详解C++中的ANSI与Unicode和UTF8三种字符编码基本原理与相互转换
目录
- 1、概述
- 2、Visual Studio中的字符编码
- 3、ANSI窄字节编码
- 4、Unicode宽字节编码
- 5、UTF8编码
- 6、如何使用字符编码
- 7、三种字符编码之间的相互转换(附源码)
- 7.1、ANSI编码与Unicode编码之间的转换
- 7.2、UTF8编码与Unicode编码之间的转换
- 7.3、ANSI编码与UTF8编码之间的转换
- 8、Windows系统对使用ANSI窄字节字符编码的程序的兼容
- 9、字符编码导致程序启动失败的案例
1、概述
在日常的软件开发过程中,会时不时地去处理不同编码格式的字符串,特别是在处理文件路径的相关场景中,比如我们要通过路径去读写文件、通过路径去加载库文件等。常见的字符编码格式有ANSI窄字节编码、Unicode宽字节编码以及UTF8可变长编码。在Linux系统中,主要使用UTF8编码;在Windows系统中,既支持ANSI编码,也支持Unicode编码。
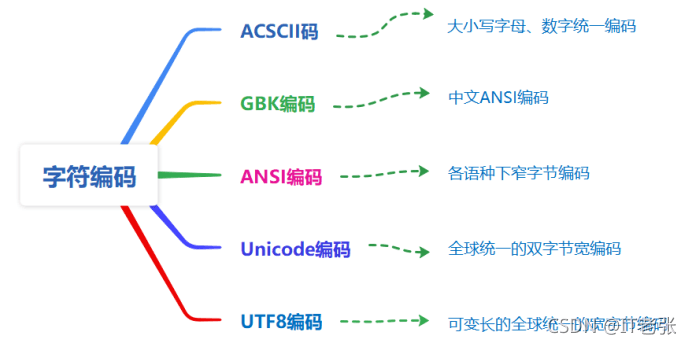
通用的大小写字母和数字则使用全球统一的固定编码,即ASCII码。
ANSI编码是各个国家不同语种下的字符编码,其字符的编码值只在该语种中有效,不是全球统一编码的,比如中文的GB2312编码就是简体中文的ANSI编码。
Unicode编码则是全球统一的双字节编码,所有语种的字符在一起统一的编码,每个字符的编码都是全球唯一的。
UTF8编码是一种可变长的宽字节编码,也是一种全球统一的字符编码。
本文将以WIndows中使用Visual Studio进行C++编程时需要处理的字符编码问题为切入点,详细讲解一下字符编码的相关内容。
2、Visual Studio中的字符编码
在Visual Studio中编写C++代码时,该如何指定字符串的编码呢?其实很简单,使用双引号括住的字符串,使用的就是ANSI窄字节编码;使用L+双引号括住的字符串,使用的就是Unicode宽字节编码,如下所示:
char* pStr = "This is a Test."; // ANSI编码 WCHAR* pWStr = L"This is a Test."; // Unicode宽字节编码
我们也可以使用_T宏定义来指定字符串的编码格式:
TCHAR* pStr = _T("This is a Test.");
设置_T后,则由工程配置属性中的字符集设置来确定到底是使用哪种编码:

如果选择多字节字符集,_T就被解释为双引号,即使用ANSI窄字节编码;如果选择Unicode字符集,_T就被解释为L,即使用Unicode宽字节编码。
其实,如果在工程配置中选择使用Unicode字符集,工程中会添加一个_UNICODE宏,如下所示:

如果选择多字节字符集,则没有_UNICODE宏。代码中正是通过这个宏来判定到底使用哪种编码的,比如对_T的判断:
#ifdef _UNICODE #define _T(X) L(X) #else #define _T(X) (X) #endif // _UNICODE
和字符编码相对应的,Windows系统提供两个版本的API,比如给窗口设置文字的API函数,一个是支持ANSI窄字节编码的SetWindowTextA(ANSI窄字节版本),一个是支持Unicode宽字节编码的SetWindowTextW(Wide宽字节版本)。我们也可以直接调用SetWindowText,然后由_UNICODE宏判断到底使用哪个版本,如下:
#ifdef _UNICODE #define SetWindowText SetWindowTextW #else #define SetWindowText SetWindowTextA #endif // !UNICODE
3、ANSI窄字节编码
ANSI编码是不同语种下的字符编码,比如GB2312字符编码就是简体中文的本地编码。
ANSI编码是个本地范畴,只适用于对应的语种,每个字符的编码不是全球唯一的编码,只在对应的语种中有效。对于中文GB2312编码的字符串,如果当成英文的ANSI编码来解析,则结果会是乱码!
