Matplotlib直方图绘制中的参数bins和rwidth的实现
目录
- 情景引入
- bins 参数
- stacked参数
- rwidth 参数
- 引用
情景引入
我们在做机器学习相关项目时,常常会分析数据集的样本分布,而这就需要用到直方图的绘制。
在Python中可以很容易地调用matplotlib.pyplot的hist函数来绘制直方图。不过,该函数参数不少,有几个绘图的小细节也需要注意。
首先,我们假定现在有个联邦学习的项目情景。我们有一个样本个数为15的图片数据集,样本标签有4个,分别为cat, dog, car, ship。这个数据集已经被不均衡地划分到4个任务节点(client)上。 情境引入
我们在做机器学习相关项目时,常常会分析数据集的样本分布,而这就需要用到直方图的绘制。
在Python中可以很容易地调用matplotlib.pyplot的hist函数来绘制直方图。不过,该函数参数不少,有几个绘图的小细节也需要注意。
首先,我们假定现在有个联邦学习的项目情景。我们有一个样本个数为15的图片数据集,样本标签有4个,分别为cat, dog, car, ship。这个数据集已经被不均衡地划分到4个任务节点(client)上,如像下面表示:
N_CLIENTS = 3 num_cls, classes = 4, ['cat', 'dog', 'car', 'ship'] train_labels = [0, 3, 2, 0, 3, 2, 1, 0, 3, 3, 1, 0, 3, 2, 2] #数据集的标签列表 client_idcs = [slice(0, 4), slice(4, 11), slice(11, 15)] # 数据集样本在client上的划分情况
我们需要可视化样本在任务节点的分布情况。我们第一次可能会写出如下代码:
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(5,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=num_cls,
label=["Client {}".format(i) for i in range(N_CLIENTS)])
plt.xticks(np.arange(num_cls), classes)
plt.legend()
plt.show()
此时的可视化结果如下:
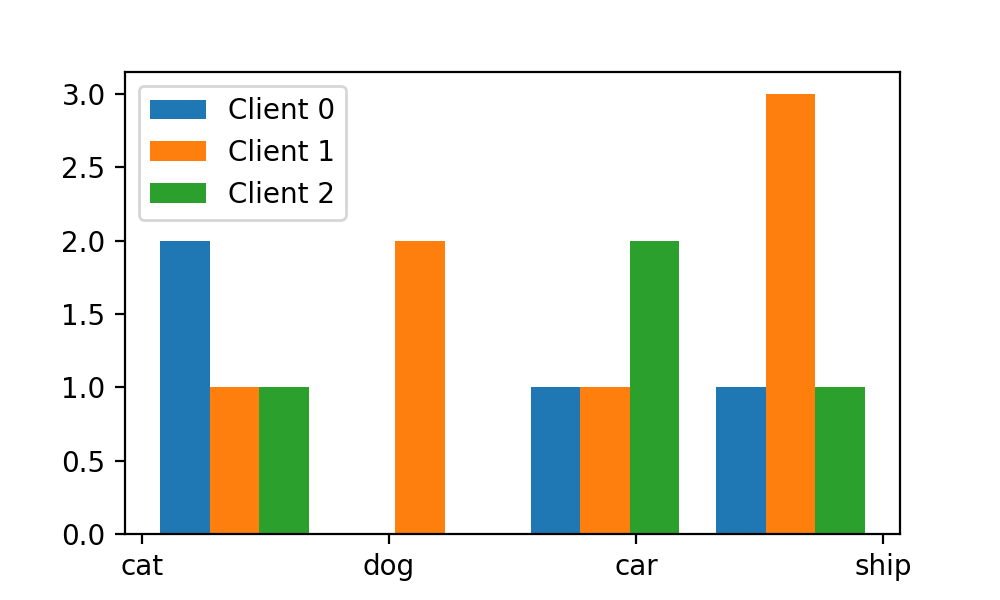
这时我们会发现,我们x轴上的标签和上方的bar(每个图像类别对应的3个bar合称为1个bin)并没有对齐,而这时剧需要我们调整bins这个参数。
bins 参数
在讲述bins参数之前我们先来熟悉一下hist绘图中bin和bar的含义。下面是它们的诠释图:
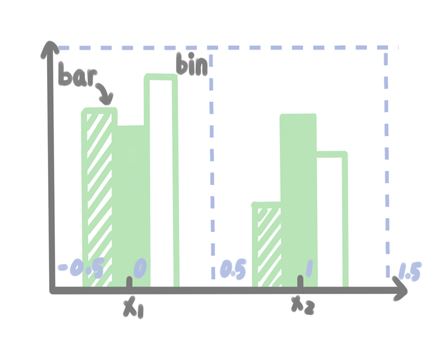
这里\(x_1\)、\(x_2\)是x轴对象,在hist中,默认x轴第一个对象对应刻度为0,第2个对象刻度为1,依次类图。在这个诠释图上,bin(原意为垃圾箱)就是指每个x轴对象所占优的矩形绘图区域,bar(原意为块)就是指每个矩形绘图区域中的条形。 如上图所示,x轴第一个对象对应的bin区间为[-0.5, 0.5),第2个对象对应的bin区域为[0.5, 1)(注意,hist规定一定是左闭又开)。每个对象的bin区域内都有3个bar。
通过查阅matplotlib文档,我们知道了bins参数的解释如下:
bins: int or sequence or str, default: rcParams["hist.bins"] (default: 10)
If bins is an integer, it defines the number of equal-width bins in the range.
