SQL Server中分区表的用法
目录
- 一、分区表简介
- 二、对表分区的理由
- 三、分区表的操作步骤
- 第一步、定义分区函数:
- 第二步、定义分区构架
- 第三步、定义分区表
- 四、分区表的分割
- 五、分区表的合并
一、分区表简介
分区表是SQL Server2005新引入的概念,这个特性在逻辑上将一个表在物理上分为多个部分。(即它允许将一个表存储在不同的物理磁盘里)。在SQL Server2005之前,分区表实际上是分布式视图,也就是多个表做union操作。
分区表在逻辑上是一个表,而物理上是多个表。在用户的角度,分区表和普通表是一样的,用户角度感觉不出来。

而在SQL Server2005之前,由于没有分区的概念,所谓的分区仅仅是分布式视图:

二、对表分区的理由
表分区这个特性,只有SQL Server企业版或SQL Server开发版才有,理解表分区的概念之前,还得先理解SQL Server中文件和文件组的概念。这篇文章是解释文件和文件组的。https://www.jb51.net/article/248808.htm
表分区主要用于:
- 提供性能:这个是大多人数分区的目的,把一个表分部到不同的硬盘或其他存储介质中,会大大提升查询速度。
- 提高稳定性:当一个分区出了问题,不会影响其他分区,仅仅是当前坏的分区不可用。
- 便于管理:把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区。
- 存档:将一些不太常用的数据,单独存放。如:将1年前的数据记录分到一个专门的存档服务器存放。
三、分区表的操作步骤
分区表分为三个步骤:
- 定义分区函数
定义分区构架
定义分区表
分区函数,分区构架和分区表的关系如下:分区表依赖于分区构架,分区构架又依赖分区函数。

因此,定义分区表的顺序基本上是定义分区函数->定义分区构架->定义分区表。
实际操作,先定义一张需要分区的表:

我们以SalesDate列作为分区列。
第一步、定义分区函数:
分区函数用于判断一行数据属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区。
如上面的分区表,可以通过设置SalesDate的值来判定其不同的分区,假如我们定义了SalesDate的两个边界值进行分区,则会生成三个分区,现在设置两个边界值分别为2004-01-01和2007-01-01,则上面的表就可以根据这两个边界值分出三个分区。

定义分区函数的语法如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
在上面定义分区函数的原型语法中,我们看到其中并没有涉及到具体的表,因为分区函数并不和具体的表绑定。
另外原型中还可以看到Range left和right,这个参数决定临界值(也就是刚好等于2004-01-01或2007-01-01的这些与分界值相等的值)应该归于左边还是右边。
创建分区函数:
--创建分区函数
CREATE PARTITION FUNCTION fnPartition(DATE)
AS RANGE RIGHT
FOR VALUES('2004-01-01','2007-01-01')
--查看分区表是否创建成功
SELECT * FROM sys.partition_functions
上述查询语句显示结果如下:

通过系统视图,可以看见这个分区函数已经创建成功。
第二步、定义分区构架
定义完分区函数仅仅知道了根据列的值将数据分配到不同的分区。而每个分区的存储方式,则需要分区构架来定义。
分区构架语法原型:
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
从原型来看,分区构架仅仅是依赖分区函数。分区构架负责分配每个区属于哪个文件组,而分区函数是决定哪条数据属于哪个分区。
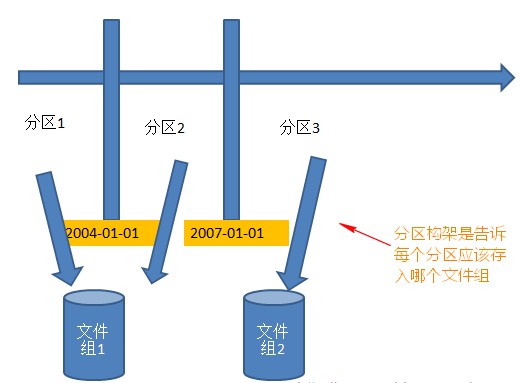
基于之前创建的分区函数,创建分区构架:
--基于之前的分区函数创建分区构架schema CREATE PARTITION SCHEME SchemaForParirion AS PARTITION fnPartition --这个是之前创建的分区函数 TO(FileGroup1,[primary],FileGroup1) --FileGroup1是自己添加的文件组,因为有两个分界值,3个分区,所以要指定3个文件组,也可以使用ALL所谓的分区指向一个文件组 --查看已创建的分区构架 SELECT * FROM sys.partition_schemes
以上SELECT语句输出结果如下:

留意到分区构架已成功创建。
第三步、定义分区表
有了分区函数与分区构架,下面就可以创建分区表了,表在创建的时候就要决定是否是分区表了。
虽然在大部分情况下,都是在发现表太大时,才想到要分区。但是分区表只能够在创建的时候指定为分区表。
CREATE TABLE OrderRecords
(
Id int,
OrderId int,
SalesDate Date
)
ON SchemaForParirion(SalesDate) --SchemaForPartition是刚刚定义的分区架构,括号内为指定的分区列
然后手工向数据库里面添加3条数据:

然后执行查询:
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps
on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2
on dds.data_space_id = ds2.data_space_id
join sys.partitions p
on dds.destination_id = p.partition_number
and p.object_id = i.object_id
and p.index_id = i.index_id
join sys.partition_functions pf
on ps.function_id = pf.function_id
left join sys.partition_range_values v
on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
where i.object_id = object_id('OrderRecords') --此处是表名
and i.index_id in ( 0, 1 )
order by p.partition_number
可以看到,分区起作用了:

四、分区表的分割
分区表的分割,相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容。
新加入多一个分割点:2009-01-01。如下图所示:

对于上图的操作,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应的数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区3内的内容,造成分区3的内容暂时不可用。而且,这个操作生成的日志内容将会是被转移数据的4倍。
因此,最好在建表的时候,就要考虑到以后的分割点,比如预判到2014-01-01,2016-01-01。
分割现有的分区需要两个步骤:
- 首先要告诉SQL Server新建立的分区放到哪个文件组
- 建立新的分割点。
加一条数据,致使原表如下:

执行那个长查询,显示如下:

现在,可以执行分割操作了:
--分割出来的分区数据存在在哪个文件组
ALTER PARTITION SCHEME SchemaForParirion
NEXT USED 'PRIMARY'
--添加分割点
ALTER PARTITION FUNCTION fnPartition()
SPLIT RANGE('2009-01-01')
执行完之后,再看结果如下:

五、分区表的合并
分区的合并可以旱作是分区分割的逆操作。分区的合并需要提供分割点,并且这个分割点必须在现有的分割表中已经存在,否则进行合并时就会报错。
例如,对以上例子,根据2009-01-01来进行合并:

合并分区操作:
--提供分割点,合并分区
ALTER PARTITION FUNCTION fnPartition()
MERGE RANGE('2009-01-01')
再来看分区信息:

在这里应该注意到一个问题,假设已经合并了分区,那么合并之后,文件是存在分区3的文件组呢,还是分区4的文件组呢?这个取决于我们刚开始时定义的分区函数是left还是right。
如果定义的是left,则左边的分区3合并到分区4。如果是right,则右边的分区4合并到分区3.

