基于PyQT5制作英雄联盟全皮肤下载器
这是通过博主写的英雄联盟下载器下载的部分的英雄皮肤,可以看一下效果。每个英雄的皮肤的会自动根据英雄名称创建相应的文件夹存放。
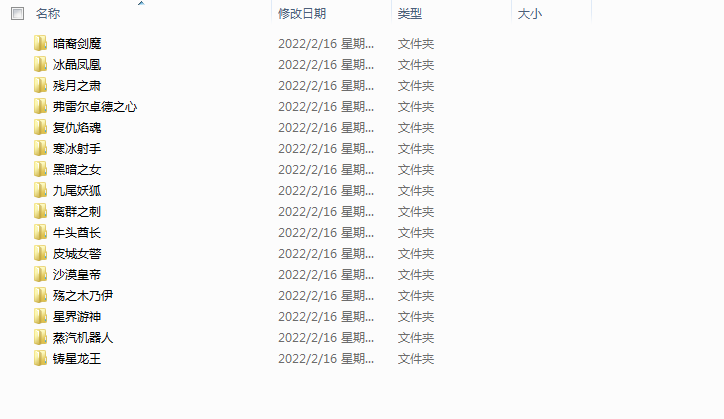


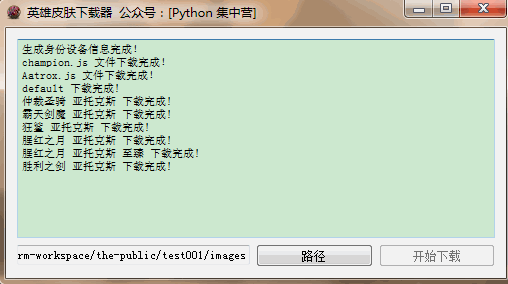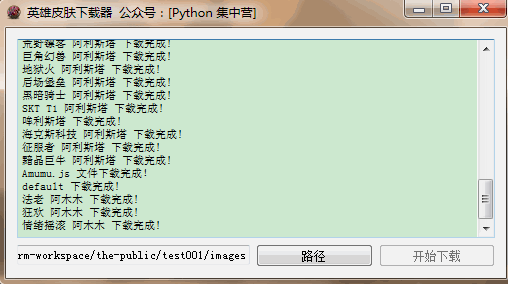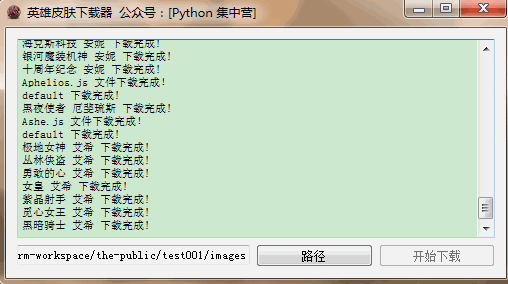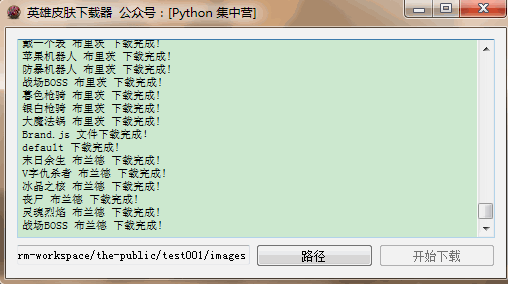
实现思路比较简单,同样是通过PyQt5来编写下载页面。最后通过request模块来进行皮肤的下载部分编写。演示一下操作过程是下面这样的,选择好皮肤的存储路径。然后直接点击开始下载就行了,并且可以在文本浏览器中查看下载进度信息。
接下来,介绍一下代码块的主要是实现部分。首先,介绍一下整个代码块都使用了哪些第三方模块。
# 英雄联盟皮肤下载相关依赖模块 import requests # 网络请求库 import re # 正则表达式匹配库 import json # JSON格式转换库 import os # 应用操作库 import time # 时间模块 from random import random # 随机数模块 from fake_useragent import UserAgent # user_agent 生成库 import logging # 日志模块 import sys # 系统操作 # pyqt5的模块引用这里就不介绍了,最近一直在用。 from PyQt5.QtGui import * from PyQt5.QtWidgets import * from PyQt5.QtCore import *
UI界面的设计过程代码块以及信号与槽函数的应用过程。
def init_ui(self):
self.setWindowTitle('英雄皮肤下载器 公众号:[Python 集中营]')
self.setWindowIcon(QIcon('lol.ico'))
self.resize(500,250)
vbox = QVBoxLayout()
self.save_dir = QLineEdit()
self.save_dir.setReadOnly(True)
self.save_btn = QPushButton()
self.save_btn.setText('路径')
self.save_btn.clicked.connect(self.save_btn_click)
self.thread_ = DownLoadThread(self)
self.thread_.trigger.connect(self.update_log)
self.start_btn = QPushButton()
self.start_btn.setText('开始下载')
self.start_btn.clicked.connect(self.start_btn_click)
grid = QGridLayout()
grid.addWidget(self.save_dir, 0, 0, 1, 2)
grid.addWidget(self.save_btn, 0, 2, 1, 1)
grid.addWidget(self.start_btn, 0, 3, 1, 1)
self.result_brower = QTextBrowser()
self.result_brower.setFont(QFont('宋体', 8))
self.result_brower.setReadOnly(True)