If bins is a sequence, it defines the bin edges, including the left edge of the first bin and the right edge of the last bin; in this case, bins may be unequally spaced. All but the last (righthand-most) bin is half-open. In other words, if bins is:
[1, 2, 3, 4]then the first bin is [1, 2) (including 1, but excluding 2) and the second [2, 3). The last bin, however, is [3, 4], which includes 4.
If bins is a string, it is one of the binning strategies supported by numpy.histogram_bin_edges: 'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', or 'sqrt'.
我来概括一下,也就是说如果bins是个数字,那么它设置的是bin的个数,也就是沿着x轴划分多少个独立的绘图区域。我们这里有四个图像类别,故需要设置4个绘图区域,每个区域相对于x轴刻度的偏移采取默认设置。
不过,如果我们要设置每个区域的位置偏移,我们就需要将bins设置为一个序列。
bins序列的刻度要参照hist函数中的x坐标刻度来设置,本任务中4个分类类别对应的x轴刻度分别为[0, 1, 2, 3] 。如果我们将序列设置为[0, 1, 2, 3, 4]就表示第一个绘图区域对应的区间是[1, 2),第2个绘图区域对应的位置是[1, 2),第三个绘图区域对应的位置是[2, 3),依次类推。
就大众审美而言,我们想让每个区域的中心和对应x轴刻度对齐,这第一个区域的区间为[-0.5, 0.5),第二个区域的区间为[0.5, 1.5),依次类推。则最终的bins序列为[-0.5, 0.5, 1.5, 2.5, 3.5]。于是,我们将hist函数修改如下:
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=np.arange(-0.5, 4, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)])
这样,每个划分区域和对应x轴的刻度就对齐了:
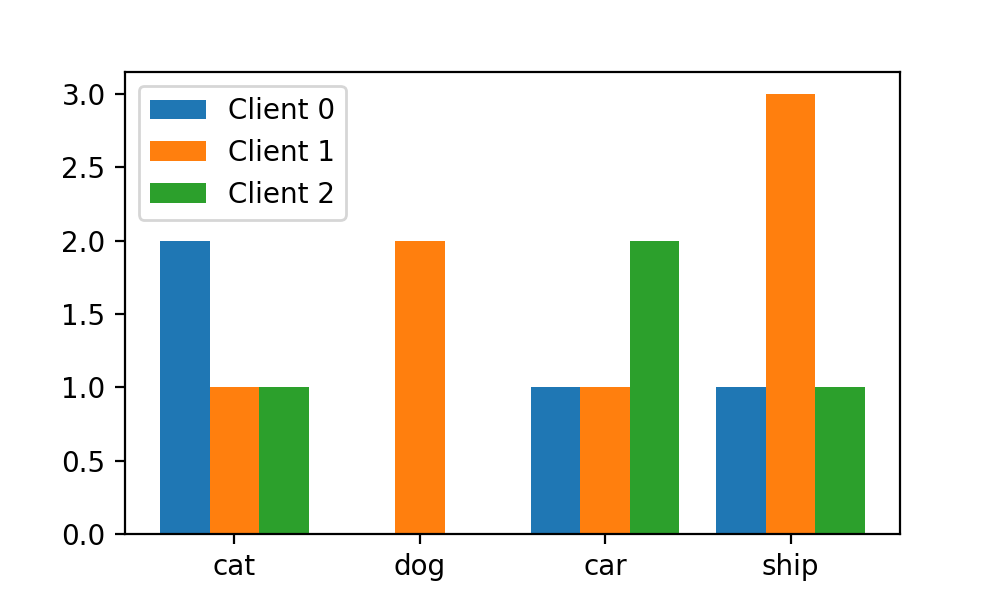
stacked参数
有时x轴的项目多了,每个x轴的对象都要设置3个bar对绘图空间无疑是一个巨大的占用。在这个情况下我们如何压缩空间的使用呢?这个时候参数stacked就派上了用场,我们将参数stacked设置为True:
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True
bins=np.arange(-0.5, 4, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)])
可以看到每个x轴对象的bar都“叠加”起来了:
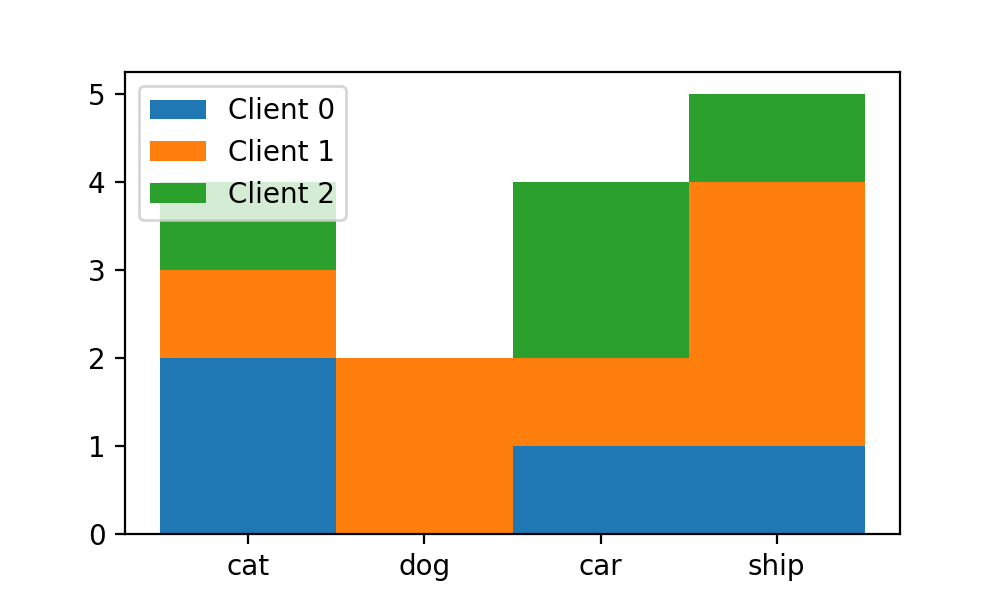
不过,新的问题又出来了,这样每x轴对象的bar之间完全没有距离了,显得十分“拥挤”,我们可否修改bins参数以设置区域bin之间的间距呢?答案是不行,因为我们前面提到过,bins参数中只能将区域设置为连续排布的。
换一个思路,我们设置每个bin内的bar和bin边界之间的间距。此时,我们需要修改r_width参数。