但是对于大小写英文字母和数字的ANSI编码,是字符ASCII码,英文字母和数字的ACSII码是全球统一的,比如大写字母A的ASCII码是65(十六进制是41H),数字0的ASCII码是48(十六进制是30H)。所以在所有语种中,大小写字母及数字的ANSI编码,都是能识别的。不同语种下的本地文字字符,一般是不能相互识别的。
使用中文ANSI编码的字符串开发的程序(代码中使用的都是中文字符串,使用的是ANSI窄字节编码),拿到俄文操作系统中可能显示的都是乱码,因为在俄文的ANSI编码中只识别俄文的ANSI编码出来的字符串,无法识别中文ANSI编码的字符串。这里主要有两类字符乱码问题,一是UI界面上显示的文字是乱码;二是使用路径去创建文件或访问文件时会因为路径中的字符是乱码,导致文件创建或访问失败。
4、Unicode宽字节编码
Unicode编码是全球统一的字符编码,每个语种下的每个字符的编码值都是全球唯一的,即在Unicode编码集中可以识别每个语种下的所有字符。所以为了实现软件对多语种(多国语言)的支持,我们在开发软件时要选择Unicode字符编码,使用Unicode编码的字符串,调用Unicode版本的API。
系统在提供包含字符串参数的API时,都会提供两个版本,一个是ANSI版本的,一个是Unicode版本的,主要体现在对字符串编码的处理上,比如SetWindowTextA(ANSI版本)和SetWindowTextW(Wide宽字节Unicode版本)。我们可以直接调用W版本API,但一般我们调用API时,我们不指定调用哪个版本,是通过设置工程属性中的编码格式来确定使用哪个版本:
#ifdef _UNICODE #define SetWindowText SetWindowTextW #else #define SetWindowText SetWindowTextA #endif // !UNICODE
具体情况已在上面的“Visual Studio中的字符编码”章节中详细讲述,此处不再赘述。
在Unicode编码中,每个字符都占两个字节。对于大小写字母和数字,当他们出现在字符串中时,对应的内存中存放的是它们的ASCII码值,只占一个字节,在Unicode 2字节编码中,高位将填充0。
5、UTF8编码
UTF8编码是可变长字符编码格式,是一种紧凑型存储的编码格式,也是一种宽字节的、全球统一的编码格式。UTF8编码中的所有字符,包括不同语种下面的字符,都是全球唯一编码的,在所有的系统都能识别出来。
UTF8编码中,能用一个字节存放的,就用一个字节存放,比如大小写字母和数字,在字符串中存放的ASCII码,只需要一个字节去存放就够了。所以在UTF8编码中,大小写字母和数字只占一个字节。我们常用的中文字符,一个字符则占用3个字节。
UTF8编码之所以称之为可变长的,是因为其根据字符需要的实际存储空间大小来编码的,比如大小写字母和数字的存储只需要1个字节就够了,所以它们只占一个字节,而一个中文字符则占三个字节。
6、如何使用字符编码
Windows系统主要使用Unicode编码,Linux则使用UTF8编码,后台服务器一般使用的都是Linux系统,而客户端是运行在Windows操作系统上的。一般客户端与服务器交互的数据的字符串编码统一使用全球统一编码的UTF8编码。
客户端收到UTF8编码的字符串后,需要将UTF8字符换转换后显示在界面上。如果客户端使用的是Unicode编码字符集,将UTF8编码的字符串转换成Unicode编码的字符串后再显示到界面上;如果客户端使用的是多字节ANSI编码,则需要再将Unicode编码的字符串转成ANSI编码的字符串。
这里注意一下,UTF8编码的字符串要转成ANSI编码的,不能直接将UTF8转成ANSI,需要先将UTF8转成Unicode,然后再将Unicode转成ANSI。
为了实现软件对多语种(多国语言)的支持,我们在开发Windows软件时要选择Unicode字符编码,使用Unicode编码的字符串,调用Unicode版本的API。
此外,对于一些开源的项目,提供的API接口中有字符串参数的,一般都明确指定字符串编码为UTF8。因为一般情况下开源库都支持跨平台,既支持Windows平台,也支持Linux平台,所以要选择使用通用的、大家都是识别的UTF8编码。
比如在轻便型数据库sqlite开源库中,用于打开数据库文件的接口sqlite3_open,就明确指定使用UTF8编码的字符串:
** ** ^URI hexadecimal escape sequences (%HH) are supported within the path and ** query components of a URI. A hexadecimal escape sequence consists of a ** percent sign - "%" - followed by exactly two hexadecimal digits ** specifying an octet value. ^Before the path or query components of a ** URI filename are interpreted, they are encoded using UTF-8 and all ** hexadecimal escape sequences replaced by a single byte containing the ** corresponding octet. If this process generates an invalid UTF-8 encoding, ** the results are undefined. ** ** <b>Note to Windows users:</b> The encoding used for the filename