Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法。示例数据请通过明哥的gitee进行下载。
增加计算列
pandas 的 DataFrame,每一行或每一列都是一个序列 (Series)。比如:
import pandas as pd
df1 = pd.read_excel('./excel-comp-data.xlsx');
此时,用 type(df1['city'],显示该数据列(column)的类型是 pandas.core.series.Series。理解每一列都是 Series 非常重要,因为 pandas 基于 numpy,对数据的计算都是整体计算。深刻理解这个,才能理解后面要说的诸如 apply() 函数等。
如果列名 (column name)没有空格,则列有两种方式表达:
df1['city'] df1.city
如果列名有空格,或者创建新列(即该列不存在,需要创建,第一次使用的变量),则只能用第一种表达式。
假设我们要对三个月的数据进行汇总,可以使用下面的方法。实际上就是创建一个新的数据列:
# 由于是创建,不能使用 df.Total df1['Total'] = df1['Jan'] + df1['Feb'] + df1['Mar']
df1['Jan'] 到 df1['Mar'] 都是 Series,所以使用 + 号,可以得到三个 Series 对应位置的数据合计。

当然,也可以用下面的方式:
df1['total'] = df1.Jan + df1.Feb + df1.Mar
增加条件计算列
假设现在要根据合计数 (Total 列),当 Total 大于 200,000 ,类别为 A,否则为 B。在 Excel 中实现用的是 IF 函数,但在 pandas 中需要用到 numpy 的 where 函数:
df1['category'] = np.where(df1['total'] > 200000, 'A', 'B')
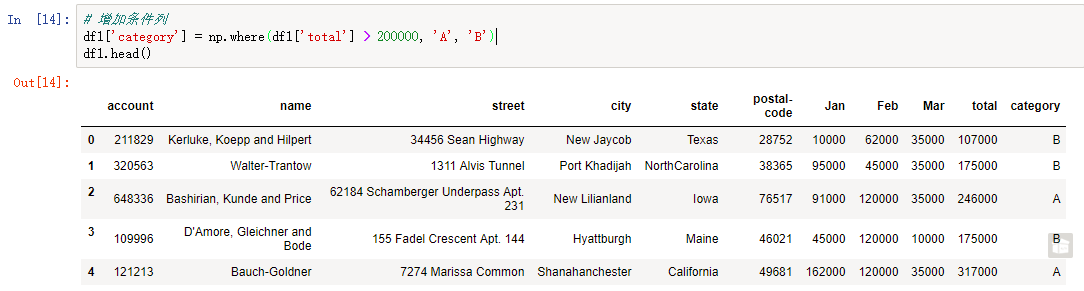
在指定位置插入列
上面方法增加的列,位置都是放在最后。如果想要在指定位置插入列,要用 dataframe.insert() 方法。假设我们要在 state 列后面插入一列,这一列是 state 的简称 (abbreviation)。在 Excel 中,根据 state 来找到 state 的简称 ,一般用 VLOOKUP 函数。我们用两种方法来实现,第一种方法,简称来自 Python 的 dict。
数据来源:
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU",
"KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI",
"NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM",
"Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL",
"Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA",
"PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM",
"MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE",
"NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA",
"MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH",
"WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA",
"NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND",
"Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI",
"DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
如果我们想根据 dict 的 key 找到对应的值,可以使用 dict.get() 方法,这个方法在找不到 key 的时候,不会抛出异常,只是返回 None。比如
state_to_code.get('TEXAS') # 返回 TX
state_to_code.get('TEXASS') # 返回 None
dict.get() 方法参数为 key,是一个标量值。我们并不能像下面这样把整列都传给这个方法,比如下面这样:
df1['abbrev'] = state_to_code.get(df1['state'])
所以我们需要先构造一个 Series (abbrev),然后把 abbrev 赋值给 df1['abbrev']:
abbrev = df1['state'].apply(lambda x: state_to_code.get(x.upper())) df1['abbrev'] = abbrev # 在后面插入列 df1.insert(6, 'abbr', abbrev) # 在指定位置插入列
apply() 函数值得专门写一篇,暂且不细说。
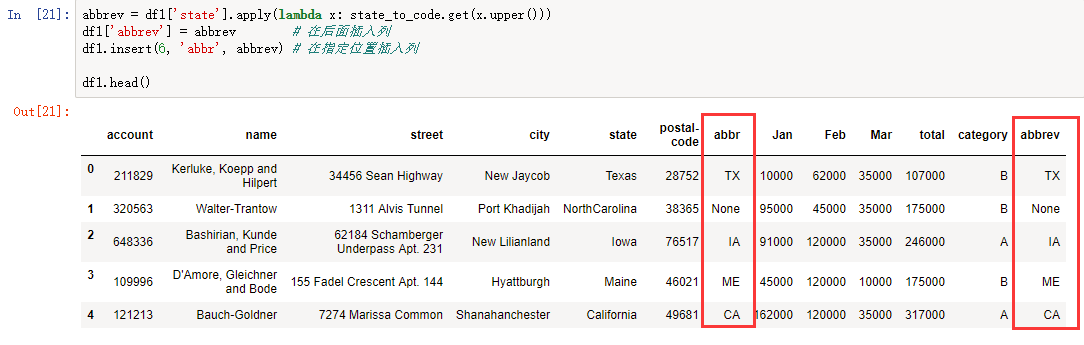
Vlookup 函数功能实现
实现类似 Excel 的 VLookup 功能,可以用 dataframe.merge() 方法。为此,需要将 state_to_code 这个 dict 的数据加载到 DataFrame 中。这里提供两种方法。
方法1: 把数据放在 excel 工作表中,然后读取 Excel 文件加载。数据如下:

excel_file = pd.ExcelFile('excel-comp-data.xlsx')
df_abbrev = pd.read_excel(excel_file, sheetname = 'abbrev')
df2 = df1.merge(df_abbrev, on='state') # 类似数据库的 inner join,不匹配数据不会显示
VLookup 函数根据位置来匹配,merge() 方法根据列名来匹配。因为上面语句中没有指定连接类型,不匹配的记录不会显示。如果需要将 df1 的数据全部显示出来,需要指定 merge() 方法的 how 参数:
df3 = df1.merge(df_abbrev, on='state', how='left') # 类似数据库的 left join
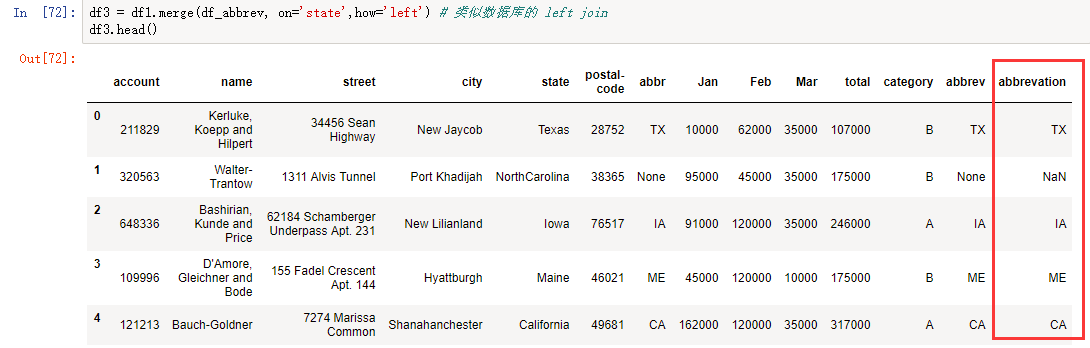
方法2:直接将 state_to_code 加载到 DataFrame。但因为 state_to_code 全部是标量值 (scalar values),方法有一点不同,如下:
# 将 state_to_code 直接加载到 DataFrame abbr2 = pd.DataFrame(list(state_to_code.items()), columns=['state', 'abbr'])
计算合计数
假如需要对各个月份以及月份合计数进行求和。pandas 可以对 Series 运行 sum() 方法来计算合计:
import pandas as pd
import numpy as np
df = pd.read_excel('./excel-comp-data.xlsx');
df['Total'] = df.Jan + df.Feb + df.Mar
# sum_row 的类型是 pandas.core.series.Series, Jan, Feb 等成为 Series 的 index
sum_row = df[['Jan', 'Feb', 'Mar', 'Total']].sum()

也可以将 sum_row 转换成 DataFrame, 以列的方式查看。DataFrame 的 T 方法实现行列互换。
# 转置变成 DataFrame df_sum = pd.DataFrame(data=sum_row).T df_sum

如果想要把合计数放在数据的下方,则要稍作加工。首先通过 reindex() 函数将 df_sum 变成与 df 具有相同的列,然后再通过 append() 方法,将合计行放在数据的后面:
# 转置变成 DataFrame df_sum = pd.DataFrame(data=sum_row).T # 将 df_sum 添加到 df df_sum = df_sum.reindex(columns=df.columns) # append 创建一个新的 DataFrame df_with_total = df.append(df_sum, ignore_index=True)

分类汇总
Excel 的分类汇总功能,在数据功能区,但因为分类汇总需要对数据进行排序,并且分类汇总的数据与明细数据混在一起,个人很少用到,分类汇总一般使用数据透视表。