self.result_brower.setPlaceholderText('英雄皮肤批量下载进度显示区域...')
self.result_brower.ensureCursorVisible()
vbox.addWidget(self.result_brower)
vbox.addLayout(grid)
self.setLayout(vbox)
def start_btn_click(self):
self.start_btn.setEnabled(False)
self.thread_.start()
def update_log(self, text):
cursor = self.result_brower.textCursor()
cursor.movePosition(QTextCursor.End)
self.result_brower.append(text)
self.result_brower.setTextCursor(cursor)
self.result_brower.ensureCursorVisible()
def save_btn_click(self):
directory = QFileDialog.getExistingDirectory(self, "选取文件夹", self.cwd)
self.save_dir.setText(directory)
UI界面的设计代码,遵循的是和其他PyQt5一样的设计范式。按照这样的范式写出来的UI代码块个人觉得看起来也比较美观。
为了防止下载过程比较慢的情况下会导致UI界面的主线程直接挂掉,所以在编写下载业务的逻辑时是需要单独使用QThread子线程的方式来编写的。这样可以使得业务逻辑和主页面逻辑分离,就不会产生挂掉的情况发生了。
class DownLoadThread(QThread):
trigger = pyqtSignal(str)
def __init__(self, parent=None):
super(DownLoadThread, self).__init__(parent)
# 初始化日志对象
self.logger = logging.getLogger('英雄联盟皮肤')
logging.basicConfig()
self.logger.setLevel(logging.DEBUG)
self.parent = parent
self.working = True
def __del__(self):
self.working = False
self.wait()
def run(self):
'''
英雄联盟皮肤下载函数
:return:
'''
while self.working == True:
# 构造useragent身份设备信息
headers = {
"User-Agent": str(UserAgent().random),
}
self.logger.info('生成身份设备信息完成')
self.trigger.emit('生成身份设备信息完成!')
# 在LOL的官网经过分析champion.js中包含了我们要用到的英雄ID编号,因此,将这个JS文件下载下来
champion_js_url = "https://lol.qq.com/biz/hero/champion.js"
# 发送http请求、请求地址为这个JS文件的地址。就会将其下载下来了。
response = requests.get(url=champion_js_url, headers=headers)
self.logger.info('champion.js 文件下载完成')
self.trigger.emit('champion.js 文件下载完成!')
