Python中BeautifulSoup模块详解
目录
- 前言
- 安装库
- 导入库
- 解析文档示例
- 提取数据示例
- CSS选择器
- 实例小项目
- 总结
前言
BeautifulSoup是主要以解析web网页的Python模块,它会提供一些强大的解释器,以解析网页,然后提供一些函数,从页面中提取所需要的数据,目前是Python爬虫中最常用的模块之一。
安装库
在使用前需要安装库,这里建议安装bs4,也就是第四版本,因为根据官方文档第三版的已经停止更新。同时安装lxml解释器
pip3 install bs4
pip3 install lxml
导入库
from bs4 import BeautifulSoup
解析文档示例
这里以官方文档进行举例,我把常用的函数都举出来,实际开发过程中用到的不多,了解就可以。
# 取自《爱丽丝梦游仙境》的一段
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!--Elsie--></a>,
<a href="http://example.com/lacsie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/title" class="sister" id="link3">Tillite</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 解析文档,建立一个BeautifulSoup对象,各种函数都是针对此对象展开,此函数会自动编码为Unicode
soup = BeautifulSoup(html,'lxml')
此函数有两个参数:
1、需要解析的文本,可以使字符串,可以使本地文件
2、解释器,这里有"lxml", "lxml-xml", "html.parser", or "html5lib",4种,可以解析绝大多数网页,常用lxml解析 这里有一个坑,如果网页中没有规定编码格式,解释器就不能编码为Unicode,必须先声明一下编码格式,只需要到网页源码中查找编码格式然后做个声明就可以。一般在网页中查找charset关键字。
# 美化文档,有些网页书写不规范,这个函数会补全标签,使其看起来更规范 print(soup.prettify())
提取数据示例
获取到文本后,接下来需要提取我们所需的数据,这里用到选择器 有三种选择器
标签选择器(tag选择器)
标准选择器
CSS选择器
1、标签选择器(tag选择器)
# 直接用标签获取标题
print("title: ", soup.title)
# 获取标题文本
print(soup.title.text)
# 获取p标签
print(soup.p)
# 获取head标签
print(soup.head)
# 获取a标签
print(soup.a)
输出:

标签中最重要的俩个属性:name、attributes
# 使用.name函数获取标签名
print('标题标签的名字: ', soup.title.name)
# tag的属性用法和字典基本一样,可以用属性名取属性,类似字典的键值对,也可以用.attrs取属性:
print('a标签中属性为"href"的值: ', soup.a["href"])
# 会返回一个字典,需要何种属性可自行提取
print('a标签的所有属性: ',soup.a.attrs)
dict1 = soup.a.attrs
# 属性为class的值
print('属性为class的值: ', dict1['class'])
输出:

这里的子孙父兄节点,我感觉用起来忒不顺手,可能是我学的不太彻底,我在这里列出来,大家看看。
# 返回子节点的列表
print("p的子节点: ", soup.p.contents)
# 返回子节点的生成器
print('a的子节点: ', soup.a.children)
# 返回子孙结点的生成器
print("a的子孙结点: ", soup.a.descendants)
# 返回父节点
print("a的父节点: ", soup.a.parent)
# 递归父节点
print("a的递归父节点: ",soup.a.parents)
输出:

上述的标签选择器如果遇到相同的标签名,比如说上述的文档中就有多个a标签,这时就没法选择相同标签的第二个标签,也可能是我没会操作,如果有发现的欢迎评论。
所以需要一个遍历全文的选择器来提取数据: find_all( name , attrs , recursive , text , **kwargs ) # 可根据标签名、属性、内容查找文档,此函数配合正则表达式可匹配出各种特定的数据。。。
# 遍历文档中所有a标签
print("文档中所有a标签: ", soup.find_all('a'))
a_list = soup.find_all('a')
for i, aList in enumerate(a_list):
print(i, aList)
输出:可以提取到文本中所有a标签的内容,再通过遍历就可以得到每一个的内容

根据属性、文本筛选
# 根据属性筛选
print(soup.find_all(attrs={'class': 'sister'}))
# 根据文本筛选
print(soup.find_all(text="The Dormouse's story"))
正则表达式筛选
#使用正则表达式找出文本中带有story字符串的内容
print(soup.find_all(text=re.compile('story')))
还有一个find()方法,用法和findall()类似,不同的是返回的只有一个值,而 findall()返回的是列表。
CSS选择器
目前来说,CSS选择器是最常用的一种,通过标签及属性的层层嵌套可以实现各种特定内容的提取。
# 元素选择器:选择p标签
print('标签为p:', soup.select("p"))