到此这篇关于SQL Server分区表的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

SQL SERVER使用表分区优化性能
目录 1.简介 2.表分区 2.1分区范围 2.2分区键 2.3索引分区 3.创建表分区 3.1创建文件组 3.2指定文件组存放路径 3.3创建分区函数 3.4创建分区方案 3.5创建分区表 3.6创建分区索引 4.表分区的优缺点 1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护
-
SQL server 2005的表分区
下面来说下,在SQL SERVER 2005的表分区里,如何对已经存在的有数据的表进行分区,其实道理和之前在http://www.cnblogs.com/jackyrong/archive/2006/11/13/559354.html说到一样,只不过交换下顺序而已,下面依然用例子说明: 依然在c盘的data2目录下建立4个文件夹,用来做4个文件组,然后建立数据库 use masterIF EXISTS (SELECT name FROM sys.databases WHERE name =
-
SQL Server 数据库分区分表(水平分表)详细步骤
1. 需求说明 将数据库Demo中的表按照日期字段进行水平分区分表.要求数据文件按一年一个文件存储,且分区的分割点会根据时间的增长自动添加(例如现在是2017年1月1日,将其作为一个分割点,即将2017年1月1日之前的数据存储到数据文件A中,将2017年1月1日的之后的数据存储到数据文件B中:当时间到2018年1月1日时,自动将2018年1月1日添加为一个新的分区分割点,并将2017年1月1日至2018年1月1日的数据存储在数据文件B中,将2018年1月1日之后的数据存储在一个新的数据文件C中,
-
SQL Server根据分区表名查找所在的文件及文件组实现脚本
SELECT ps.name AS PSName, dds.destination_idAS PartitionNumber, fg.name AS FileGroupName,fg.name, t.name, f.name as filename FROM (((sys.tables AS t INNER JOIN sys.indexes AS i ON (t.object_id = i.object_id)) INNER JOIN sys.partition_schemes AS ps ON
-
SQLSERVER 表分区操作和设计方法
一 .聚集索引 聚集索引的页级别包含了索引键,还包含数据页,因此,关于 除了键值以外聚集索引的叶级别还存放了什么的答案就是一切,也就是说,每行的所有字段都在叶级别种.另一种说话是:数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序.SQL SERVER 中,所有的聚集索引都是唯一的,如果在创建聚集索引时没有指定UNIQUE 关键字,SQL SERVER 会在需要时通过往记录中添加一个唯一标识符(Uniqueifier)在内部保证索引的唯一性,该唯一标识符是一个4字节的值,作为附加在
-
SQL Server表分区删除详情
目录 一.引言 二.演示 2.1.数据查询 2.1.1. 查看分区元数据 2.1.2.统计每个分区的数据量 2.2.删除实操 2.2.1.合并原表分区 2.2.2.备份原表所有索引的创建脚本 2.2.3.删除原表所有索引 2.2.4.创建临时表 2.2.5.更改原表数据空间类型 2.2.6.移动原表分区数据到临时表 2.2.7.创建原表所有索引 到临时表 2.2.8.删除原表 2.2.9.删除分区方案和分区函数 2.2.10重命名表名 一.引言 删除分区又称为合并分区,简单地讲就是将多个分区的数
-
SQL Server中分区表的用法
目录 一.分区表简介 二.对表分区的理由 三.分区表的操作步骤 第一步.定义分区函数: 第二步.定义分区构架 第三步.定义分区表 四.分区表的分割 五.分区表的合并 一.分区表简介 分区表是SQL Server2005新引入的概念,这个特性在逻辑上将一个表在物理上分为多个部分.(即它允许将一个表存储在不同的物理磁盘里).在SQL Server2005之前,分区表实际上是分布式视图,也就是多个表做union操作. 分区表在逻辑上是一个表,而物理上是多个表.在用户的角度,分区表和普通表是一样的,用户
-
SQL Server 中 RAISERROR 的用法详细介绍
SQL Server 中 RAISERROR 的用法 raiserror 的作用: raiserror 是用于抛出一个错误.[ 以下资料来源于sql server 2005的帮助 ] 其语法如下: RAISERROR ( { msg_id | msg_str | @local_variable } { ,severity ,state } [ ,argument [ ,...n ] ] ) [ WITH option [ ,...n ] ] 简要说明一下: 第一个参数:{ msg_id | ms
