由浅入深学习TensorFlow MNIST 数据集
目录
- MNIST 数据集介绍
- LeNet 模型介绍
- 卷积
- 池化 (下采样)
- 激活函数 (ReLU)
- LeNet 逐层分析
- 1. 第一个卷积层
- 2. 第一个池化层
- 3. 第二个卷积层
- 4. 第二个池化层
- 5. 全连接卷积层
- 6. 全连接层
- 7. 全连接层 (输出层)
- 代码实现
- 导包
- 读取 & 查看数据
- 数据预处理
- 模型建立
- 训练模型
- 保存模型
- 流程总结
- 完整代码
MNIST 数据集介绍
MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道 28*28 的灰度图.
LeNet 模型介绍
LeNet 网络最早由纽约大学的 Yann LeCun 等人于 1998 年提出, 也称 LeNet5. LeNet 是神经网络的鼻祖, 被誉为卷积神经网络的 “Hello World”.
卷积

池化 (下采样)
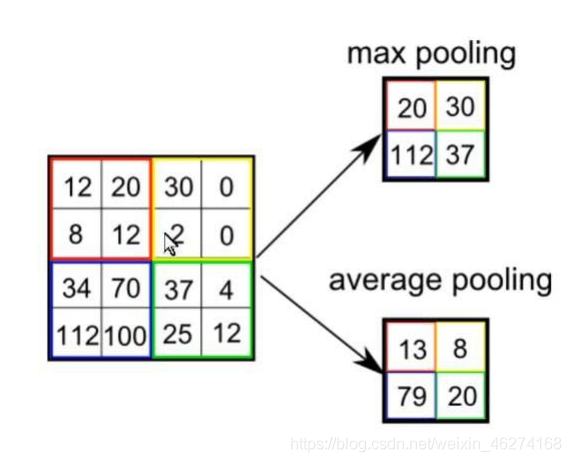
激活函数 (ReLU)

LeNet 逐层分析
1. 第一个卷积层
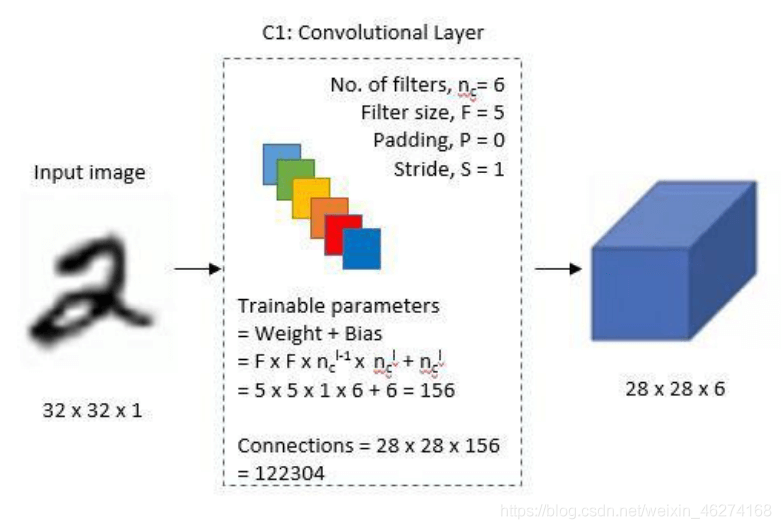
2. 第一个池化层
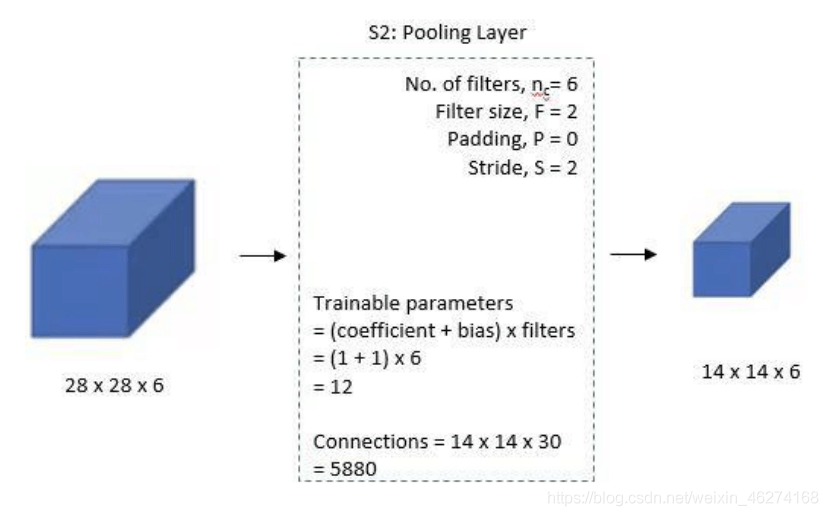
3. 第二个卷积层
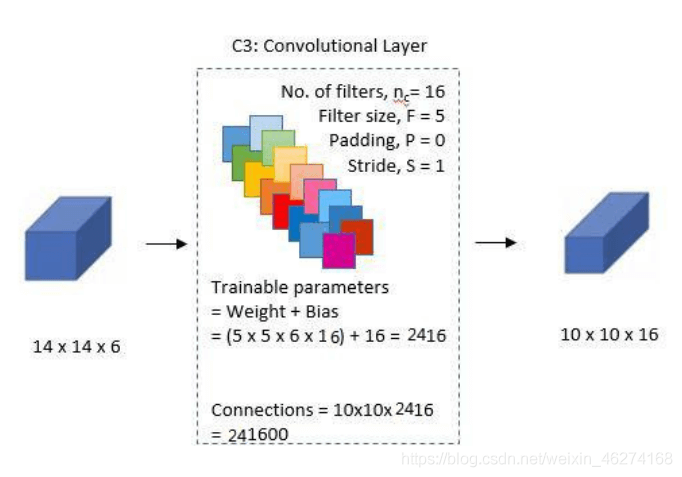
4. 第二个池化层