# 类选择器:类前加'.'
print("文本中所有class类的标签: \n", soup.select('.sister'))
# id选择器:id前加'#'
print("id为link2的标签: \n", soup.select('#link2'))
输出:

# 属性选择器:
print("属性为name的标签: \n", soup.select("p[name]"))
print("选择所有属性中有sister的标签: \n", soup.select("*[href]"))
print("选择p标签的后代第三个a标签 \n", soup.select("p>a")[2])
print("选择id=link1后的所有兄弟标签 \n", soup.select("#link1 ~ .sister"))
print('通过属性为 href="http://example.com/title进行查找" \n', soup.select('a[href="http://example.com/title"]'))
print("通过href属性中以http开头的所有标签的查找 \n", soup.select('a[href^="http"]'))
print("通过href属性中以elsie结尾的所有标签的查找 \n", soup.select('a[href$="elsie"]'))
print("通过href属性中包含.com的所有标签的查找 \n", soup.select("a[href*='.com']"))
# 通过标签层层查找,这里的:nth-child(2)代表第二个p标签,a#link2表示a标签的id为link2的标签
print("通过标签层层查找 \n", soup.select("body>p:nth-child(2)>a#link2"))
示例输出:大家可以自行试试
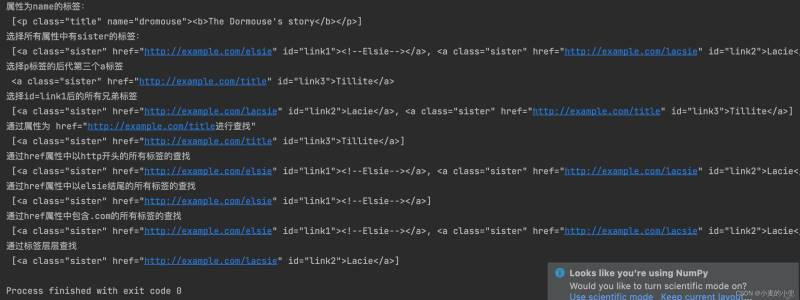
以上的CSS选择器的常用函数已经讲完,通过上面的示例基本上可以拿到web文本中绝大多数数据。下面通过一个小栗子试试水。
实例小项目
需求:爬取某代理网站的免费代理IP地址
第一步:请求数据,获取数据文本第二步:通过BeautifulSoup分析数据 提取数据第三步:保存数据到本地文本
url = "https://www.89ip.cn/"
header = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"}
# 请求数据
response = requests.get(url, headers=header)
print(response.status_code)
# 判断是否请求成功
if response.status_code == 200:
# 获取web信息的文本模式
dataText = response.text
# 使用lxml解析器解析文本
soup = BeautifulSoup(dataText, 'lxml')
# 观察网页源码,获取需求数据,这里使用CSS选择器层层嵌套获得最终的ip信息
ipText = soup.select('body div>div>div>div>table>tbody>tr>td:nth-child(1)')
# 遍历列表获取每一个ip地址
for i in range(len(ipText)):
# 获取ip的文本信息,get_text()是获取文本,strip()是去掉两边空格
ip = ipText[i].get_text().strip()
# 保存到本地
file = open("ipText.txt", 'a+')
file.write(ip+"\n")
# 关闭文件
file.close()
运行结果:

总结
BeautifulSoup模块主要作用是网页解析、提取数据,主要有三种提取数据的选择器,最常用的是CSS选择器,可以根据层层嵌套的方式获取所需信息。在这里需要一点HTML和CSS基本知识。
