基于Python第三方插件实现西游记章节标注汉语拼音的方法
起因很单纯,就是给我1年级小豆包的女儿标注三国和西游章节的汉语拼音,我女儿每天都朗读 ,结果有很多字不认识,我爱人居然让我给标记不认识的完了手动注音......我勒个去......身为程序员的我怎么能忘记用程序实现呢,特别是咱也会点Python万能语言。哈哈!列举一下使用的技术。
语言:Python3.7
插件:pypinyin0.37.0 和 openpyxl 3.0.3
开发工具:pycharm 社区版
使用openpyxl操作execl的教程多的你无法想。
使用pypinyin将汉字转换成汉语拼音很简单,网络上API一大推。而且简单的不能再简单了,就一句话就实现了。分享点代码:
# 带声调的(默认)
def yinjie(word):
sentens = "".join(word.split())
print(sentens)
s = ''
# heteronym=True开启多音字
for i in pypinyin.pinyin(word, heteronym=False):
s = s + ''.join(i) + " "
return s
这个就足够汉字转拼音了,不过我要求数据结构就没使用这个方法。我把数据结构说一下。
三层二维数组(这个非常关键):
第一层:单个汉字和汉语拼音构成。
['dì', '第'], ['yī', '一'], ['bǎi', '百'], ['huí', '回']
第二层:按照标题空格分词。
[['dì', '第'], ['yī', '一'], ['bǎi', '百'], ['huí', '回']], [['jìng', '径'], ['huí', '回'], ['dōng', '东'], ['tǔ', '土']], [['wǔ', '五'], ['shèng', '圣'], ['chéng', '成'], ['zhēn', '真']]
第三层:所有标题的集合。
就是第二层的合计,西游记就是100个章节标题集合。
最开始的成果物。这个不好对应也很难阅读。

我爱人给了我一个参考事例。如下图:

咱也不能示弱,咱也是程序员。咱也会万能的Python。
最开始的目标是将文字写入到word中,所以就用了Python-docx。汉语拼音长短不一这个很难对齐。想计算汉语拼音的长度进而计算汉字的位置......这个算法得多复杂,一个排版算法...我不是大神......
这个玩意其实和数学应用题一样,想到了其实一点也不难,就是弄个表格完了让汉语拼音和汉字居中不就得了。想到这个以后其实一点都不难了。使用Python-docx搞了好久有个问题就是竖版的word放不下汉字和汉语拼音。头疼啊。效果如下图:

唉!难道是思路不对。。。
不用Python-docx了。使用openpyxl来操作execl。第一次成果物。看起来还可以。
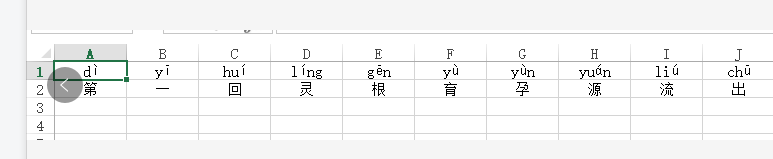
最终的成果物。
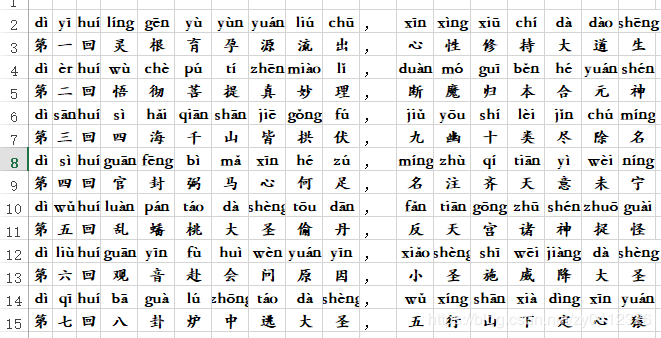
转成PDF的成果物:

继续鼓捣,最终搞定。。。一共花费了近6个小时,时间有点多。其实主要是数据结构和排版耽误时间,在有就是语法,作为Net出身而后转Java的人来说这个…&...就是并且的意思。然而在Python里面他不就是并且是and啊啊啊啊啊!因为这个我改了N多代码调试了好几次,唉深度无语。真是基础不牢地动山摇啊。别废话了上代码:
import pypinyin
from openpyxl import Workbook
from openpyxl.drawing.text import Font
from openpyxl.styles import Font, colors, Alignment
from pulgin.Tools import Tools
class HanZhiAddPinYin:
def __init__(self):
pass
def signWord(self,word):
pinyicontent = pypinyin.pinyin(word, heteronym=False)
word_pinyin = [pinyicontent[0][0], word]
return word_pinyin
def sentences(self,keyWords):
listsentense = []
for duanyu in keyWords.split():
print(duanyu)
duanyu_list = []
for word in duanyu:
duanyu_list.append(self.signWord(word))
listsentense.append(duanyu_list)
print(
listsentense
)
return listsentense
def articles(self,txt_file_path):
article = []
encoding = Tools.get_file_encoding(txt_file_path)
f = open(txt_file_path, "r", encoding=encoding, errors='ignore') # 返回一个文件对象
line = f.readline().strip() # 调用文件的 readline()方法
index = 1
while line:
article.append(self.sentences(line))
line = f.readline()
index = index + 1
f.close()
return article
def builder_execl(self,word_title, save_path, article):
"""
构建execl文件
:param word_title: sheet页面的名词
:param save_path: execl保存路径
:param article: 文章内容集合
:return:
"""
wb = Workbook()
ws = wb.active