-
SQL Server中Sequence对象用法
一.Sequence简介 Sequence对象对于Oracle用户来说是最熟悉不过的数据库对象了, 在SQL SERVER2012终于也可以看到这个对象了.Sequence是SQL Server2012推出的一个新特性.这个特性允许数据库级别的序列号在多表或多列之间共享. 二.Sequence基本概念 Oracle中有Sequence的功能,SQL server类似的功能要使用identity列实现,但是identity列有很大的局限性.微软终于在2012中添加了Sequence对象.与以往id
-
SQL Server中row_number函数用法入门介绍
目录 一.SQL Server Row_number函数简介 二.Row_number函数的具体用法 1.使用row_number()函数对结果集进行编号 2.对结果集按照指定列进行分组,并在组内按照指定列排序 3.对结果集按照指定列去重 总结 一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 语法实例: select *,row_number() over(
-
SQL Server中锁的用法
目录 通过锁可以防止的问题 1.脏读 2.非重复性读取 3.幻读 4.丢失更新 可以锁定的资源 锁升级和锁对性能的影响 锁定模式 1.共享锁 2.排它锁 3.更新锁 4.意向锁 5.模式锁 6.批量更新锁 锁的兼容性 使用Management Studio确定锁 设置隔离级别 1.READ COMMITTED 2.READ UNCOMMITTED 3.REPEATABLE READ 4.SERIALIZABLE 5.SNAPSHOT 处理死锁 1.判断死锁的方式 2.选择死锁牺牲者的方式 3.避
-
SQL Server中索引的用法详解
目录 一.索引的介绍 什么是索引? 1.聚集索引和非聚集索引 2.索引的利弊 3.索引的存储机制 二.设置索引的权衡 1.什么情况下设置索引 2.什么情况下不要设置索引 三.聚集索引 1.使用SSMS创建聚集索引 2.使用T-SQL创建聚集索引 四.非聚集索引 1.SSMS创建方法同上,T-SQL创建方法如下: 2.添加索引选项 五.示例 六.管理索引 一.索引的介绍 什么是索引? 索引是一种磁盘上的数据结构,建立在表或视图的基础上.使用索引可以使数据的获取更快更高校,也会影响其他的一些性能,如
-
SQL Server中row_number分页查询的用法详解
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号.在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号. ROW_NUMBER() 说明:返回结果集分区内行的序列号,每个分区的第一行从1开始. 语法:ROW_NUMBER () OVER ([ <partition_by_clause> ] <order_by_clause>) . 备注:ORDER
-
Sql Server中Substring函数的用法实例解析
SQL 中的 substring 函数是用来抓出一个栏位资料中的其中一部分.这个函数的名称在不同的资料库中不完全一样: MySQL: SUBSTR( ), SUBSTRING( ) Oracle: SUBSTR( ) SQL Server: SUBSTRING( ) SQL 中的 substring 函数是用来截取一个栏位资料中的其中一部分. 例如,我们需要将字符串'abdcsef'中的'abd'给提取出来,则可用substring 来实现: select substring('abdcsef'
-
SQL Server中row_number函数的常见用法示例详解
一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 以下是ROW_NUMBER()函数的语法实例: select *,row_number() over(partition by column1 order by column2) as n from tablename 在上面语法中: PARTITION BY子句将结果集划分为分区. ROW_NUMBER()函
-
SQL Server中identity(自增)的用法详解
一.identity的基本用法 1.含义 identity表示该字段的值会自动更新,不需要我们维护,通常情况下我们不可以直接给identity修饰的字符赋值,否则编译时会报错 2.语法 列名 数据类型 约束 identity(m,n) m表示的是初始值,n表示的是每次自动增加的值 如果m和n的值都没有指定,默认为(1,1) 要么同时指定m和n的值,要么m和n都不指定,不能只写其中一个值,不然会出错 3.实例演示 不指定m和n的值 create table student1 ( sid int p