到此这篇关于Python中BeautifulSoup模块详解的文章就介绍到这了,更多相关Python BeautifulSoup模块内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录 安装 解析标签 解析属性 根据class值解析 根据ID解析 多层筛选 提取a标签中的网址 实战-获取博客专栏 标题+网址 BeautifulSoup库快速上手 安装 pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用PyCharm的命令行 解析标签 from bs4 import BeautifulS
-
Python爬取求职网requests库和BeautifulSoup库使用详解
目录 一.requests库 1.requests简介 2.安装requests库 3.使用requests获取网页数据 我们先导入模块 4.总结requests的一些方法 二.BeautifulSoup库 1.BeautifulSoup简介 2.安装BeautifulSoup库 3.使用BeautifulSoup解析并提取获取的数据 4.BeautifulSoup提取数据的方法 一.requests库 1.requests简介 requests库就是一个发起请求的第三方库,requests允许
-
使用Python爬取小姐姐图片(beautifulsoup法)
Python有许多强大的库用于爬虫,如beautifulsoup.requests等,本文将以网站https://www.xiurenji.cc/XiuRen/为例(慎点!!),讲解网络爬取图片的一般步骤. 为什么选择这个网站?其实与网站的内容无关.主要有两项技术层面的原因:①该网站的页面构造较有规律,适合新手对爬虫的技巧加强认识.②该网站没有反爬虫机制,可以放心使用爬虫. 第三方库需求 beautifulsoup requests 步骤 打开网站,点击不同的页面: 发现其首页是https://
-
python数据解析BeautifulSoup爬取三国演义章节示例
目录 数据解析 Beautiful Soup Beautiful Soup用法 案例-爬取三国演义章节及对应的内容 数据解析 数据解析就是将爬取到的整个页面中的局部的内容进行提取.python中常用的数据解析方式有以下三种: bs4(python中独有的) xpath(推荐,通用型强) 正则 数据解析原理概述: 首先我们知道需要解析(提取)的内容都会在标签之间或者标签对应的属性中进行存储 所以我们需进行指定标签的定位 然后将标签或者标签对应的属性中存储的数据值进行提取(解析) Beautiful
-
Python中BeautifulSoup模块详解
目录 前言 安装库 导入库 解析文档示例 提取数据示例 CSS选择器 实例小项目 总结 前言 BeautifulSoup是主要以解析web网页的Python模块,它会提供一些强大的解释器,以解析网页,然后提供一些函数,从页面中提取所需要的数据,目前是Python爬虫中最常用的模块之一. 安装库 在使用前需要安装库,这里建议安装bs4,也就是第四版本,因为根据官方文档第三版的已经停止更新.同时安装lxml解释器 pip3 install bs4 pip3 install lxml 导入库 from
-
python中random模块详解
Python中的random模块用于生成随机数,它提供了很多函数.常用函数总结如下: 1. random.random() 用于生成一个0到1的随机浮点数: 0 <= n < 1.0 2. random.seed(n) 用于设定种子值,其中的n可以是任意数字.random.random() 生成随机数时,每一次生成的数都是随机的.但是,使用 random.seed(n) 设定好种子之后,在先调用seed(n)时,使用 random() 生成的随机数将会是同一个. 3. random.unifo
-
python中os模块详解
os模块提供了对目录或者文件的新建/删除/查看文件属性,还提供了对文件以及目录的路径操作.比如说:绝对路径,父目录-- os.sep可以取代操作系统特定的路径分隔符.windows下为 "\\",Linux下为"/" os.linesep字符串给出当前平台使用的行终止符.例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'. os.pathsep 输出用于分割文件路径的字符串,系统使用此字符来分割搜索路径(像PATH),例如POSIX上'
-
python爬虫selenium模块详解