# 获取下载的文本信息
text = response.text
self.logger.info('champion.js 文本信息:' + text)
# 匹配champion对象对应的JSON数据,该JSON数据的第0个位置是包含英雄ID编号的JSON数据
hero_json = re.findall(r'champion=(.*?);', text, re.S)[0]
# 将JSON数据转换为dict字典
hero_dict = json.loads(hero_json)
self.logger.info('英雄ID字典信息:' + str(hero_dict))
# 逐个英雄信息遍历
for hero_data in hero_dict["data"].items():
# 获取英雄详细信息的JS文件
hero_js_url = "http://lol.qq.com/biz/hero/{}.js"
# 发送请求下载该JS文件、hero_data[0]取第0位就是英雄ID
response = requests.get(url=hero_js_url.format(hero_data[0]), headers=headers)
# 获取下载文本
text = response.text
self.logger.info(hero_data[0] + '.js 文本信息:' + text)
self.trigger.emit(hero_data[0] + '.js 文件下载完成!')
skins_dict = json.loads(re.findall("{}=(.*?);".format(hero_data[0]), text, re.S)[0])
self.logger.info('当前英雄皮肤字典:' + str(skins_dict))
# 从字典 skins_dict 获取皮肤列表
skins_list = skins_dict["data"]["skins"]
# 获取英雄名称
hero_name = hero_data[1]["name"]
# 在当前目录下面创建images文件夹、以英雄名称作为文件夹名称
os.makedirs(r"./images/{}".format(hero_name), exist_ok=True)
for skin_info in skins_list:
# 初始化皮肤图片地址
skin_pic_url = "https://ossweb-img.qq.com/images/lol/web201310/skin/big{}.jpg"
# 发送下载请求
reponse = requests.get(url=skin_pic_url.format(skin_info["id"]), headers=headers)
try:
self.logger.info('保存路径' + self.parent.save_dir.text().strip())
# 保存皮肤
with open(r"" + self.parent.save_dir.text().strip() + "/{}/{}.jpg".format(hero_name,
skin_info["name"]),
"wb") as f:
f.write(reponse.content)
self.logger.info("{} 下载完成!".format(skin_info["name"]))
self.trigger.emit("{} 下载完成!".format(skin_info["name"]))
except:
self.logger.error(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.trigger.emit(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.sleep(round(random(), 5))
由于下载这一块的业务比较多,为了方便大家查看。基本上主要的代码块我都写上了注释,需要的小伙伴可以根据自己的需求进行改造。
完整代码
# -*- coding:utf-8 -*-
# @author Python 集中营
# @date 2022/1/7
# @file test7.py
# done
'''英雄联盟皮肤下载相关依赖模块'''
import requests # 网络请求库
import re # 正则表达式匹配库
import json # JSON格式转换库
import os # 应用操作库
import time # 时间模块
from random import random # 随机数模块
from fake_useragent import UserAgent # user_agent 生成库
import logging # 日志模块
import sys # 系统操作
'''UI 界面相关依赖模块'''
# pyqt5的模块引用这里就不介绍了,最近一直在用。
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
class HeroSkin(QWidget):
def __init__(self):
super(HeroSkin, self).__init__()
self.cwd = os.getcwd()
self.init_ui()
def init_ui(self):
self.setWindowTitle('英雄皮肤下载器 公众号:[Python 集中营]')
self.setWindowIcon(QIcon('lol.ico'))
self.resize(500,250)
vbox = QVBoxLayout()
self.save_dir = QLineEdit()
self.save_dir.setReadOnly(True)
self.save_btn = QPushButton()
self.save_btn.setText('路径')
self.save_btn.clicked.connect(self.save_btn_click)
self.thread_ = DownLoadThread(self)
self.thread_.trigger.connect(self.update_log)
self.start_btn = QPushButton()
self.start_btn.setText('开始下载')
self.start_btn.clicked.connect(self.start_btn_click)
grid = QGridLayout()
grid.addWidget(self.save_dir, 0, 0, 1, 2)
grid.addWidget(self.save_btn, 0, 2, 1, 1)
grid.addWidget(self.start_btn, 0, 3, 1, 1)
self.result_brower = QTextBrowser()
self.result_brower.setFont(QFont('宋体', 8))
self.result_brower.setReadOnly(True)
self.result_brower.setPlaceholderText('英雄皮肤批量下载进度显示区域...')