ws.title = word_title
ws.sheet_properties.tabColor = "1072BA" # 设置背景
xl_sheet = wb.get_sheet_by_name(word_title)
execl_cell_width = 4.6
for sentences in article:
column_index = 1
# sentences 2行数据
# 获取行数
pinyin_row = xl_sheet.max_row + 1 # 拼音所在的行
hanzi_row = pinyin_row + 1 # 汉字所在的行
sentences_index = 0
for duanyu in sentences: # ['dì', '第'], ['yī', '一'], ['huí', '回']
for sign_word in duanyu: # ['dì', '第']
# region 设置样式
# 设置样式
execl_cell_font = Font(name='华文楷体', size=12, italic=False, color=colors.BLACK, bold=True)
execl_pinyin_row = xl_sheet.cell(row=pinyin_row, column=column_index)
execl_hanzi_row = xl_sheet.cell(row=hanzi_row, column=column_index)
execl_pinyin_row.alignment = Alignment(horizontal='center', vertical='center')
execl_hanzi_row.alignment = Alignment(horizontal='center', vertical='center')
execl_pinyin_row.font = execl_cell_font
execl_hanzi_row.font = execl_cell_font
xl_sheet.column_dimensions['A'].width = 3
xl_sheet.column_dimensions['B'].width = 3
xl_sheet.column_dimensions['C'].width = 3
xl_sheet.column_dimensions['D'].width = execl_cell_width
xl_sheet.column_dimensions['E'].width = execl_cell_width
xl_sheet.column_dimensions['F'].width = execl_cell_width
xl_sheet.column_dimensions['H'].width = execl_cell_width
xl_sheet.column_dimensions['I'].width = execl_cell_width
xl_sheet.column_dimensions['G'].width = execl_cell_width
xl_sheet.column_dimensions['J'].width = execl_cell_width
xl_sheet.column_dimensions['K'].width = execl_cell_width
xl_sheet.column_dimensions['L'].width = execl_cell_width
xl_sheet.column_dimensions['M'].width = execl_cell_width
xl_sheet.column_dimensions['N'].width = execl_cell_width
xl_sheet.column_dimensions['O'].width = execl_cell_width
xl_sheet.column_dimensions['P'].width = execl_cell_width
xl_sheet.column_dimensions['Q'].width = execl_cell_width
xl_sheet.column_dimensions['R'].width = execl_cell_width
xl_sheet.column_dimensions['S'].width = execl_cell_width
xl_sheet.column_dimensions['T'].width = execl_cell_width
xl_sheet.column_dimensions['U'].width = execl_cell_width
xl_sheet.column_dimensions['V'].width = execl_cell_width
xl_sheet.column_dimensions['W'].width = execl_cell_width
# endregion
xl_sheet.cell(row=pinyin_row, column=column_index, value=sign_word[0])
xl_sheet.cell(row=hanzi_row, column=column_index, value=sign_word[1]) # 0 第一百回 1 径回东土 2 五圣成真
# print(sentences_index)
# print(len(duanyu) + len(sentences[0]))
# print(column_index)
if sentences_index == 1 and len(duanyu) + len(sentences[0]) == column_index:#坑人的and
xl_sheet.cell(row=pinyin_row, column=column_index + 1, value=",")
xl_sheet.cell(row=hanzi_row, column=column_index + 1, value=",")