selenium模块 selenium基本概念 selenium优势 便捷的获取网站中动态加载的数据 便捷实现模拟登陆 selenium使用流程: 1.环境安装:pip install selenium 2.下载一个浏览器的驱动程序(谷歌浏览器) 3.实例化一个浏览器对象 基本使用 代码 from selenium import webdriver from lxml import etree from time import sleep if __name__ == '__main__': b
-
Python中reduce函数详解
目录 1 reduce用法 2 reduce与for循环性能对比 reduce函数原本在python2中也是个内置函数,不过在python3中被移到functools模块中. reduce函数先从列表(或序列)中取出2个元素执行指定函数,并将输出结果与第3个元素传入函数,输出结果再与第4个元素传入函数,…,以此类推,直到列表每个元素都取完. 1 reduce用法 对列表元素求和,如果不用reduce,我们一般常用的方法是for循环: def sum_func(arr): if len(a
-
Python正则表达式re模块详解(建议收藏!)
目录 前言 match 匹配字符串 单字符匹配 . 匹配任意一个字符 \d 匹配数字 \D 匹配非数字 \S 匹配非空白 \w 匹配单词.字符,如大小写字母,数字,_ 下划线 \W 匹配非单词字符 [ ] 匹配[ ]中列举的字符 表示数量 * 出现0次或无数次 + 至少出现一次 ? 1次或则0次 {m,} 至少出现m次 匹配边界 $ 匹配结尾字符 ^ 匹配开头字符 \b 匹配一个单词的边界 \B 匹配非单词边界 匹配分组 | 匹配左右任意一个表达式 (ab) 将括号中字符作为一个分组 searc
-
Python中字符串切片详解
目录 1.没有步长的简单切片 2.有步长的切片方式 在python中,我们定义好一个字符串,如下所示. 在python中定义个字符串然后把它赋值给一个变量.我们可以通过下标访问单个的字符,跟所有的语言一样,下标从0开始.这个时候呢,我们可以通过切片的方式来截取出我们定义的字符串的一部分.使用切片的时候我们有两种方式:没有步长的简单切片和有步长的切片方式 1.没有步长的简单切片 语法格式是这样的: 首先定义一格字符串,比如叫s,然后给它赋值 截取字符串中的一部分,我们用的语法是 s[ start:
-
关于Python中的闭包详解
目录 1.闭包的概念 2.实现一个闭包 3.在闭包中外函数把临时变量绑定给内函数 4.闭包中内函数修改外函数局部变量 5.注意: 6.练习: 总结 1.闭包的概念 请大家跟我理解一下,如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数.闭包: 在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用.这样就构成了一个闭包.一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失.但
-
python中random随机函数详解
目录 一.random基础 二.实数分布 2.1 对称分布 2.2 指数分布 2.3 Beta 分布 2.4 Gamma 分布 2.5 高斯分布 2.6 对数正态分布 2.7 正态分布 2.8 冯·米塞斯分布 2.9 帕累托分布 2.10 威布尔分布 总结 加载相关库 import random import seaborn as sns import matplotlib.pyplot as plt # 解决中文不显示的问题 from pylab import mpl mpl.rcParams
-
Python中Threading用法详解
Python的threading模块松散地基于Java的threading模块.但现在线程没有优先级,没有线程组,不能被销毁.停止.暂停.开始和打断. Java Thread类的静态方法,被移植成了模块方法. main thread: 运行python程序的线程 daemon thread 守护线程,如果守护线程之外的线程都结束了.守护线程也会结束,并强行终止整个程序.不要在守护进程中进行资源相关操作.会导致资源不能正确的释放.在非守护进程中使用Event. Thread 类 (group=No