关python tensorflow 斑马线识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Tensorflow搭建一个神经网络的实现
一.Tensorlow结构 import tensorflow as tf import numpy as np #创建数据 x_data = np.random.rand(100).astype(np.float32) y_data = x_data*0.1+0.3 #创建一个 tensorlow 结构 weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#一维,范围[-1,1] biases = tf.Variable(tf.zer
-
tensorflow之自定义神经网络层实例
如下所示: import tensorflow as tf tfe = tf.contrib.eager tf.enable_eager_execution() 大多数情况下,在为机器学习模型编写代码时,您希望在比单个操作和单个变量操作更高的抽象级别上操作. 1.关于图层的一些有用操作 许多机器学习模型可以表达为相对简单的图层的组合和堆叠,TensorFlow提供了一组许多常用图层,以及您从头开始或作为组合创建自己的应用程序特定图层的简单方法.TensorFlow在tf.keras包中包含完整的
-
tensorflow2.0实现复杂神经网络(多输入多输出nn,Resnet)
常见的'融合'操作 复杂神经网络模型的实现离不开"融合"操作.常见融合操作如下: (1)求和,求差 # 求和 layers.Add(inputs) # 求差 layers.Subtract(inputs) inputs: 一个输入张量的列表(列表大小至少为 2),列表的shape必须一样才能进行求和(求差)操作. 例子: input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='rel
-
使用TensorFlow搭建一个全连接神经网络教程
说明 本例子利用TensorFlow搭建一个全连接神经网络,实现对MNIST手写数字的识别. 先上代码 from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf # prepare data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) xs = tf.placeholder(tf.float32, [None,
-
python 使用Tensorflow训练BP神经网络实现鸢尾花分类
Hello,兄弟们,开始搞深度学习了,今天出第一篇博客,小白一枚,如果发现错误请及时指正,万分感谢. 使用软件 Python 3.8,Tensorflow2.0 问题描述 鸢尾花主要分为狗尾草鸢尾(0).杂色鸢尾(1).弗吉尼亚鸢尾(2). 人们发现通过计算鸢尾花的花萼长.花萼宽.花瓣长.花瓣宽可以将鸢尾花分类. 所以只要给出足够多的鸢尾花花萼.花瓣数据,以及对应种类,使用合适的神经网络训练,就可以实现鸢尾花分类. 搭建神经网络 输入数据是花萼长.花萼宽.花瓣长.花瓣宽,是n行四列的矩阵. 而输
-
python之tensorflow手把手实例讲解斑马线识别实现
一,斑马线的数据集 数据集的构成: test train zebra corssing:56 zebra corssing:168 other:54 other:164 二,代码部分 1.导包 import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt import ker
-
python之tensorflow手把手实例讲解猫狗识别实现
目录 一,猫狗数据集数目构成 二,数据导入 三,数据集构建 四,模型搭建 五,模型训练 六,模型测试 作为tensorflow初学的大三学生,本次课程作业的使用猫狗数据集做一个二分类模型. 一,猫狗数据集数目构成 train cats:1000 ,dogs:1000 test cats: 500,dogs:500 validation cats:500,dogs:500 二,数据导入 train_dir = 'Data/train' test_dir = 'Data/test' validati
-
python用户管理系统的实例讲解
学Python这么久了,第一次写一个这么多的代码(我承认只有300多行,重复的代码挺多的,我承认我确实垃圾),但是也挺不容易的 自定义函数+装饰器,每一个模块写的一个函数 很多地方能用装饰器(逻辑跟不上,有的地方没用),包括双层装饰器(不会),很多地方需要优化,重复代码太多 我还是把我的流程图拿出来吧,虽然看着比上次的垃圾,但是我也做了一个小时,不容易! 好像是挺丑的(表示不会画,但我下次一定努力) 用户文件: 文件名为:user.txt 1代表管理员用户 2代表普通用户 smelond|adm
-
OpenCV+python手势识别框架和实例讲解
基于OpenCV2.4.8和 python 2.7实现简单的手势识别. 以下为基本步骤 1.去除背景,提取手的轮廓 2. RGB->YUV,同时计算直方图 3.进行形态学滤波,提取感兴趣的区域 4.找到二值化的图像轮廓 5.找到最大的手型轮廓 6.找到手型轮廓的凸包 7.标记手指和手掌 8.把提取的特征点和手势字典中的进行比对,然后判断手势和形状 提取手的轮廓 cv2.findContours() 找到最大凸包cv2.convexHull(),然后找到手掌和手指的相对位置,定位手型的轮廓和关键点
-
Python 模拟购物车的实例讲解
1.功能简介 此程序模拟用户登陆商城后购买商品操作.可实现用户登陆.商品购买.历史消费记查询.余额和消费信息更新等功能.首次登陆输入初始账户资金,后续登陆则从文件获取上次消费后的余额,每次购买商品后会扣除相应金额并更新余额信息,退出时也会将余额和消费记录更新到文件以备后续查询. 2.实现方法 架构: 本程序采用python语言编写,将各项任务进行分解并定义对应的函数来处理,从而使程序结构清晰明了.主要编写了六个函数: (1)login(name,password) 用户登陆函数,实现用户名和密码
-
Python文件和流(实例讲解)
1.文件写入 #打开文件,路径不对会报错 f = open(r"C:\Users\jm\Desktop\pyfile.txt","w") f.write("Hello,world!\n") f.close() 2.文件读取 #读取 f = open(r"C:\Users\jm\Desktop\pyfile.txt","r") print(f.read()) f.close() 输出: Hello,world
-
python之Character string(实例讲解)
1.python字符串 字符串是 Python 中最常用的数据类型.我们可以使用引号('或")来创建字符串,l Python不支持单字符类型,单字符也在Python也是作为一个字符串使用. >>> var1 = 'hello python' #定义字符串 >>> print(var1[0]) #切片截取,从0开始,不包括截取尾数 h >>> print(var1[0:5]) hello >>> print(var1[-6:]
-
在Windows中设置Python环境变量的实例讲解
在 Windows 设置环境变量 在环境变量中添加Python目录: 在命令提示框中(cmd) : 输入 path=%path%;C:\Python 按下"Enter". 注意: C:\Python 是Python的安装目录. 也可以通过以下方式设置: • 右键点击"计算机",然后点击"属性" • 然后点击"高级系统设置" • 选择"系统变量"窗口下面的"Path",双击即可! • 然后
-
使用Python读取二进制文件的实例讲解
目标:目标文件为一个float32型存储的二进制文件,按列优先方式存储.本文使用Python读取该二进制文件并使用matplotlib.pyplot相关工具画出图像 工具:Python3, matplotlib,os,struct,numpy 1. 读取二进制文件 首先使用open函数打开文件,打开模式选择二进制读取"rb". f = open(filename, "rb") 第二步,需要打开按照行列读取文件,由于是纯二进制文件,内部不含邮任何的数据结构信息,因此我
-
python 列表降维的实例讲解
列表降维(python:3.x) 之前遇到需要使用列表降维的情况, 如: 原列表 : [[12,34],[57,86,1],[43,22,7],[1,[2,3]],6] 转化为 : [12, 34, 57, 86, 1, 43, 22, 7, 1, 2, 3, 6] 思路: 把列表转化为字符串,直接去掉 "[" 和 "]" 最后由字符串转化为列表 a = [[12,34],[57,86,1],[43,22,7],[1,[2,3]],6] #把列表转为字符串 b =