argument ** of sqlite3_open() and sqlite3_open_v2() must be UTF-8, not whatever ** codepage is currently defined. Filenames containing international ** characters must be converted to UTF-8 prior to passing them into ** sqlite3_open() or sqlite3_open_v2(). ** ** <b>Note to Windows Runtime users:</b> The temporary directory must be set ** prior to calling sqlite3_open() or sqlite3_open_v2(). Otherwise, various ** features that require the use of temporary files may fail. ** ** See also: [sqlite3_temp_directory] */ SQLITE_API int sqlite3_open( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); SQLITE_API int sqlite3_open16( const void *filename, /* Database filename (UTF-16) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); SQLITE_API int sqlite3_open_v2( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb, /* OUT: SQLite db handle */ int flags, /* Flags */ const char *zVfs /* Name of VFS module to use */ );
对于使用Unicode编码的Windows程序,代码中使用的都是Unicode编码的字符串,在调用sqlite3_open接口之前,需要将Unicode编码的字符串转成UTF8编码的。如果收到开源库中回调上来的UTF8编码的字符串数据,则需要将UTF8编码的字符串转成Unicode后,才能显示到UI界面上,才能使用转码后的Unicode字符串去调用Windows系统API。
7、三种字符编码之间的相互转换(附源码)
有朋友曾经提出这样的疑问,是不是我在Windows下把一个双引号括起来的ANSI窄字节字符串赋值给WCHAR宽字节的指针:
WCHAR* pStr = "测试字符串";
字符串就能自动转换成Unicode宽字节?答案是否定的,这样的赋值操作并不会做字符编码转换,右侧的仅仅是字符串的首地址,作为地址,可以赋值给很多数据类型,比如int、void*、char*等等。
那可能有人会说,那为啥我在Unicode下,将一个ANSI编码的字符串传给MFC库中的CString类对象时会自动转换成Unicode宽字符呢?这和上面的情况不一样的,是因为CString类重载了赋值操作符函数,在函数内部做了字符编码的转换,代码如下:
const CUIString& CUIString::operator=(LPCSTR lpsz)
{
int nSrcLen = lpsz != NULL ? lstrlenA(lpsz) : 0;
AllocBeforeWrite(nSrcLen);
_ANSIToUnicode(m_pchData, lpsz, nSrcLen+1);
ReleaseBuffer();
return *this;
}
一般情况下,是需要我们自己去编写字符编码转换的代码的。下面来看一下,我们在进行Windows C++编程时,需要调用哪些API接口实现上述三种编码之间的转换。
7.1、ANSI编码与Unicode编码之间的转换
ANSI转成Unicode的代码如下:
/*=============================================================================
函 数 名: AnsiToUnicode
功 能: 实现将char型buffer(ANSI编码)中的内容安全地拷贝到指定的WChar型(Unicode编码)的buffer中
参 数: char* pchSrc [in] 源字符串
WCAHR* pchDest [out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void AnsiToUnicode( const char* pchSrc, WCHAR* pchDest, int nDestLen )
{
if ( pchSrc == NULL || pchDest == NULL )
{
return;
}
int nTmpLen = MultiByteToWideChar(CP_ACP, 0, pchSrc, -1, NULL, 0);
WCHAR* pWTemp = new WCHAR[nTmpLen + 1];
memset(pWTemp, 0, (nTmpLen + 1) * sizeof(WCHAR));
MultiByteToWideChar(CP_ACP, 0, pchSrc, -1, pWTemp, nTmpLen + 1);
UINT nLen = wcslen(pWTemp);
if (nLen + 1 > (nDestLen / sizeof(WCHAR)))
{
wcsncpy(pchDest, pWTemp, nDestLen / sizeof(WCHAR) - 1);
