MySQL中limit对查询语句性能的影响
一,前言
首先说明一下MySQL的版本:
mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.17 | +-----------+ 1 row in set (.00 sec)
表结构:
mysql> desc test; +--------+---------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+---------------------+------+-----+---------+----------------+ | id | bigint(20) unsigned | NO | PRI | NULL | auto_increment | | val | int(10) unsigned | NO | MUL | | | | source | int(10) unsigned | NO | | | | +--------+---------------------+------+-----+---------+----------------+ 3 rows in set (.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test; +----------+ | count(*) | +----------+ | 5242882 | +----------+ 1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5; +---------+-----+--------+ | id | val | source | +---------+-----+--------+ | 3327622 | 4 | 4 | | 3327632 | 4 | 4 | | 3327642 | 4 | 4 | | 3327652 | 4 | 4 | | 3327662 | 4 | 4 | +---------+-----+--------+ 5 rows in set (15.98 sec)
为了达到相同的目的,我们一般会改写成如下语句:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id; +---------+-----+--------+---------+ | id | val | source | id | +---------+-----+--------+---------+ | 3327622 | 4 | 4 | 3327622 | | 3327632 | 4 | 4 | 3327632 | | 3327642 | 4 | 4 | 3327642 | | 3327652 | 4 | 4 | 3327652 | | 3327662 | 4 | 4 | 3327662 | +---------+-----+--------+---------+ 5 rows in set (.38 sec)
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
查询到索引叶子节点数据。
根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
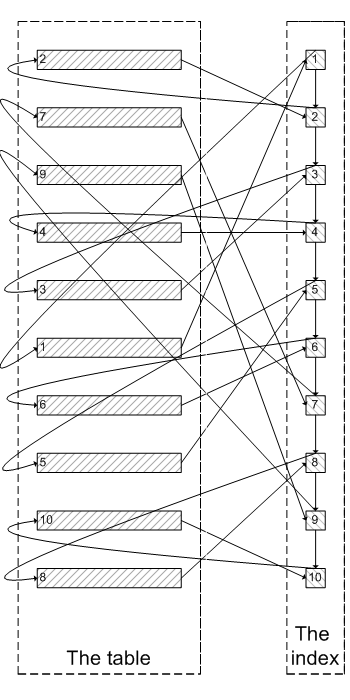
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
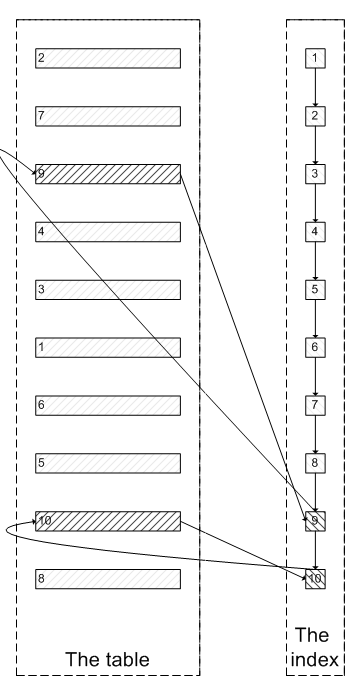
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5)之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5)为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
运行SQL:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
参考资料:
1.https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
2.https://dev.mysql.com/doc/refman/5.7/en/innodb-information-schema-buffer-pool-tables.html
更多关于SQL执行效率问题请查看下面的相关文章
相关推荐
-
mysql踩坑之limit与sum函数混合使用问题详解
前言 今天同事在同步完订单数据后,由于订单总金额和数据源的总金额存在差异,选择使用LIMIT和SUM()函数计算当前分页的总金额来和对方比较特定订单的总金额,却发现计算出来的金额并不是分页的订单总金额,而是所有订单的总金额. 数据库版本为mysql 5.7,下面会用一个示例复盘遇到的问题. 问题复盘 本次复盘会用一个很简单的订单表作为示例. 数据准备 订单表建表语句如下(这里偷懒了,使用了自增ID,实际开发中不建议使用自增ID作为订单ID) CREATE TABLE `order` ( `id`
-
为什么MySQL分页用limit会越来越慢
目录 一.测试实验 二. 对limit分页问题的性能优化方法 2.1 利用表的覆盖索引来加速分页查询 2.2 利用 id>=的形式: 2.3 利用join 总结: 阿牛新入职了一家新公司,第一个任务是根据条件导出订单表中的数据到文件中,阿牛心想:这也太简单了,于是很快写好了如下语句,并且告诉测试自己的代码是免测产品. 语句如下: select * from orders where name='lilei' and create_time>'2020-01-01 00:00:00' limit
-

mysql分页的limit参数简单示例