而在 pandas 进行分类汇总,可以使用 DataFrame 的 groupby() 函数,然后再对 groupby() 生成的 pandas.core.groupby.DataFrameGroupBy 对象进行求和:
df_groupby = df[['state','Jan', 'Feb','Mar', 'Total']].groupby('state').sum()
df_groupby.head()
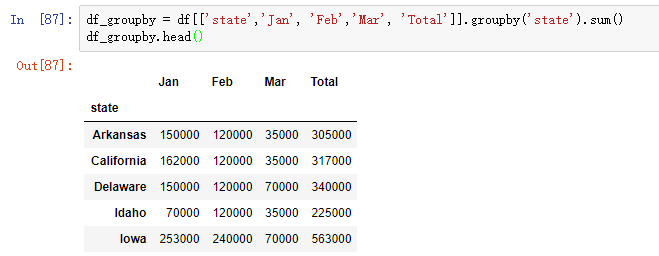
数据格式化
pandas 默认的数据显示,没有使用千分位分隔符,在数据较大时,感觉不方便。如果需要对数据的显示格式化,可以自定义一个函数 number_format(),然后对 DataFrame 运行 applymap(number_format) 函数。applymap() 函数对 DataFrame 中每一个元素都运行 number_format 函数。number_format 函数接受的参数必须为标量值,返回的也是标量值。
# 数字格式化
def number_format(x):
return "{:,.0f}".format(x) # 使用逗号分隔,没有小数位
formated_df = df_groupby.applymap(number_format)
formated_df.head()

数据透视表
pandas 运行数据透视表,使用 pivot_table() 方法。熟练使用 pivot_table() 需要一些练习。这里只是介绍最基本的功能:
- index 参数: 按什么条件进行汇总
- values 参数:对哪些数据进行计算
- aggfunc 参数:aggregation function,执行什么运算
# pivot table # pd.pivot_table 生成一个新的 DataFrame df_pivot = pd.pivot_table(df, index=['state'], values=['Jan','Feb','Mar','Total'], aggfunc= np.sum)
总结
Pandas可以对Excel进行基础的读写操作
Pandas可以实现对Excel各表各行各列的增删改查
Pandas可以进行表中列行筛选等
到此这篇关于Python pandas对excel的操作实现示例的文章就介绍到这了,更多相关Python pandas对excel操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Windows下Python使用Pandas模块操作Excel文件的教程
安装Python环境 ANACONDA是一个Python的发行版本,包含了400多个Python最常用的库,其中就包括了数据分析中需要经常使用到的Numpy和Pandas等.更重要的是,不论在哪个平台上,都可以一键安装,自动配置好环境,不需要用户任何的额外操作,非常方便.因此,安装Python环境就只需要到ANACONDA网站上下载安装文件,双击安装即可. ANACONDA官方下载地址:https://www.continuum.io/downloads 安装完成之后,使用windows + r
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');
-
python pandas写入excel文件的方法示例
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成
-
python办公自动化之excel的操作
准备 使用 Python 操作 Excel 文件,常见的方式如下: xlrd / xlwt openpyxl Pandas xlsxwriter xlwings pywin32 xlrd 和 xlwt 是操作 Excel 文件最多的两个依赖库 其中, xlrd 负责读取 Excel 文件,xlwt 可以写入数据到 Excel 文件 我们安装这两个依赖库 # 安装依赖库 pip3 install xlrd pip3 install xlwt xlrd 读取 Excel 使用 xlrd 中的 o
-
Python Pandas读取Excel日期数据的异常处理方法
目录 异常描述 出现原因 解决方案:修改自定义格式 pandas直接解析Excel数值为日期 总结 异常描述 有时我们的Excel有一个调整过自定义格式的日期字段: 当我们用pandas读取时却是这样的效果: 不管如何指定参数都无效. 出现原因 没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值. 解决方案:修改自定义格式 可以修改为系统内置的自定义格式: 或者在自定义格式上补充负数的定义: 增加;@即可 p
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
python pandas实现excel转为html格式的方法
如下所示: #!/usr/bin/env Python # coding=utf-8 import pandas as pd import codecs xd = pd.ExcelFile('/Users/wangxingfan/Desktop/1.xlsx') df = xd.parse() with codecs.open('/Users/wangxingfan/Desktop/1.html','w','utf-8') as html_file: html_file.write(df.to_
-
Python Learning 列表的更多操作及示例代码
遍历列表-for循环 列表中存储的元素可能非常多,如果想一个一个的访问列表中的元素,可能是一件十分头疼的事.那有没有什么好的办法呢?当然有!使用 for循环 假如有一个食物名单列表,通过 for循环 将列表中的食物名称都打印出来 # 定义一个食物名单列表 foods = ['potato', 'tomato', 'noodles', 'apple', 'pizza'] # 循环访问foods列表 for food in foods: print(food) 输出: potato tomato
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
python编程控制Android手机操作技巧示例
目录 你应该拥有的东西 安装 开始 轻敲 截图 高级点击 TemplateMatching 滑动 打电话给某人 从手机下载文件到电脑 手机录屏 打开手机 发送 Whatsapp 消息 几天前我在考虑使用 python 从 whatsapp 发送消息.和你们一样,我开始潜伏在互联网上寻找一些解决方案并找到了关于twilio. 一开始,是一个不错的解决方案,但它不是免费的,我必须购买一个 twilio 电话号码.此外,我无法在互联网上找到任何可用的 whatsapp API.所以我放弃了使用 twi