self.result_brower.ensureCursorVisible()
vbox.addWidget(self.result_brower)
vbox.addLayout(grid)
self.setLayout(vbox)
def start_btn_click(self):
self.start_btn.setEnabled(False)
self.thread_.start()
def update_log(self, text):
cursor = self.result_brower.textCursor()
cursor.movePosition(QTextCursor.End)
self.result_brower.append(text)
self.result_brower.setTextCursor(cursor)
self.result_brower.ensureCursorVisible()
def save_btn_click(self):
directory = QFileDialog.getExistingDirectory(self, "选取文件夹", self.cwd)
self.save_dir.setText(directory)
class DownLoadThread(QThread):
trigger = pyqtSignal(str)
def __init__(self, parent=None):
super(DownLoadThread, self).__init__(parent)
# 初始化日志对象
self.logger = logging.getLogger('英雄联盟皮肤')
logging.basicConfig()
self.logger.setLevel(logging.DEBUG)
self.parent = parent
self.working = True
def __del__(self):
self.working = False
self.wait()
def run(self):
'''
英雄联盟皮肤下载函数
:return:
'''
while self.working == True:
# 构造useragent身份设备信息
headers = {
"User-Agent": str(UserAgent().random),
}
self.logger.info('生成身份设备信息完成')
self.trigger.emit('生成身份设备信息完成!')
# 在LOL的官网经过分析champion.js中包含了我们要用到的英雄ID编号,因此,将这个JS文件下载下来
champion_js_url = "https://lol.qq.com/biz/hero/champion.js"
# 发送http请求、请求地址为这个JS文件的地址。就会将其下载下来了。
response = requests.get(url=champion_js_url, headers=headers)
self.logger.info('champion.js 文件下载完成')
self.trigger.emit('champion.js 文件下载完成!')
# 获取下载的文本信息
text = response.text
self.logger.info('champion.js 文本信息:' + text)
# 匹配champion对象对应的JSON数据,该JSON数据的第0个位置是包含英雄ID编号的JSON数据
hero_json = re.findall(r'champion=(.*?);', text, re.S)[0]
# 将JSON数据转换为dict字典
hero_dict = json.loads(hero_json)
self.logger.info('英雄ID字典信息:' + str(hero_dict))
# 逐个英雄信息遍历
for hero_data in hero_dict["data"].items():
# 获取英雄详细信息的JS文件
hero_js_url = "http://lol.qq.com/biz/hero/{}.js"
# 发送请求下载该JS文件、hero_data[0]取第0位就是英雄ID
response = requests.get(url=hero_js_url.format(hero_data[0]), headers=headers)
# 获取下载文本
text = response.text
self.logger.info(hero_data[0] + '.js 文本信息:' + text)
self.trigger.emit(hero_data[0] + '.js 文件下载完成!')
