Python selenium模块实现定位过程解析
selenuim模块定位方法
1,我们想要操作html页面上的元素,首先必须要定位到这个元素上。每个元素都有他各自的属性,比如id,name,class等,我们就通过这些属性来定位元素。
2,我们先打开一个网页,按F12来获取这个网页的源代码,方便我们定位元素。
from selenium import webdriver
driver=webdriver.Chrome() #启动谷歌浏览器
driver.get("http://www.baidu.com") #打开百度网页
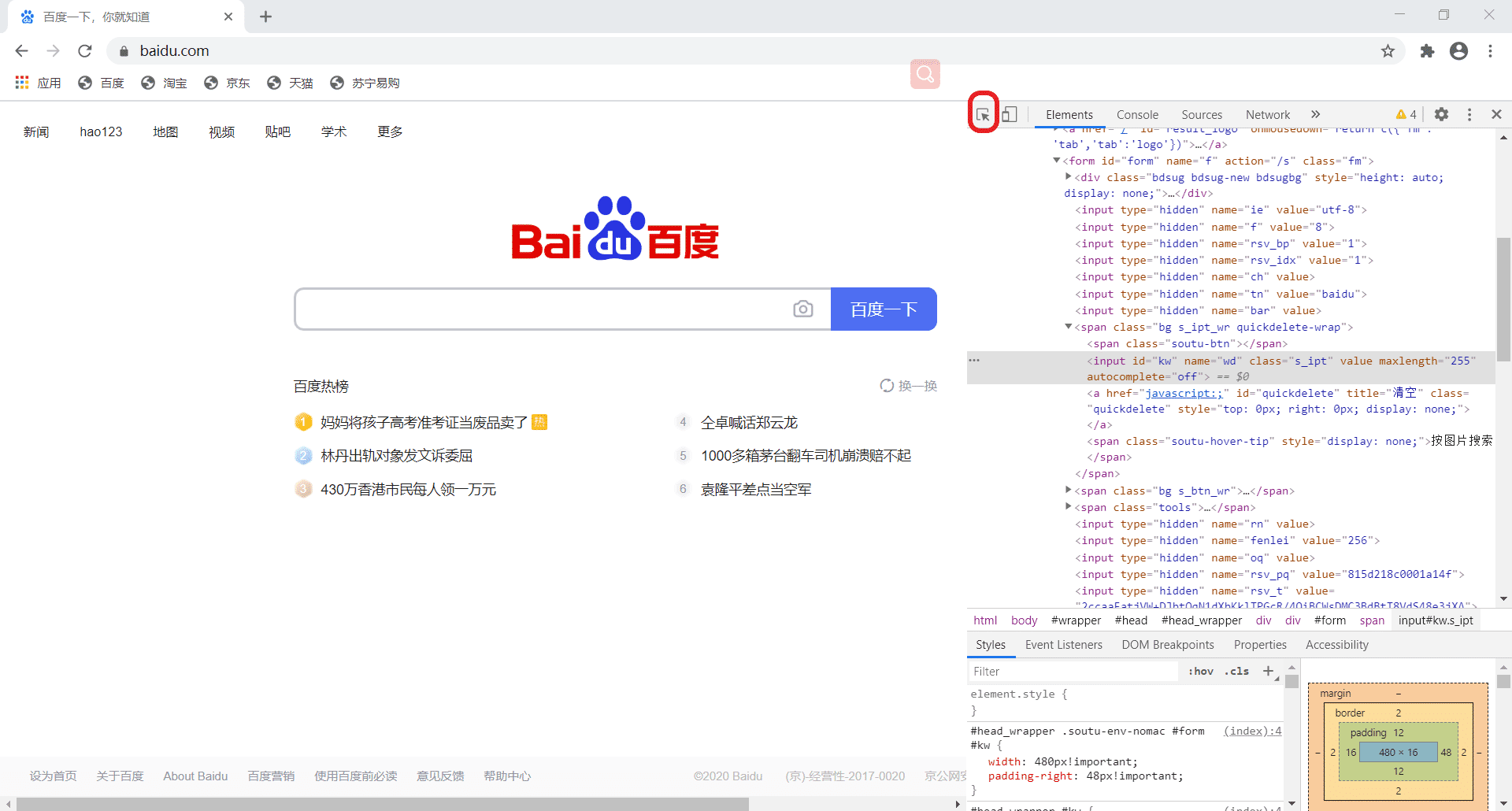
3,按F12我们获取到元素,鼠标点击图片红框中的标,然后把鼠标放到你想要获取的元素位置,然后右边代码会自动定位。
定位方法详解
1.用id定位

我们可以看到右边代码元素id为kw。
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
s=driver.find_element_by_id('kw') #定位到id等于kw的元素(百度搜索框)
s.send_keys('您好') #在搜索框内输入你好
2.用name来定位
#代码同上
driver.find_element_by_name('wd') #定位name为wd的元素
3.用classname来定位
#代码同上
driver.find_element_by_class_name('s_ipt') #通过类名定位,一般类名有重复的,不常使用
4.用标签来定位
#代码同上
driver.find_element_by_tag_name('tag') #标签定位,不常使用
5.定位a标签。
#代码同上
driver.find_element_by_link_text('text') #定位a标签的内容完全匹配
driver.find_element_by_partical_link_text('text') #定位a标签内容模糊匹配
6.通过路径来定位,常用相对路径。
driver.find_element_by_xpath(//*[@id="kw"]) #相对路径定位注意:
html中,大多数的元素都具备id和name的属性,并且id是唯一的,因此用id和name来定位元素是比较常见的方式。 不过有的元素并不具备id和name属性,我们则可以用class name来定位元素。当然我还可以用tag name来定位,但是标签名字太容易重复,除非想定位一组相同标签的元素,否则一般不推荐使用
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python selenium模拟手动操作实现无人值守刷积分功能
经常为学校的各种刷分而发愁,得知开学无望,日后还要刷课,索性自动化一次,学而不用乃愚昧 聪慧 四大模块 初始化 from selenium import webdriver if __name__ == '__main__': driver = webdriver.Chrome() url = 'https://pc.xuexi.cn/points/login.html?ref=https://pc.xuexi.cn/points/my-points.html' driver.get(url =
-
Python3 selenium 实现QQ群接龙自动化功能
一.环境 环境配置为安装了 selenium 模块的 Python3 ,以及浏览器对应的driver 如果没有安装 selenium ,可以在控制台执行下面的代码 pip3 install selenium 浏览器driver下载地址:https://selenium-python.readthedocs.io/installation.html#drivers 需要选择对应的浏览器的对应版本进行下载 下载完成之后放到Python安装目录即可 二.代码 不足:只能给最新发布的一个群接龙进行自动接
-
python3+selenium获取页面加载的所有静态资源文件链接操作
软件版本: python 3.7.2 selenium 3.141.0 pycharm 2018.3.5 具体实现流程如下,废话不多说,直接上代码: from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.desired_capabilities import DesiredCapabilities d = Desired
-
Python + selenium + crontab实现每日定时自动打卡功能