Mysql的分页的两个参数 select * from user limit 1,2 1表示从第几条数据开始查(默认索引是0,如果写1,从第二条开始查) 2,表示这页显示几条数据 到此这篇关于mysql分页的limit参数的文章就介绍到这了,更多相关mysql分页limit参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
mysql优化之query_cache_limit参数说明
query_cache_limit query_cache_limit指定单个查询能够使用的缓冲区大小,缺省为1M. 优化query_cache_size 从4.0.1开始,MySQL提供了查询缓冲机制.使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,今后对于同样的 SELECT语句(区分大小写),将直接从缓冲区中读取结果.根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率. 通过检查状态值Qcache_*,可以知道query_cache_size设置是否合理(上
-
MySQL查询优化:LIMIT 1避免全表扫描提高查询效率
在某些情况下,如果明知道查询结果只有一个,SQL语句中使用LIMIT 1会提高查询效率. 例如下面的用户表(主键id,邮箱,密码): 复制代码 代码如下: create table t_user( id int primary key auto_increment, email varchar(255), password varchar(255) ); 每个用户的email是唯一的,如果用户使用email作为用户名登陆的话,就需要查询出email对应的一条记录. SELECT * FROM t
-
详解Mysql order by与limit混用陷阱
在Mysql中我们常常用order by来进行排序,使用limit来进行分页,当需要先排序后分页时我们往往使用类似的写法select * from 表名 order by 排序字段 limt M,N.但是这种写法却隐藏着较深的使用陷阱.在排序字段有数据重复的情况下,会很容易出现排序结果与预期不一致的问题. 如表: 查询第一页跟最后一页时出现: 解决办法: SELECT * FROM purchaseinfo ORDER BY actiontime,id LIMIT 0,2; 上面的实际执行结果已
-
MySQL limit使用方法以及超大分页问题解决
前言 日常开发中,我们使用mysql来实现分页功能的时候,总是会用到mysql的limit语法.而怎么使用却很有讲究的,今天来总结一下. limit语法 limit语法支持两个参数,offset和limit,前者表示偏移量,后者表示取前limit条数据. 例如: ## 返回符合条件的前10条语句 select * from user limit 10 ## 返回符合条件的第11-20条数据 select * from user limit 10,20 从上面也可以看出来,limit n 等价于l
-
如何提高MySQL Limit查询性能的方法详解
在MySQL数据库操作中,我们在做一些查询的时候总希望能避免数据库引擎做全表扫描,因为全表扫描时间长,而且其中大部分扫描对客户端而言是没有意义的.其实我们可以使用Limit关键字来避免全表扫描的情况,从而提高效率. 有个几千万条记录的表 on MySQL 5.0.x,现在要读出其中几十万万条左右的记录.常用方法,依次循环: select * from mytable where index_col = xxx limit offset, limit; 经验:如果没有blob/text字段,单行记
-
Mysql排序和分页(order by&limit)及存在的坑
排序查询(order by) 电商中:我们想查看今天所有成交的订单,按照交易额从高到低排序,此时我们可以使用数据库中的排序功能来完成. 排序语法: select 字段名 from 表名 order by 字段1 [asc|desc],字段2 [asc|desc]; 需要排序的字段跟在order by之后: asc|desc表示排序的规则,asc:升序,desc:降序,默认为asc: 支持多个字段进行排序,多字段排序之间用逗号隔开. 单字段排序 mysql> create table test2(
-
浅谈mysql使用limit分页优化方案的实现
Mysql limit分页语句用法 与Oracle和MS SqlServer相比,mysql的分页方法简单的让人想哭. --语法: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset --举例: select * from table limit 5; --返回前5行 select * from table limit 0,5; --同上,返回前5行 select * from table limit 5,10; --返回6
-
MySQL limit分页大偏移量慢的原因及优化方案
在 MySQL 中通常我们使用 limit 来完成页面上的分页功能,但是当数据量达到一个很大的值之后,越往后翻页,接口的响应速度就越慢. 本文主要讨论 limit 分页大偏移量慢的原因及优化方案,为了模拟这种情况,下面首先介绍表结构和执行的 SQL. 场景模拟 建表语句 user 表的结构比较简单,id.sex 和 name,为了让 SQL 的执行时间变化更加明显,这里有9个姓名列. CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREME
-
MySQL Limit性能优化及分页数据性能优化详解
MySQL Limit可以分段查询数据库数据,主要应用在分页上.虽然现在写的网站数据都是千条级别,一些小的的优化起的作用不大,但是开发就要做到极致,追求完美性能.下面记录一些limit性能优化方法. Limit语法: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT子句可以被用于强制 SELECT 语句返回指定的记录数.LIMIT接受一个或两个数字参数.参数必须是一个整数常量. 如果给定两个参数,第一个参数指定