skins_dict = json.loads(re.findall("{}=(.*?);".format(hero_data[0]), text, re.S)[0])
self.logger.info('当前英雄皮肤字典:' + str(skins_dict))
# 从字典 skins_dict 获取皮肤列表
skins_list = skins_dict["data"]["skins"]
# 获取英雄名称
hero_name = hero_data[1]["name"]
# 在当前目录下面创建images文件夹、以英雄名称作为文件夹名称
os.makedirs(r"./images/{}".format(hero_name), exist_ok=True)
for skin_info in skins_list:
# 初始化皮肤图片地址
skin_pic_url = "https://ossweb-img.qq.com/images/lol/web201310/skin/big{}.jpg"
# 发送下载请求
reponse = requests.get(url=skin_pic_url.format(skin_info["id"]), headers=headers)
try:
self.logger.info('保存路径' + self.parent.save_dir.text().strip())
# 保存皮肤
with open(r"" + self.parent.save_dir.text().strip() + "/{}/{}.jpg".format(hero_name,
skin_info["name"]),
"wb") as f:
f.write(reponse.content)
self.logger.info("{} 下载完成!".format(skin_info["name"]))
self.trigger.emit("{} 下载完成!".format(skin_info["name"]))
except:
self.logger.error(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.trigger.emit(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.sleep(round(random(), 5))
if __name__ == '__main__':
app = QApplication(sys.argv)
main = HeroSkin()
main.show()
sys.exit(app.exec_())
以上就是基于PyQT5制作英雄联盟全皮肤下载器的详细内容,更多关于PyQT5皮肤下载器的资料请关注我们其它相关文章!
相关推荐
-
Python3爬取英雄联盟英雄皮肤大图实例代码
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API:然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有"正在加载中"这样的字样:同样的方法,分析英雄详情也是这种情况,所以我猜测,这些数据应该是Javascript负责加载的. 继续尝试 然后我就查看了 英雄列表的源代码 ,查看外部引入的js文件,以及行内的js脚本,大概在368行,发现了有处理英雄列表的js注释,然后继续往下读这些代码,发现了第一个彩蛋,也就是他引入了一个
-

python 爬取英雄联盟皮肤并下载的示例
爬取结果: 爬取代码 import os import json import requests from tqdm import tqdm def lol_spider(): # 存放英雄信息 heros = [] # 存放英雄皮肤 hero_skins = [] # 获取所有英雄信息 url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' hero_text = requests.get(url).t
-
python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程? 多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率.线程是在同一时间需要完成多项任务的时候实现的. 为什么要使用多线程 线程在程序中是独立的.并发的执行流.与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存.文件句柄和其他进程应有的状态. 因为线程的划分尺度小于进程,使得多线程程序的并发性高.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率. 线程比进程具有更高的性能,这是由于同一个进程
-
教你用Python爬取英雄联盟皮肤原画
一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: http://lol.qq.com/data/info-heros.shtml 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号. 3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
基于PyQT5制作英雄联盟全皮肤下载器