column_index = column_index + 1 # 遇到断句多增加一列向后
column_index = column_index + 1 # 列向后
sentences_index = sentences_index + 1 # 三个短语计数器
wb.save(save_path)
总结
到此这篇关于基于Python第三方插件实现西游记章节标注汉语拼音的方法的文章就介绍到这了,更多相关python第三方插件标拼音内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用到第三方库PyMuPDF图片与pdf相互转换
使用 Python 进行图片和pdf之间的相互转换 使用到第三方库 PyMuPDF 在 python 环境下对 PDF 文件的操作. PDF 转为图片 需新建文件夹 pdf2png import fitz import glob def rightinput(desc): flag=True while(flag): instr = input(desc) try: intnum = eval(instr) if type(intnum)==int: flag = False except: p
-
Python模块汇总(常用第三方库)
模块 定义 计算机在开发过程中,代码越写越多,也就越难以维护,所以为了编写可维护的代码,我们会把函数进行分组,放在不同的文件里.在python里,一个.py文件就是一个模块 优点: 提高代码的可维护性. 提高代码的复用,当模块完成时就可以在其他代码中调用 引用其他模块,包含python内置模块和其他第三方模块 避免函数名和变量名等名称冲突 Python语言生态 Python语言提供超过15万个第三方库,Python库之间广泛联系.逐层封装. 使用pip安装 Python社区:https://py
-
python获取一组汉字拼音首字母的方法
本文实例讲述了python获取一组汉字拼音首字母的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/env python # -*- coding: utf-8 -*- def multi_get_letter(str_input): if isinstance(str_input, unicode): unicode_str = str_input else: try: unicode_str = str_input.decode('utf8') except: try:
-
python实现关闭第三方窗口的方法
背景 最近在测试一款软件的关闭第三方窗口的功能,感觉实现应该挺简单的.所以就尝试了.由于说它的实现是靠c++实现的,本人对c++实在不在行,但是python的第三方库实际上是封装了一套win32的api的 所以我们还是可以依靠python 来实现这个的. 实现 直接贴代码吧 很简单 # -*- coding: utf-8 -*- from win32gui import * import win32gui import win32con from time import sleep def fo
-
python实现将汉字转换成汉语拼音的库
本文实例讲述了python实现将汉字转换成汉语拼音的库.分享给大家供大家参考.具体分析如下: 下面的这个python库可以很容易的将汉字转换成拼音,其中用到了一个word.data 的字典,可点击此处本站下载. #!/usr/bin/env python # -*- coding:utf-8 -*- __version__ = '0.9' __all__ = ["PinYin"] import os.path class PinYin(object): def __init__(sel
-
Python第三方库face_recognition在windows上的安装过程
实际上face_recognition这个项目尤其是dlib更适用于Linux系统.经过我的测试,在性能方面,编译同样规格的项目,这个工具在Windows 10 上大约是Ubuntu上的四分之一.但是在这两者之间我没有看到在其他方面有什么差别. 我使用本教程将这些工具安装到Windows10上,更近的版本也可能正常运行. 安装了C/C++ 编译器的Microsoft Visual Studio 2015 Boost 库,V1.63或者更近的版本 Python3 CMake,Windows安装时要
-
利用python实现汉字转拼音的2种方法
前言 在浏览博客时,偶然看到了用python将汉字转为拼音的第三方包,但是在实现的过程中发现一些参数已经更新,现在将两种方法记录一下. xpinyin 在一些博客中看到,如果要转化成带音节的拼音,需要传递参数,'show_tone_marks=True',但我在实际使用时发现,已经没有这个参数了,变成了tone_marks,其它的参数和使用方法,一看就明白了,写的很清楚. 看下源码: class Pinyin(object): """translate chinese han
-
Python 返回汉字的汉语拼音
后来想到自己Delphi有一个获得拼音的代码.于是找了出来.研究了一下代码如下: 复制代码 代码如下: function get_hz_pywb(hzstr: string; pytype: integer): string; var I: Integer; allstr: string; hh: THandle; pp: pointer; ss: TStringList; function retturn_wbpy(tempstr: string; tqtype: integer): stri
-
基于Python第三方插件实现西游记章节标注汉语拼音的方法