pchDest[nDestLen / sizeof(WCHAR) - 1] = 0;
}
else
{
wcscpy(pchDest, pWTemp);
}
delete []pWTemp;
}
Unicode转成ANSI的代码如下:
/*=============================================================================
函 数 名: UnicodeToAnsi
功 能: 实现将WCHAR型buffer(Unicode编码)中的内容安全地拷贝到指定的char型(ANSI编码)的buffer中
参 数: WCHAR* pchSrc [in] 源字符串
char* pchDest[out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void UnicodeToAnsi(const WCHAR* pchSrc, char* pchDest, int nDestLen )
{
if ( pchDest == NULL || pchSrc == NULL )
{
return;
}
const WCHAR* pWStrSRc = pchSrc;
int nTmplen = WideCharToMultiByte(CP_ACP, 0, pWStrSRc, -1, NULL, 0, NULL, NULL);
char* pTemp = new char[nTmplen + 1];
memset(pTemp, 0, nTmplen + 1);
WideCharToMultiByte(CP_ACP, 0, pWStrSRc, -1, pTemp, nTmplen + 1, NULL, NULL);
int nLen = strlen(pTemp);
if (nLen + 1 > nDestLen)
{
strncpy(pchDest, pTemp, nDestLen - 1);
pchDest[nDestLen - 1] = 0;
}
else
{
strcpy(pchDest, pTemp);
}
delete []pTemp;
}
7.2、UTF8编码与Unicode编码之间的转换
UTF8转成Unicode的代码如下:
/*=============================================================================
函 数 名: Utf8ToUnicode
功 能: 实现将char型的buffer(utf8编码)中的内容安全地拷贝到指定的WCHAR型buffer(Unicode编码)中
参 数: char* pchSrc [in] 源字符串
WCHAR* pchDest [out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void Utf8ToUnicode( const char* pchSrc, WCHAR* pchDest, int nDestLen )
{
if ( pchSrc == NULL || pchDest == NULL )
{
return;
}
int nTmpLen = MultiByteToWideChar(CP_UTF8, 0, pchSrc, -1, NULL, 0);
WCHAR* pWTemp = new WCHAR[nTmpLen + 1];
memset(pWTemp, 0, (nTmpLen + 1) * sizeof(WCHAR));
MultiByteToWideChar(CP_UTF8, 0, pchSrc, -1, pWTemp, nTmpLen + 1);
UINT nLen = wcslen(pWTemp);
if (nLen + 1 > (nDestLen / sizeof(WCHAR)))
{
wcsncpy(pchDest, pWTemp, nDestLen / sizeof(WCHAR) - 1);
pchDest[nDestLen / sizeof(WCHAR) - 1] = 0;
}
else
{
wcscpy(pchDest, pWTemp);
}
delete []pWTemp;
}
Unicode转成UTF8的代码如下:
/*=============================================================================
函 数 名: UnicodeToUtf8
功 能: 实现将WCHAR型buffer(Unicode编码)中的内容安全地拷贝到指定的char型的buffer(utf8编码)中
参 数: WCAHR* pchSrc [in] 源字符串
char* pchDest [out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void UnicodeToUtf8(const WCHAR* pchSrc, char* pchDest, int nDestLen );
{
if ( pchDest == NULL || pchSrc == NULL )
{
return;
}
const WCHAR* pWStrSRc = pchSrc;
int nTmplen = WideCharToMultiByte(CP_UTF8, 0, pWStrSRc, -1, NULL, 0, NULL, NULL);
char* pTemp = new char[nTmplen + 1];
memset(pTemp, 0, nTmplen + 1);
WideCharToMultiByte(CP_UTF8, 0, pWStrSRc, -1, pTemp, nTmplen + 1, NULL, NULL);