这是通过博主写的英雄联盟下载器下载的部分的英雄皮肤,可以看一下效果.每个英雄的皮肤的会自动根据英雄名称创建相应的文件夹存放. 实现思路比较简单,同样是通过PyQt5来编写下载页面.最后通过request模块来进行皮肤的下载部分编写.演示一下操作过程是下面这样的,选择好皮肤的存储路径.然后直接点击开始下载就行了,并且可以在文本浏览器中查看下载进度信息. 接下来,介绍一下代码块的主要是实现部分.首先,介绍一下整个代码块都使用了哪些第三方模块. # 英雄联盟皮肤下载相关依赖模块 import requ
-
基于PyQt5制作一个表情包下载器
每次和朋友聊天苦于没有表情包,而别人的表情包似乎是取之不尽.用之不竭.作为一个程序员哪能甘愿认输,于是做了一个表情包下载器供大家斗图. 首先,还是介绍一下设计思路吧,和我们之前做的百度图片下载器2.0一样,使用pyqt5作为UI界面制作的框架,然后就是找一个表情包网站供我们可以下载很多的表情包. 表情包使用的网站是这个,大家也可以使用自己发现的表情包网站做下载. 话不多说,我们先说明一下使用到的python库有哪些. UI界面使用到的pyqt5模块是下面这几个,之前也是一直使用这几个库做UI界面
-
基于PyQT5制作一个二维码生成器
个性化二维码的exe桌面应用的获取方式我放在文章最后面了,注意查收.通过执行打包后的exe应用程序可以直接运行生成个性化二维码. 开始之前先来看一下通过二维码生成器是如何生成个性化二维码的. 其中使用的python包和之前的GUI应用制作使用的模块是一样的. # -*- coding:utf-8 -*- import os import sys from PyQt5.QtWidgets import * from PyQt5.QtGui import * from PyQt5.QtCore im
-
基于PyQt5制作Excel数据分组汇总器
在写数据汇总分组工具之前梳理一下需求,要求一:能够将excel的数据展示到列表中.要求二:能够支持按列汇总数据,并且多列分组汇总.要求三:能够预览分组汇总以后的数据,最后将分好组汇总的数据保存到新的excel数据文件中. 主要使用到第三方python模块有下面这些,和前面几个 PyQt5 应用不同的是这次增加了一个样式模块 qdarkstyle ,通过最后将这个模块直接加入到 QApplication 中就可以显示成黑色酷酷的应用了.这个样式我个人是比较喜欢的... '''应用操作库''' im
-
基于PyQt5制作一个gif动态图片生成器
这个小工具制作的目的是为了将多张图片组合后生成一张动态的GIF图片.设置界面化的操作,只需要将选中的图片导入最后直接生成动态图片. 导入界面相关的第三方库 from PyQt5.QtWidgets import * from PyQt5.QtGui import * 动态图片处理模块 import imageio 应用操作相关库 import sys import os from datetime import datetime 这是用图片生成器生成的一张GIF图片,大家在生成时尽量选择两张大小
-
基于PyQt5制作一个windows通知管理器
前几天看到一个python框架win10toast,它可以用来做windows的消息通知功能.通过设定通知的间隔时间来实现一些事件通知的功能,比如可以可以提醒一头扎进代码编写过程的我们按时喝水. 界面布局采用的依旧是pyqt5的ui设计,使用界面化直接设置好想要提示的内容和时间就可以给我们定时的发通知了. UI相关的部分的还是这几个常用的组件包. from PyQt5.QtGui import * # UI 界面相关 from PyQt5.QtCore import * # 核心组件包 from
-
基于PyQT5制作一个课堂点名系统
刷抖音的时候发现一个老师在用的课堂点名系统.用PyQt5实现了一下同款,导入学生姓名,测试了一下完美运行. 操作效果展示: 完整源代码块还是放在了文章的最后面 使用的时候准备好学生姓名的文件,使用导入数据的按钮直接导入就可以开始点名了.新建一个文本文档,将姓名设置设置好,姓名文件示例如下. 使用系统库或者第三方库都比较常规,这里就不一一介绍了. from PyQt5.QtWidgets import * from PyQt5.QtGui import * from PyQt5.QtCore im
-
基于PyQT5制作一个敏感词检测工具
设计思路:根据敏感词库文件筛选,查看输入的文本中是否包含敏感词汇.从而过滤出相关的敏感词. 导入应用相关的模块. import os import logging import sys 导入UI界面相关的模块. from PyQt5.QtWidgets import QApplication,QWidget,QVBoxLayout,QTextEdit,QGridLayout,QLineEdit,QPushButton,QFileDialog from PyQt5.QtGui import QIc
-
基于PyQT5制作一个桌面摸鱼工具
目录 前言 按键功能控制 主要功能 核心代码 前言 现在我能一整天都严肃地盯着屏幕,看起来就像在很认真地工作, 利用摸鱼,打开小说,可实行完美摸鱼,实时保存进度 用PYQT5 Mock一个摸鱼软件 类似于Thief 按键功能控制 q 退出 B 书签功能 F 增加字体大小 Shift F 减小字体 O 打开文件,现在仅仅支持 utf8格式的txt文件 主要功能 FlameLess Window 无边框窗口 一键快速退出 ini 文件读写 右键上下文菜单 核心代码 pyqt 实现功能还是比较顺畅的,