起因很单纯,就是给我1年级小豆包的女儿标注三国和西游章节的汉语拼音,我女儿每天都朗读 ,结果有很多字不认识,我爱人居然让我给标记不认识的完了手动注音......我勒个去......身为程序员的我怎么能忘记用程序实现呢,特别是咱也会点Python万能语言.哈哈!列举一下使用的技术. 语言:Python3.7 插件:pypinyin0.37.0 和 openpyxl 3.0.3 开发工具:pycharm 社区版 使用openpyxl操作execl的教程多的你无法想. 使用pypinyin将汉字转换
-
基于Python安装pyecharts所遇的问题及解决方法
最近学习到数据可视化内容,老师推荐安装pyecharts,于是pip install 了一下,结果...掉坑了,下面是我的跳坑经验,如果你有类似问题,希望对你有所帮助. 第一个坑: 这个不难理解,缺少pyecharts-jupyter-installer嘛,那就安一个呗.可能有人注意到,我使用的是python2 -m pip ...(这种写法是为了解决python 2和3共存时pip的冲突问题,具体解释在本页最后.) 本以为结束了,却掉进了第二个坑: 看到这个,很明显是安装MarkupSafe时
-
Python第三方Window模块文件的几种安装方法
python安装第三方模块 使用软件管理工具pip python自带了包管理工具,就像手机app商城,91助手等软件的功能一样. python2与python3安装模块的方法相似,值得注意的是,你在python2中安装的模块,用python3是无法调用的,我仅以python3为例! Linux和windows下安装模块的方法一致,以下以window为例,输入cmd打开windows终端. 一.具体安装方法: 直接: pip3 install 模块名(python2下使用pip 或者 pip2即可
-

基于Python开发chrome插件的方法分析
本文实例讲述了基于Python开发chrome插件的方法.分享给大家供大家参考,具体如下: 谷歌Chrome插件是使用HTML.JavaScript和CSS编写的.如果你之前从来没有写过Chrome插件,我建议你读一下这个.在这篇教程中,我们将教你如何使用Python代替JavaScript. 创建一个谷歌Chrome插件 首先,我们必须创建一个清单文件:manifest.json. { "manifest_version": 2, "name": "Py
-
基于Python的Houdini插件开发过程详情
本文以Python开发为例来进行说明,环境说明: (1) Python 3.x(我用的版本是 3.9 版本) (2)IDE开具 PyCharm(我用的版本是 PyCharm Community Edition 2021.3.2) (3)Houdini,我安装的版本是 Houdini 19.0.455 Python相关环境所在的位置(Shell.Source Editor.Panel Editor) Shell 就简单介绍一下.当执行 python 代码时,如果没有打开 Python Shell,
-
基于Python实现RLE格式分割标注文件的格式转换
目录 1.Airbus Ship Detection Challenge 2.数据展示 2.1 标注数据 2.2 图象文件 3.格式转换 4.转换结果 1.Airbus Ship Detection Challenge url: https://www.kaggle.com/competitions/airbus-ship-detection Find ships on satellite images as quickly as possible Data Description In thi
-
基于Python的Jenkins的二次开发操作
背景 最近我们在整一个云执行的平台,底层用的是Jenkins来做执行引擎,方便的把我们的脚本做一个统一的调度. Jenkins确实是一个非常方便的框架,它提供了一整套的RESTful的API,可以非常方便的做二次开发,而且提供了一个python的库,操作起来就更加方便了. 常用的Jenkins概念 我们在使用Jenkins的时候,一般看到的都是Jenkins的View. 也就是说我们看到的基本上都是一些视图. 每一个构建的内容,无论是执行用例,跑脚本,还是打包编译发布,都是一个job. 每一个j
-
基于python定位棋子位置及识别棋子颜色
目录 1.将棋盘分割成19x19的小方格 2.根据像素占比识别是否是黑色棋子 3.根据像素占比识别是否是白色棋子 4.将棋盘棋子位置通过列表表示 完整代码如下: 这一篇主要实现定位棋子位置及识别棋子颜色. 围棋棋盘原图如下: 经过上一章节处理,已经将棋盘位置找到,如下图: 现在根据新图,进行棋子位置的定位 1.将棋盘分割成19x19的小方格 为了定位出棋盘每个交叉点上,是否有棋子,需要将棋盘分割成19X19的小方格,由于围棋棋盘每个交叉线直接距离相同,是矩形,因此分割成小方格十分容易,如下图:
-
基于Python实现火车票抢票软件
目录 导语 环境准备 项目思路 代码展示 导语 每年的节假日一到,大家头疼的总时同一个问题:你买到回家的票了吗? 尤其是大型的节日:”比如国庆.春节......“ 数以亿计的人口迁移,让车票成了一年里最难买到的那张票. 跨站买票.买短途票上车补票.准点捡漏等已是老生常谈的技巧.随着互联网的发展,抢票软件成为购票热门渠道.抢票软件的到底靠谱嘛?能抢到票嘛? 近日,小编给大家就正式编写一款Python实现查票以及自动购票抢票的小程序给大家,希望大家如愿! 环境准备 1)运行环境:Python 3 .
-
基于Python代码编辑器的选用(详解)
Python开发环境配置好了,但发现自带的代码编辑器貌似用着有点不大习惯啊,所以咱们就找一个"好用的"代码编辑器吧,网上搜了一下资料,Python常用的编辑器有如下一些: 1. Sublime Text 2. Vim 3. PyScripter 4. PyCharm 5. Eclipse with PyDev 6. Emacs 7. Komodo Edit 8. Wing 9. The Eric Python IDE 10. Interactive Editor for Python