5. 全连接卷积层

6. 全连接层

7. 全连接层 (输出层)

代码实现
导包
from tensorflow.keras.datasets import mnist from matplotlib import pyplot as plt import numpy as np import tensorflow as tf
读取 & 查看数据
# ------------------1. 读取 & 查看数据------------------ # 读取数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 数据集查看 print(X_train.shape) # (60000, 28, 28) print(y_train.shape) # (60000,) print(X_test.shape) # (10000, 28, 28) print(y_test.shape) # (10000,) print(type(X_train)) # <class 'numpy.ndarray'> # 图片显示 plt.imshow(X_train[0], cmap="Greys") # 查看第一张图片 plt.show()
数据预处理
# ------------------2. 数据预处理------------------ # 格式转换 (将图片从28*28扩充为32*32) X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0) X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0) print(X_train.shape) # (60000, 32, 32) print(X_test.shape) # (10000, 32, 32) # 数据集格式变换 X_train = X_train.astype(np.float32) X_test = X_test.astype(np.float32) # 数据正则化 X_train /= 255 X_test /= 255 # 数据维度转换 X_train = np.expand_dims(X_train, axis=-1) X_test = np.expand_dims(X_test, axis=-1) print(X_train.shape) # (60000, 32, 32, 1) print(X_test.shape) # (10000, 32, 32, 1)
模型建立
# 第一个卷积层 conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu) # 第一个池化层 pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same") # 第二个卷积层 conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu) # 第二个池化层 pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same") # 扁平化 flatten = tf.keras.layers.Flatten() # 第一个全连接层 fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu) # 第二个全连接层 fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax) # 输出层 output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
卷积 Conv2D 的用法:
- filters: 卷积核个数
- kernel_size: 卷积核大小
- strides = (1, 1): 步长
- padding = “vaild”: valid 为舍弃, same 为补齐
- activation = tf.nn.relu: 激活函数
- data_format = None: 默认 channels_last

池化 AveragePooling2D 的用法:
- pool_size: 池的大小
- strides = (1, 1): 步长
- padding = “vaild”: valid 为舍弃, same 为补齐
- activation = tf.nn.relu: 激活函数
- data_format = None: 默认 channels_last
全连接 Dense 的用法:
- units: 输出的维度
- activation: 激活函数
- strides = (1, 1): 步长
- padding = “vaild”: valid 为舍弃, same 为补齐
- activation = tf.nn.relu: 激活函数
- data_format = None: 默认 channels_last
# 模型实例化
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu,
input_shape=(32, 32, 1)),
# relu
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu),
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
])
# 模型展示
model.summary()
输出结果:

训练模型
# ------------------4. 训练模型------------------ # 设置超参数 num_epochs = 10 # 训练轮数 batch_size = 1000 # 批次大小 learning_rate = 0.001 # 学习率
# 定义优化器 adam_optimizer = tf.keras.optimizers.Adam(learning_rate) model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
complie 的用法:
- optimizer: 优化器
- loss: 损失函数
- metrics: 评价
with tf.Session() as sess:
# 初始化所有变量
init = tf.global_variables_initializer()
sess.run(init)
model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs)
# 评估指标
print(model.evaluate(X_test, y_test)) # loss value & metrics values
输出结果:

fit 的用法:
- x: 训练集
- y: 测试集
- batch_size: 批次大小
- enpochs: 训练遍数
保存模型
# ------------------5. 保存模型------------------
model.save('lenet_model.h5')
流程总结

完整代码
from tensorflow.keras.datasets import mnist
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
# ------------------1. 读取 & 查看数据------------------
# 读取数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据集查看
print(X_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
print(X_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
print(type(X_train)) # <class 'numpy.ndarray'>
# 图片显示
plt.imshow(X_train[0], cmap="Greys") # 查看第一张图片
plt.show()
# ------------------2. 数据预处理------------------
# 格式转换 (将图片从28*28扩充为32*32)
X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
print(X_train.shape) # (60000, 32, 32)
print(X_test.shape) # (10000, 32, 32)
# 数据集格式变换
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
# 数据正则化
X_train /= 255
X_test /= 255
# 数据维度转换
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
print(X_train.shape) # (60000, 32, 32, 1)
print(X_test.shape) # (10000, 32, 32, 1)
# ------------------3. 模型建立------------------
# 第一个卷积层
conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第一个池化层
pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same")
# 第二个卷积层
conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第二个池化层
pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same")
# 扁平化
flatten = tf.keras.layers.Flatten()
# 第一个全连接层
fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
# 第二个全连接层
fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax)
# 输出层
output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
# 模型实例化
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu,
input_shape=(32, 32, 1)),
# relu
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu),
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
])
# 模型展示
model.summary()
# ------------------4. 训练模型------------------
# 设置超参数
num_epochs = 10 # 训练轮数
batch_size = 1000 # 批次大小
learning_rate = 0.001 # 学习率
# 定义优化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)
model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
with tf.Session() as sess:
# 初始化所有变量
init = tf.global_variables_initializer()
sess.run(init)
model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs)
# 评估指标
print(model.evaluate(X_test, y_test)) # loss value & metrics values
# ------------------5. 保存模型------------------
model.save('lenet_model.h5')
到此这篇关于由浅入深学习TensorFlow MNIST 数据集的文章就介绍到这了,更多相关TensorFlow MNIST 数据集内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
TensorFlow MNIST手写数据集的实现方法
MNIST数据集介绍 MNIST数据集中包含了各种各样的手写数字图片,数据集的官网是:http://yann.lecun.com/exdb/mnist/index.html,我们可以从这里下载数据集.使用如下的代码对数据集进行加载: from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) 运行上述代码会自动下载数
-
tensorflow使用神经网络实现mnist分类
本文实例为大家分享了tensorflow神经网络实现mnist分类的具体代码,供大家参考,具体内容如下 只有两层的神经网络,直接上代码 #引入包 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #引入input_data文件 from tensorflow.examples.tutorials.mnist import input_data #读取文件 mnist = input_data.re
-
使用tensorflow实现VGG网络,训练mnist数据集方式
VGG作为流行的几个模型之一,训练图形数据效果不错,在mnist数据集是常用的入门集数据,VGG层数非常多,如果严格按照规范来实现,并用来训练mnist数据集,会出现各种问题,如,经过16层卷积后,28*28*1的图片几乎无法进行. 先介绍下VGG ILSVRC 2014的第二名是Karen Simonyan和 Andrew Zisserman实现的卷积神经网络,现在称其为VGGNet.它主要的贡献是展示出网络的深度是算法优良性能的关键部分. 他们最好的网络包含了16个卷积/全连接层.网络的结构
-