前言 近几日迫于被辅导员三番五次的提醒每日一报打卡,就想着去写个脚本挂在服务器上定时执行.经过我不懈的努力,最终选择了seleniumseleniumselenium,因为简单( 安装selenium库 $ sudo pip install selenium 安装chromdriver 因为我有代理所以直接在官网下载的,那这里你可以选择用淘宝镜像源. 这里为了方便,我直接放命令了.Chromedriver版本我这里选择的是80.0.3987.16(注意要和一会儿下载的Chrome版本一致). 下
-
python+selenium+chrome批量文件下载并自动创建文件夹实例
实现效果:通过url所绑定的关键名创建目录名,每次访问一个网页url后把文件下载下来 代码: 其中 data[i][0].data[i][1] 是代表 关键词(文件保存目录).网站链接(要下载文件的网站) def getDriverHttp(): for i in range(reCount): # 创建Chrome浏览器配置对象实例 chromeOptions = webdriver.ChromeOptions() # 设定下载文件的保存目录为d盘的tudi目录, # 如果该目录不存在,将会自
-
python3.8.1+selenium实现登录滑块验证功能
python3.8.1+selenium解决登录滑块验证的问题,先给大家分享一个效果图,感觉不错,可以参考实现代码. 这里的滑块是qq邮箱的截图,如图所示,可以作为同类滑块验证的参考. """ auther = "zwb",这里使用的python版本是3.8.1,selenium版本是3.141.0,webdriver是谷歌,版本是81.0.4044.138(正式版本) (64 位) webdriver各版本对应的浏览器下载地址:https://npm.t
-
Python selenium爬取微博数据代码实例
爬取某人的微博数据,把某人所有时间段的微博数据都爬下来. 具体思路: 创建driver-----get网页----找到并提取信息-----保存csv----翻页----get网页(开始循环)----...----没有"下一页"就结束, 用了while True,没用自我调用函数 嘟大海的微博:https://weibo.com/u/1623915527 办公室小野的微博:https://weibo.com/bgsxy 代码如下 from selenium import webdrive
-
Python Selenium模块安装使用教程详解
一.概述: Selenium是一个用于Web应用程序测试的工具,本文使用的是Selenium 2.Selenium就是一套类库,不依赖于任何测试框架,除了必要的浏览器驱动,不需要启动其他进程或安装其他程序,也不必像 Selenium 1那样需要先启动服务. 1 支持浏览器 Firefox (FirefoxDriver) IE(InternetExplorerDriver) Opera(OperaDriver) Chrome (ChromeDriver) safari(SafariDriver)
-
python3.7+selenium模拟淘宝登录功能的实现
在使用selenium去获取淘宝商品信息时会遇到登录界面 这个登录界面处理的难度在于滑动验证的实现,有的人使用微博登录,避免了滑动验证,那可不可以使用密码登录呢?答案是可以的 实现思路 首先导入需要的库 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.web
-
Python selenium模块实现定位过程解析
selenuim模块定位方法 1,我们想要操作html页面上的元素,首先必须要定位到这个元素上.每个元素都有他各自的属性,比如id,name,class等,我们就通过这些属性来定位元素. 2,我们先打开一个网页,按F12来获取这个网页的源代码,方便我们定位元素. from selenium import webdriver driver=webdriver.Chrome() #启动谷歌浏览器 driver.get("http://www.baidu.com") #打开百度网页 3,按F
-
Python selenium环境搭建实现过程解析
一:自动化了解知识 工具安装 什么样的项目适合做自动化? 自动化测试一般在什么阶段开始实施? 你们公司自动化的脚本谁来维护?如何维护? 自动化用例覆盖率是多少? 自动化的原理 通过 webdriver 模块中的关键字和浏览器驱动以及页面元素定位进行操作达到模拟人工操作的效果 你们公司的自动化流程是如何展开的? 对自动化的业务需求进行评审 对自动化测试的场景进行选择, 测试工具的选择, 在功能用例中摘选出该场景的用例 根据评审后的场景输出自动化用例, 执行测试用例, 定期维护脚本 二.工具安装 安
-
python selenium登录豆瓣网过程解析