int nLen = strlen(pTemp);
if (nLen + 1 > nDestLen)
{
strncpy(pchDest, pTemp, nDestLen - 1);
pchDest[nDestLen - 1] = 0;
}
else
{
strcpy(pchDest, pTemp);
}
delete []pTemp;
}
7.3、ANSI编码与UTF8编码之间的转换
ANSI与UTF8之间是不能直接转换的,需要先转成Unicode之后才能转到目标编码。
ANSI转成UTF8的代码如下:

/*=============================================================================
函 数 名: AnsiToUtf8
功 能: 实现将char型buffer(ANSI编码)中的内容安全地拷贝到指定的char型的buffer(utf8编码)中
参 数: char* pchSrc [in] 源字符串
char* pchDest [out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void AnsiToUtf8( const char* pchSrc, char* pchDest, int nDestLen )
{
if (pchSrc == NULL || pchDest == NULL)
{
return;
}
// 先将ANSI转成Unicode
int nUnicodeBufLen = MultiByteToWideChar(CP_ACP, 0, pchSrc, -1, NULL, 0);
WCHAR* pUnicodeTmpBuf = new WCHAR[nUnicodeBufLen + 1];
memset(pUnicodeTmpBuf, 0, (nUnicodeBufLen + 1) * sizeof(WCHAR));
MultiByteToWideChar(CP_ACP, 0, pchSrc, -1, pUnicodeTmpBuf, nUnicodeBufLen + 1);
// 再将Unicode转成utf8
int nUtf8BufLen = WideCharToMultiByte(CP_UTF8, 0, pUnicodeTmpBuf, -1, NULL, 0, NULL, NULL);
char* pUtf8TmpBuf = new char[nUtf8BufLen + 1];
memset(pUtf8TmpBuf, 0, nUtf8BufLen + 1);
WideCharToMultiByte(CP_UTF8, 0, pUnicodeTmpBuf, -1, pUtf8TmpBuf, nUtf8BufLen + 1, NULL, NULL);
int nLen = strlen(pUtf8TmpBuf);
if (nLen + 1 > nDestLen)
{
strncpy(pchDest, pUtf8TmpBuf, nDestLen - 1);
pchDest[nDestLen - 1] = 0;
}
else
{
strcpy(pchDest, pUtf8TmpBuf);
}
delete[]pUtf8TmpBuf;
delete[]pUnicodeTmpBuf;
}
UTF8转成ANSI的代码如下:

/*=============================================================================
函 数 名: Utf8ToAnsi
功 能: 实现将char型buffer(utf8编码)中的内容安全地拷贝到指定的char型的buffer(ANSI编码)中
参 数: char* pchSrc [in] 源字符串
char* pchDest [out] 目标buf
int nDestLen [in] 目标buf长度(注意:以字节为单位,不是以字符个数为单位)
注 意: 无
返 回 值: 无
=============================================================================*/
void Utf8ToAnsi(const char* pchSrc, char* pchDest, int nDestLen)
{
if (pchSrc == NULL || pchDest == NULL)
{
return;
}
// 先将utf8转成Unicode
int nUnicdeBufLen = MultiByteToWideChar(CP_UTF8, 0, pchSrc, -1, NULL, 0);
WCHAR* pUnicodeTmpBuf = new WCHAR[nUnicdeBufLen + 1];
memset(pUnicodeTmpBuf, 0, (nUnicdeBufLen + 1) * sizeof(WCHAR));
MultiByteToWideChar(CP_UTF8, 0, pchSrc, -1, pUnicodeTmpBuf, nUnicdeBufLen + 1);
// 再将Unicode转成utf8
int nAnsiBuflen = WideCharToMultiByte(CP_ACP, 0, pUnicodeTmpBuf, -1, NULL, 0, NULL, NULL);
char* pAnsiTmpBuf = new char[nAnsiBuflen + 1];
memset(pAnsiTmpBuf, 0, nAnsiBuflen + 1);
WideCharToMultiByte(CP_ACP, 0, pUnicodeTmpBuf, -1, pAnsiTmpBuf, nAnsiBuflen + 1, NULL, NULL);