rwidth 参数
我们看文档中对rwidth参数的解释:
rwidth float or None, default: None
The relative width of the bars as a fraction of the bin width. If None, automatically compute the width.
Ignored if histtype is 'step' or 'stepfilled'.
翻译一下,rwidth用于设置每个bin中的bar相对bin的大小。这里我们不妨修改为0.5:
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True,
bins=np.arange(-0.5, 4, 1), rwidth=0.5,
label=["Client {}".format(i) for i in range(N_CLIENTS)])
修改之后的图表如下:
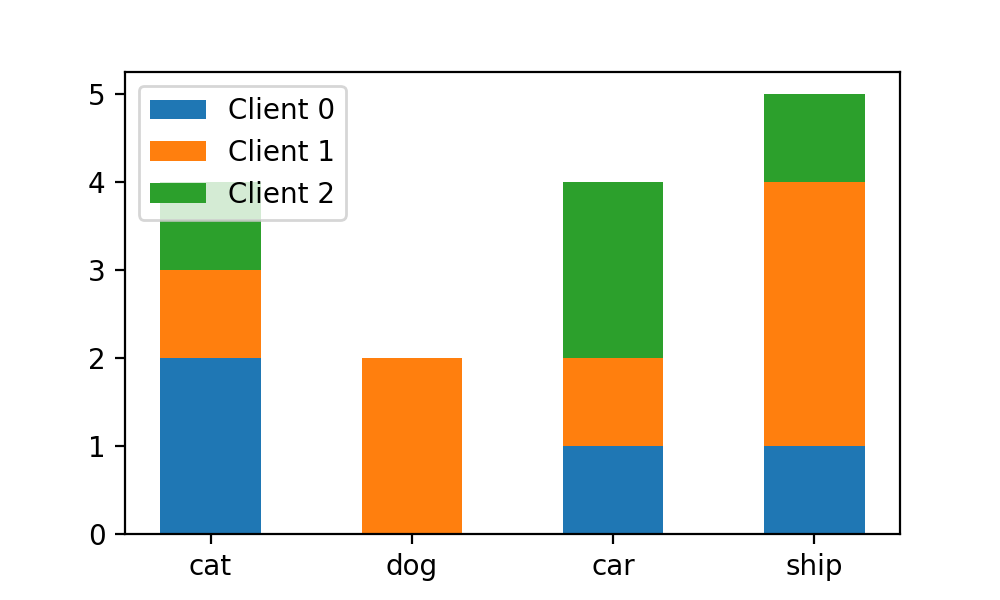
可以看到每个x轴元素内的bar正好占对应bin的宽度的二分之一。
引用
[1] https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.hist.html
到此这篇关于Matplotlib直方图绘制中的参数bins和rwidth的实现的文章就介绍到这了,更多相关Matplotlib bins rwidth内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python matplotlib:plt.scatter() 大小和颜色参数详解
语法 plt.scatter(x, y, s=20, c='b') 大小s默认为20,s=0时点不显示:颜色c默认为蓝色. 为每一个点指定大小和颜色 有时我们需要为每一个点指定大小和方向,以区分不同的点.这时,可以向s和c传入列表.如: import matplotlib.pyplot as plt import numpy as np x = list(range(1, 7)) plt.scatter(x, x, s=10*np.array(x)**2, c=x) plt.show() 参数s
-

python matplotlib饼状图参数及用法解析
这篇文章主要介绍了python matplotlib饼状图参数及用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在python的matplotlib画图函数中,饼状图的函数为pie pie函数参数解读 plt.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, star
-
python matplotlib中文显示参数设置解析
最近在学习python著名的绘图包matplotlib时发现,有时候图例等设置无法正常显示中文,于是就想把这个问题解决了. PS:本文仅针对Windows,其他平台仅供参考. 原因 大致就是matplotlib库中没有中文字体. 我安装的anaconda,这是对应的matplotlib的字体所在文件夹(怎么找到matplotlib配置文件夹所在,下面解决方案会叙述,easyman~). C:\Anaconda64\Lib\site-packages\matplotlib\mpl-data\fon
-
python matplotlib.pyplot.plot()参数用法