深度学习tensorflow基础mnist
软件架构 mnist数据集的识别使用了两个非常小的网络来实现,第一个是最简单的全连接网络,第二个是卷积网络,mnist数据集是入门数据集,所以不需要进行图像增强,或者用生成器读入内存,直接使用简单的fit()命令就可以一次性训练 安装教程 使用到的主要第三方库有tensorflow1.x,基于TensorFlow的Keras,基础的库包括numpy,matplotlib 安装方式也很简答,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu
-
使用TensorFlow直接获取处理MNIST数据方式
MNIST是一个非常有名的手写体数字识别数据集,TensorFlow对MNIST数据集做了封装,可以直接调用.MNIST数据集包含了60000张图片作为训练数据,10000张图片作为测试数据,每一张图片都代表了0-9中的一个数字,图片大小都是28*28.虽然这个数据集只提供了训练和测试数据,但是为了验证训练网络的效果,一般从训练数据中划分出一部分数据作为验证数据,测试神经网络模型在不同参数下的效果.TensorFlow提供了一个类来处理MNIST数据. 代码如下: from tensorflow
-
由浅入深学习TensorFlow MNIST 数据集
目录 MNIST 数据集介绍 LeNet 模型介绍 卷积 池化 (下采样) 激活函数 (ReLU) LeNet 逐层分析 1. 第一个卷积层 2. 第一个池化层 3. 第二个卷积层 4. 第二个池化层 5. 全连接卷积层 6. 全连接层 7. 全连接层 (输出层) 代码实现 导包 读取 & 查看数据 数据预处理 模型建立 训练模型 保存模型 流程总结 完整代码 MNIST 数据集介绍 MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道
-
TensorFlow基于MNIST数据集实现车牌识别(初步演示版)
在前几天写的一篇博文<如何从TensorFlow的mnist数据集导出手写体数字图片>中,我们介绍了如何通过TensorFlow将mnist手写体数字集导出到本地保存为bmp文件. 车牌识别在当今社会中广泛存在,其应用场景包括各类交通监控和停车场出入口收费系统,在自动驾驶中也得到一定应用,其原理也不难理解,故很适合作为图像处理+机器学习的入门案例. 现在我们不妨酝酿一个大胆的想法:在TensorFlow中通过卷积神经网络+mnist数字集实现车牌识别. 实际上车牌字符除了数字0-9,还有字母A
-
详解如何从TensorFlow的mnist数据集导出手写体数字图片
在TensorFlow的官方入门课程中,多次用到mnist数据集. mnist数据集是一个数字手写体图片库,但它的存储格式并非常见的图片格式,所有的图片都集中保存在四个扩展名为idx3-ubyte的二进制文件. 如果我们想要知道大名鼎鼎的mnist手写体数字都长什么样子,就需要从mnist数据集中导出手写体数字图片.了解这些手写体的总体形状,也有助于加深我们对TensorFlow入门课程的理解. 下面先给出通过TensorFlow api接口导出mnist手写体数字图片的python代码,再对代
-
基于Tensorflow读取MNIST数据集时网络超时的解决方式
最近在学习TensorFlow,比较烦人的是使用tensorflow.examples.tutorials.mnist.input_data读取数据 from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('/temp/mnist_data/') X = mnist.test.images.reshape(-1, n_steps, n_inputs) y = mnis
-
tensorflow实现残差网络方式(mnist数据集)
介绍 残差网络是何凯明大神的神作,效果非常好,深度可以达到1000层.但是,其实现起来并没有那末难,在这里以tensorflow作为框架,实现基于mnist数据集上的残差网络,当然只是比较浅层的. 如下图所示: 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采用计算方式为H(x)=F(x)+x 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x12
-
TensorFlow卷积神经网络MNIST数据集实现示例
这里使用TensorFlow实现一个简单的卷积神经网络,使用的是MNIST数据集.网络结构为:数据输入层–卷积层1–池化层1–卷积层2–池化层2–全连接层1–全连接层2(输出层),这是一个简单但非常有代表性的卷积神经网络. import tensorflow as tf import numpy as np import input_data mnist = input_data.read_data_sets('data/', one_hot=True) print("MNIST ready&q
-
TensorFlow神经网络创建多层感知机MNIST数据集
前面使用TensorFlow实现一个完整的Softmax Regression,并在MNIST数据及上取得了约92%的正确率. 前文传送门: TensorFlow教程Softmax逻辑回归识别手写数字MNIST数据集 现在建含一个隐层的神经网络模型(多层感知机). import tensorflow as tf import numpy as np import input_data mnist = input_data.read_data_sets('data/', one_hot=True)