int nLen = strlen(pAnsiTmpBuf);
if (nLen + 1 > nDestLen)
{
strncpy(pchDest, pAnsiTmpBuf, nDestLen - 1);
pchDest[nDestLen - 1] = 0;
}
else
{
strcpy(pchDest, pTemp);
}
delete []pAnsiTmpBuf;
delete []pUnicodeTmpBuf;
}
8、Windows系统对使用ANSI窄字节字符编码的程序的兼容
现在的Windows程序基本都用Unicode字符编码了,工程属性中将字符集都设置成了Unicode字符集,代码中都使用Unicode编码的字符串。但是还有一些老的程序使用的还是ANSI窄字节的字符。那这些老的程序如何才能在外文的操作系统中正常运行呢?微软提供了一种兼容这些老程序的办法。
可以到Windows控制面板的区域语言设置中将非Unicode语言设置成程序中使用的字符语种即可,相关设置的操作步骤截图如下:
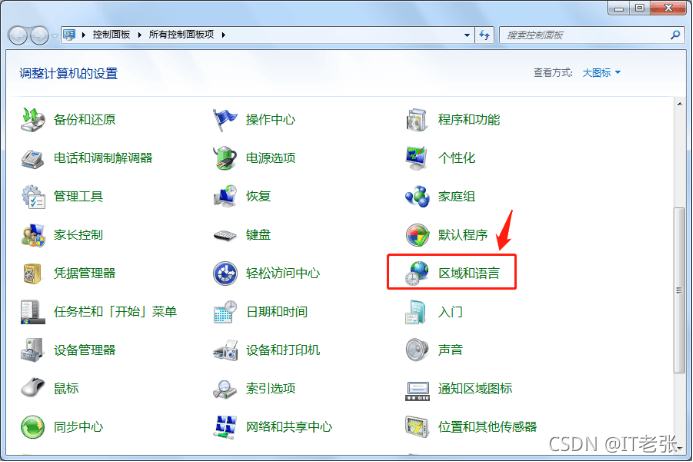


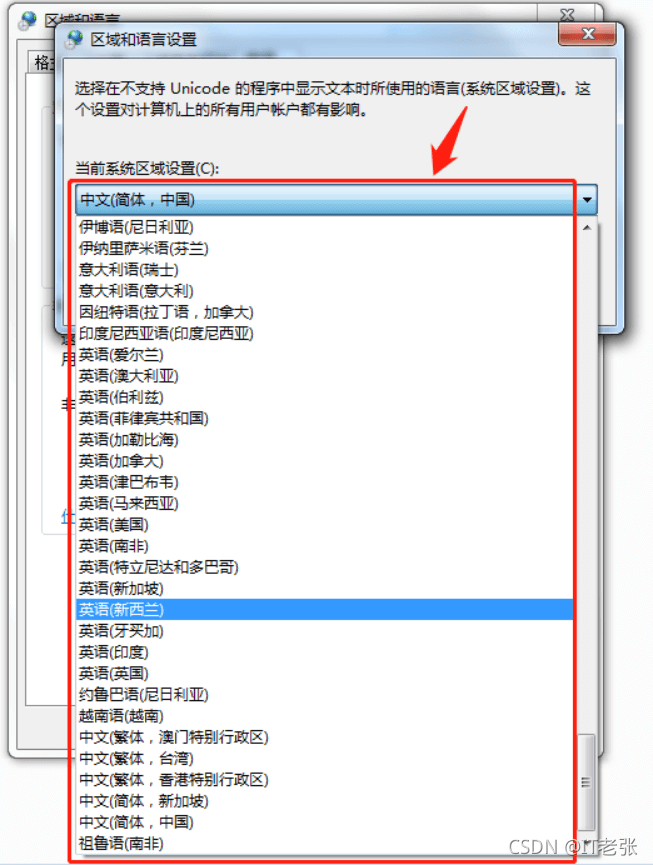
在上图中选择程序中字符使用的语种即可。
下面我们来看看使用ANSI编码的程序放到外文操作系统中运行为什么会出现乱码。假设将某程序中使用的是中文ANSI窄字节编码的字符串,放到英文操作系统中运行,默认情况下,UI界面上会显示乱码。至于为什么会显示乱码,是因为英文操作系统中默认情况下设置的非Unicode语言是英语(美国):
这个非Unicode语言设置直接影响我们调用MultiByteToWideChar和WideCharToMultiByte接口中的CP_ACP标记对应的本地ANSI字符集编码库。在上面界面中如果将非Unicode语言设置成英语(美国),则使用英文的ANSI字符编码库;如果设置成中文简体,则使用中文简体的ANSI字符集编码库。
程序中调用API函数SetWindowTextA给程序中的窗口设置文字或标题时,传入的字符串是ANSI窄字节编码的,而SetWindowTextA函数内部及底层的流程中会使用本地设置的ANSI字符集编码库将ANSI编码的字符串转成Unicode编码的字符串后再设置到窗口中,最终界面上看到的文字是Unicode编码的文字。所以在将中文字符转换成Unicode时,如果使用的是本地设置的英文字符集编码进行转换,则会出现乱码;如果使用中文简体的字符集编码进行转换,则能正常显示。
所以,要让使用中文ANSI编码字符的程序能在英文操作系统中正常显示并运行,需要将英文操作系统中区域语言设置项中的“非Unicode程序的语言”设置成中文才行。
9、字符编码导致程序启动失败的案例
几天前正好排查了一例因为字符编码导致的程序启动失败的实例,在这里简单的说一下。客户将软件安装到一个包含中文字符的路径中,点击启动软件没反应,软件始终启动不了,也没有弹出什么报错的提示框。客户于是向我们反馈了这个问题。
我们使用向日葵远程到客户的机器上,经对比发现,如果我们将软件安装到默认的C:\Program Files(X86)的英文路径下,程序是能正常启动的,所以我们初步怀疑可能是字符编码引起的问题。重新将软件安装到D盘包含中文字符的路径后,我们用windbg启动软件,刚启动windbg中就检测到看异常,异常发生在加载主程序依赖库的过程中。
启动软件的exe主程序时,会将该exe依赖的所有库依次加载到进程空间中,待所有的库都加载起来后,才会将exe主程序模块启动起来,才能看到软件的主界面。
如果在加载库时产生了异常,整个启动过程将被终止,软件也就无法启动了。
异常发生在加载音视频编解码库mediaproc.dll中,于是在windbg中输入kn命令,查看异常时的函数调用堆栈(事先已经取来了pdb符号文件)。调用堆栈显示时崩溃在mediaproc.dll库的DllMain函数中,加载dll库时都会调用到该接口。
根据调用堆栈中显示的代码行号,到编解码库的源代码中查看,发现是崩溃在一个函数接口指针的调用上,有可能是遇到空指针了。一般情况下,使用windbg实时调试时是能看到函数中的局部变量及类对象内存中的值,但这次有点特殊,看不到内存中的值。
于是和负责维护音视频编解码库的同事沟通了一下, 编解码库mediaproc.dll在DllMain中会使用绝对路径(当前exe主程序的路径)去调用LoadLibrary去动态加载更底层的库,然后调用GetProcAddress把底层库的接口都拿出来保存到指针变量中。编解码库mediaproc.dll是调用ANSI版本的API函数GetModuleFileNameA获取exe主程序的路径,问题就出在这个函数的调用上,这个函数获取的路径中包含乱码。
D盘包含中文字符的文件夹在系统中是能正常显示的,为啥获取的路径中会包含乱码呢?于是查看了客户Windows操作系统版本,是Windows10 IOT版本,经常见到旗舰版、专业版和教育版,这个IOT版本还是第一次遇到!于是又去查看控制面板区域语言中的非Unicode语言选项设置:

系统中设置的非Unicode语言为英语(美国),这样系统指向的本地ANSI字符编码库就是英语(美国)的ANSI字符编码库。
D盘中包含中文字符的文件夹在系统中能正常显示的,为啥调用GetModuleFileNameA获取到的路径中会有乱码呢?系统中显示的中文字符是Unicode编码的,当我们调用ANSI版本的GetModuleFileNameA获取路径时,GetModuleFileNameA函数内部会将Unicode编码的字符串转成ANSI编码的,转换时使用的是系统指向的本地ANSI字符编码库,也就是英语(美国)的ANSI字符编码库,而英语(美国)的ANSI字符编码库根本不识别中文字符,所以出现了乱码!