如下所示: matplotlib.pyplot.plot(*args, **kwargs) 绘制线条或标记的轴.参数是一个可变长度参数,允许多个X.Y对可选的格式字符串. 例如,下面的每一个都是合法的: plot(x, y) #plot x, y使用默认的线条样式和颜色 plot(x, y, 'bo') #plot x,y用蓝色圆圈标记 plot(y) #plot y用x作为自变量 plot(y, 'r+') #同上,但是是用红色作为标记 如果x或y是2维的,那么相应的列将被绘制. x.y的任意
-
matplotlib.pyplot.plot()参数使用详解
在交互环境中查看帮助文档: import matplotlib.pyplot as plt help(plt.plot) 以下是对帮助文档重要部分的翻译: plot函数的一般的调用形式: #单条线: plot([x], y, [fmt], data=None, **kwargs) #多条线一起画 plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs) 可选参数[fmt] 是一个字符串来定义图的基本属性如:颜色(color),点型(marker),
-
Matplotlib直方图绘制中的参数bins和rwidth的实现
目录 情景引入 bins 参数 stacked参数 rwidth 参数 引用 情景引入 我们在做机器学习相关项目时,常常会分析数据集的样本分布,而这就需要用到直方图的绘制. 在Python中可以很容易地调用matplotlib.pyplot的hist函数来绘制直方图.不过,该函数参数不少,有几个绘图的小细节也需要注意. 首先,我们假定现在有个联邦学习的项目情景.我们有一个样本个数为15的图片数据集,样本标签有4个,分别为cat, dog, car, ship.这个数据集已经被不均衡地划分到4个任
-
Python中如何使用Matplotlib库绘制图形
目录 前言 一.简单的正弦函数与余弦函数 二.进阶版正弦函数与余弦函数 1.改变颜色与粗细 2.设置图片边界 3.设置记号 4.设置记号的标签 5.设置X,Y轴 6.完整代码 三.绘制简单的折线图 总结 前言 Matplotlib 可能是 Python 2D-绘图领域使用最广泛的套件.它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式.这里将会探索使用matplotlib 库实现简单的图形绘制. 一.简单的正弦函数与余弦函数 是取得正弦函数和余弦函数的值: X 是一个 numpy 数组,
-
详解用Python为直方图绘制拟合曲线的两种方法
直方图是用于展示数据的分组分布状态的一种图形,用矩形的宽度和高度表示频数分布,通过直方图,用户可以很直观的看出数据分布的形状.中心位置以及数据的离散程度等. 在python中一般采用matplotlib库的hist来绘制直方图,至于如何给直方图添加拟合曲线(密度函数曲线),一般来说有以下两种方法. 方法一:采用matplotlib中的mlab模块 mlab模块是Python中强大的3D作图工具,立体感效果极佳.在这里使用mlab可以跳出直方图二维平面图形的限制,在此基础上再添加一条曲线.在这里,
-
Python基于matplotlib实现绘制三维图形功能示例
本文实例讲述了Python基于matplotlib实现绘制三维图形功能.分享给大家供大家参考,具体如下: 代码一: # coding=utf-8 import numpy as np import matplotlib.pyplot as plt import mpl_toolkits.mplot3d x,y = np.mgrid[-2:2:20j,-2:2:20j] #测试数据 z=x*np.exp(-x**2-y**2) #三维图形 ax = plt.subplot(111, project
-
如何利用Matplotlib库绘制动画及保存GIF图片