登录流程: 实例化一个driver,然后driver.get()发送请求 最重要的:切换iframe子框架,因为豆瓣的网页中的登录那部分是一个ifrme,必须切换才能寻找到对应元素 利用selenium切换到账号密码登录 利用selenium输入账户和密码 利用selenium点击登录按钮 然后利用字典推导式保存了一下cookie 代码实现: import time from selenium import webdriver # 实例化driver driver = webdriver.Chr
-
Python selenium爬虫实现定时任务过程解析
现在需要启动一个selenium的爬虫,使用火狐驱动+多线程,大家都明白的,现在电脑管家显示CPU占用率20%,启动selenium后不停的开启浏览器+多线程, 好,没过5分钟,CPU占用率直接拉到90%+,电脑卡到飞起,定时程序虽然还在运行,但是已经类似于待机状态, 是不是突然感觉到面对电脑卡死,第一反应:卧槽,这个lj电脑,这么程序都跑不起来,我还写这么多代码,*****!! 是吧,接下来上代码,具体功能,请自信查阅相关资料深造: from datetime import datetime
-

Python selenium模块的安装和配置教程
目录 一.selenium的安装以及简单应用 二.selenium的简单使用 三.selenium提取数据 1.driver对象常用的属性和方法 2.driver对象定位标签元素获取标签对象的方法 3.标签对象提取文本内容和属性值 四.selenium无头模式 一.selenium的安装以及简单应用 我们以谷歌浏览器的chromedriver为例 1.在Python虚拟环境中安装selenium模块 pip/pip3 install selenium 2.下载版本符合的webdriver 以ch
-
python使用rsa非对称加密过程解析
这篇文章主要介绍了python使用rsa非对称加密过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.安装rsa 支持python 2.7 或者 python 3.5 以上版本 使用豆瓣pypi源来安装rsa pip install -i https://pypi.douban.com/simple rsa 2.加密解密 2.1.生成公私钥对 import rsa # 1.接收者(A)生成512位公私钥对 # a. lemon_pub为
-
Python测试线程应用程序过程解析
这篇文章主要介绍了Python测试线程应用程序过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在本章中,我们将学习线程应用程序的测试.我们还将了解测试的重要性. 为什么要测试? 在我们深入讨论测试的重要性之前,我们需要知道测试的内容.一般来说,测试是一种了解某些东西是如何运作的技术.另一方面,特别是如果我们谈论计算机程序或软件,那么测试就是访问软件程序功能的技术. 在本节中,我们将讨论软件测试的重要性.在软件开发中,必须在向客户端发布软
-
Python openpyxl模块原理及用法解析
这篇文章主要介绍了Python openpyxl模块原理及用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 此模块不是Python内置的模块需要安装,安装方法如下 pip install openpyxl 注意: 此模块只支持offce 2010,即是电子表格后缀是*.xlsx 1.openpyxl模块常用函数 import openpyxl wb = openpyxl.load_workbook('example.xlsx') ####
-
python re模块findall()函数实例解析
本文研究的是re模块findall()函数的相关内容,首先看看实例代码: >>> import re >>> s = "adfad asdfasdf asdfas asdfawef asd adsfas " >>> reObj1 = re.compile('((\w+)\s+\w+)') >>> reObj1.findall(s) [('adfad asdfasdf', 'adfad'), ('asdfas asd
-
python打包成so文件过程解析
这篇文章主要介绍了python打包成so文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 wget https://bootstrap.pypa.io/get-pip.py python get-pip.py pip install cython 编写setput.py文件: setup.py文件内容如下: from distutils.core import setup from distutils.extension import