GetModuleFileNameA返回的路径中包含乱码,导致LoadLibrary失败,导致GetProcAddress返回NULL值,从而导致call这个NULL地址产生了异常!
对于当前出问题的编解码库,需要修改一下代码,需要调用Unicode版本的接口。目前临时的解决办法有两个:
1)将软件安装在英文路径中;
2)在控制面板的区域语言中将非Unicode语言改成简体中文。
我们的软件已经声称做到了对多语种的支持,虽然UI层已经支持Unicode了,但底层的库因为是不同开发团队开发维护的,需要再逐一排查一下了!
以上就是详解C++中的ANSI与Unicode和UTF8三种字符编码基本原理与相互转换的详细内容,更多关于C++ 字符编码的资料请关注我们其它相关文章!
相关推荐
-
详谈c++跨平台编码的问题
最近要将一个windows下的项目放到树莓派上,以便充分利用带宽资源,使其以夜继日的工作 在此记录一下编码问题和方案 在windows下,现在用的vs2015,创建的代码文件默认编码是ANSI,windows特有的概念,本地编码,结合实际情况就是gb232 vs在调试的时候,方便查看的有ANSI编码和unicode编码 在代码中 以"你好,world"表示ANSI编码字符串 L"hello,世界"表示unicode编码字符串 以上两种表达方式,不受代码文件本身的编码
-
C++类URL编码和解码使用技巧
在项目开发过程中,经常会使用到c++ 的url编码和解码,本文将以此问题详细介绍使用技巧,需要的朋友可以参考下 复制代码 代码如下: #pragma once #include <iostream> #include <string> #include <windows.h> using namespace std; class strCoding { public: strCoding(void); ~strCoding(void); void UTF_8ToGB23
-
C++11 Unicode编码转换
1.char16_t与char32_t 在C++98中,为了支持Unicode字符,使用wchar_t类型来表示"宽字符",但并没有严格规定位宽,而是让wchar_t的宽度由编译器实现,因此不同的编译器有着不同的实现方式,GNU C++规定wchar_t为32位,Visual C++规定为16位.由于wchar_t宽度没有一个统规定,导致使用wchar_t的代码在不同平台间移植时,可能出现问题.这一状况在C++11中得到了一定的改善,从此Unicode字符的存储有了统一类型: (1)c
-
C++实现判断一个字符串是否为UTF8或GBK格式的方法
本文实例讲述了C++实现判断一个字符串是否为UTF8或GBK格式的方法.分享给大家供大家参考,具体如下: 在处理外部数据的时候,很可能因为数据格式不一样而导致乱码,甚至导致某些程序挂掉.鉴于对多数系统来说,使用是更被广泛使用的utf8,所以判断是不是utf8格式显得很重要了. 下面是一个判断字符串是否为utf8的函数: bool is_str_utf8(const char* str) { unsigned int nBytes = 0;//UFT8可用1-6个字节编码,ASCII用一个字节 u
-
C++实现编码转换的示例代码
代码地址 https://github.com/gongluck/Code-snippet/tree/master/cpp/code%20conversion 需求 编码转换在实际开发中经常遇到,通常是ANSI.Unicode和Utf-8之间相互转换.实现也有很多种,有查表法.使用C++11.使用boost.使用系统API.C++11和boost几乎可以实现一套代码,在linux和windows都能使用,但实际会有很多坑,相当于代码几乎不改,但是要改一下系统环境.所以有一种实现就是判断系统的版本
-

详解C++中的ANSI与Unicode和UTF8三种字符编码基本原理与相互转换
目录 1.概述 2.Visual Studio中的字符编码 3.ANSI窄字节编码 4.Unicode宽字节编码 5.UTF8编码 6.如何使用字符编码 7.三种字符编码之间的相互转换(附源码) 7.1.ANSI编码与Unicode编码之间的转换 7.2.UTF8编码与Unicode编码之间的转换 7.3.ANSI编码与UTF8编码之间的转换 8.Windows系统对使用ANSI窄字节字符编码的程序的兼容 9.字符编码导致程序启动失败的案例 1.概述 在日常的软件开发过程中,会时不时地去处理不同
-
详解webpack引用jquery(第三方模块)的三种办法
前言 在使用webpack作为构建工具,开发 vue项目的时候,难免会用到 jquery这种第三方插件(毕竟都是从用jquery过来的),那么怎么引用呢?接下来我来说三种方法. 1 html 模板文件引用法,这种方法最直接也是我们最熟悉,直接在项目中的网页模板文件中加入jquery的引用即可 a.引用 b.使用 2 expose-loader 引用法 a. 安装jquery npm i jquery -D b. main.js中引用 jquery import Vue from 'vue' im
-