前言 在自学机器学习或者是深度学习的过程中,有的时候总想把执行过程或者执行结果显示出来,所以就想到了动画.好在用 Python 实现动画有许多中方式,而大家熟知的 Matplotlib 库就可以实现. 本文的目的是对 Matplotlib 的动画实现手段做一个简单的说明. 绘制动画 import matplotlib.pyplot as plt import matplotlib.animation as animation 如果要让 matplotlib 实现动画功能的话,那么就要引入 ani
-
Python+matplotlib实现绘制等高线图示例详解
目录 前言 1. 等高线图概述 什么是等高线图? 等高线图常用场景 绘制等高线图步骤 案例展示 2. 等高线图属性 设置等高线颜色 设置等高线透明度 设置等高线颜色级别 设置等高线宽度 设置等高线样式 3. 显示轮廓标签 4. 填充颜色 5. 添加颜色条说明 总结 前言 我们在往期对matplotlib.pyplot()方法学习,到现在我们已经会绘制折线图.柱状图.散点等常规的图表啦(往期的内容如下,大家可以方便查看往期内容) Python matplotlib底层原理解析 Python利用 m
-
Matplotlib 3D 绘制小红花原理
目录 1. 极坐标系 2. 极坐标系花瓣 3. 三维花瓣 4. 花瓣微调 5. 结束语 前言: 在上篇博文中使用了matplotlib绘制了3D小红花,本篇博客主要介绍一下3D小红花的绘制原理. 1. 极坐标系 对于极坐标系中的一点 P ,我们可以用极径 r 和极角 θ 来表示,记为点 P ( r , θ ) , 使用matplotlib绘制极坐标系: import matplotlib.pyplot as plt import numpy as np if __name__ == '__m
-
Python数据可视化之matplotlib.pyplot绘图的基本参数详解
目录 1.matplotlib简介 2.图形组成元素的函数用法 2.1. figure():背景颜色 2.2 xlim()和 ylim():设置 x,y 轴的数值显示范围 2.3 xlabel()和 ylabel():设置 x,y 轴的标签文本 2.4 grid():绘制刻度线的网格线 2.5 axhline():绘制平行于 x 轴额度水平参考线 2.6 axvspan():绘制垂直于 x 轴的参考区域 2.7 xticks(),yticks() 2.8 annotate():添加图形内容细节的
-
Python数据分析之 Matplotlib 散点图绘制
前言: 散点图,又称散点分布图,是使用多个坐标点的分布反映数据点分布规律.数据关联关系的图表,Matplotlib 中可以通过以下方式绘制散点图: 使用plt.plot方法: 在上篇文章Python数据分析之 Matplotlib 折线图绘制中,我们介绍了可以使用plt.plot()方法绘制折线图,该方法同样可以绘制散点图,如下: import random x = range(15) y = [i + random.randint(-2,2) for i in x] plt.plot(x, y
-
教你利用python的matplotlib(pyplot)绘制折线图和柱状图
目录 前言 一.折线图 二.柱状图 总结 前言 今天帮师兄赶在deadline之前画论文的图,现学现卖很是刺激,现把使用matplotlib的子库pyplot画折线图和柱状图的代码记录分享一下,方便大家参考,个人感觉pyplot真的蛮方便的,非常值得使用. 先看下官方对pyplot的描述:“Provides a MATLAB-like plotting framework.”.对,就是一个类似matlab的画图框架.就不多多说了,直接上代码吧: 一.折线图 代码: import matplotl