详解Python中的__new__、__init__、__call__三个特殊方法
__new__: 对象的创建,是一个静态方法,第一个参数是cls.(想想也是,不可能是self,对象还没创建,哪来的self) __init__ : 对象的初始化, 是一个实例方法,第一个参数是self. __call__ : 对象可call,注意不是类,是对象. 先有创建,才有初始化.即先__new__,而后__init__. 上面说的不好理解,看例子. 1.对于__new__ class Bar(object): pass class Foo(object): def __new__(cls
-
详解Linux中zip压缩和unzip解压缩命令及使用详解
下面给大家介绍下Linux中zip压缩和unzip解压缩命令详解 1.把/home目录下面的mydata目录压缩为mydata.zip zip -r mydata.zip mydata #压缩mydata目录 2.把/home目录下面的mydata.zip解压到mydatabak目录里面 unzip mydata.zip -d mydatabak 3.把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip zip -r abc123.zip abc 123.txt 4.把
-
详解Python中的编码问题(encoding与decode、str与bytes)
1 引言 在文件读写及字符操作时,我们经常会出现下面这几种错误: TypeError: write() argument must be str, not bytes AttributeError: 'URLError' object has no attribute 'code' UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' inposition 5747: illegal multibyte sequence 这些
-
详解Python中string模块除去Str还剩下什么
string模块可以追溯到早期版本的Python. 以前在本模块中实现的许多功能已经转移到str物品. 这个string模块保留了几个有用的常量和类来处理str物品. 字符串-文本常量和模板 目的:包含用于处理文本的常量和类. 功能 功能capwords()将字符串中的所有单词大写. 字符串capwords.py import string s = 'The quick brown fox jumped over the lazy dog.' print(s) print(string.capw
-
详解Python中Pygame键盘事件
Pygame事件 pygame.event.EventType ''' • 事件本质上是一种封装后的数据类型(对象) • EventType是Pygame的一个类,表示事件类型 • 事件类型只有属性,没有方法 • 用户可自定义新的事件类型 ''' 事件类型及属性 事件处理函数 键盘事件及类型的使用 键盘事件及属性 pygame.event.KEYDOWN #键盘按下事件 pygame.event.KEYUP #键盘释放事件 event.unicode #按键的unicode码,平台有关,不推荐使
-
详解mysql中的字符集和校验规则
1几种常见字符集 在MySQL中,最常见的字符集有ASCII字符集.latin字符集.GB2312字符集.GBK字符集.UTF8字符集等,下面我们简单介绍下这些字符集: ASCII字符集 这个字符集使用1个字节进行编码,一个字节具有8位,总共可以保存128个字符,具体的对应关系如下: latin字符集 latin字符集一共可以保存256个字符,相比ASCII码,它又包含了128个西欧常用字符. GB2312字符集 它包含了中文汉字.拉丁字符.希腊字符等,其中汉字占了大多数,有6763个,其他文字
-
详解Golang中字符串的使用
目录 1.字符串编码 2.字符串遍历 3.字符串中的字符数 4.字符串trim 5.字符串连接 6.字节切片转字符串 1.字符串编码 在go中rune是一个unicode编码点. 我们都知道UTF-8将字符编码为1-4个字节,比如我们常用的汉字,UTF-8编码为3个字节.所以rune也是int32的别名. type rune = int32 当我们打印一个英文字符hello的时候,我们可以得到s的长度为5,因为英文字母代表1个字节: package main import "fmt"
-
详解IE6中的position:fixed问题与随滚动条滚动的效果
详解IE6中的position:fixed问题与随滚动条滚动的效果 前言: 在<[jQuery]兼容IE6的滚动监听>(点击打开链接)提及到解决IE6fixed问题,具体是要引入一个js文件,还要声明一条脚本就为这个div声明fixed定位去解决,起始这样很不好啊.引入的Javascript不好管理之余,还要在head声明引入javascript,之后又要给这个div声明一个id,之后又要在脚本出弄一条声明,实在是烦死了. 使用position:fixed无非是想做出如下的效果. 基本上pos